 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Prototype Semantic Decoupling for Text-Based Person Search in Full Images
May 07, 2025Text-based pedestrian search (TBPS) in full images aims to locate a target pedestrian in untrimmed images using natural language descriptions. However, in complex scenes with multiple pedestrians, existing methods are limited by uncertainties in detection and matching, leading to degraded performance. To address this, we propose UPD-TBPS, a novel framework comprising three modules: Multi-granularity Uncertainty Estimation (MUE), Prototype-based Uncertainty Decoupling (PUD), and Cross-modal Re-identification (ReID). MUE conducts multi-granularity queries to identify potential targets and assigns confidence scores to reduce early-stage uncertainty. PUD leverages visual context decoupling and prototype mining to extract features of the target pedestrian described in the query. It separates and learns pedestrian prototype representations at both the coarse-grained cluster level and the fine-grained individual level, thereby reducing matching uncertainty. ReID evaluates candidates with varying confidence levels, improving detection and retrieval accuracy. Experiments on CUHK-SYSU-TBPS and PRW-TBPS datasets validate the effectiveness of our framework.
Patient-Level Anatomy Meets Scanning-Level Physics: Personalized Federated Low-Dose CT Denoising Empowered by Large Language Model
Mar 02, 2025Reducing radiation doses benefits patients, however, the resultant low-dose computed tomography (LDCT) images often suffer from clinically unacceptable noise and artifacts. While deep learning (DL) shows promise in LDCT reconstruction, it requires large-scale data collection from multiple clients, raising privacy concerns. Federated learning (FL) has been introduced to address these privacy concerns; however, current methods are typically tailored to specific scanning protocols, which limits their generalizability and makes them less effective for unseen protocols. To address these issues, we propose SCAN-PhysFed, a novel SCanning- and ANatomy-level personalized Physics-Driven Federated learning paradigm for LDCT reconstruction. Since the noise distribution in LDCT data is closely tied to scanning protocols and anatomical structures being scanned, we design a dual-level physics-informed way to address these challenges. Specifically, we incorporate physical and anatomical prompts into our physics-informed hypernetworks to capture scanning- and anatomy-specific information, enabling dual-level physics-driven personalization of imaging features. These prompts are derived from the scanning protocol and the radiology report generated by a medical large language model (MLLM), respectively. Subsequently, client-specific decoders project these dual-level personalized imaging features back into the image domain. Besides, to tackle the challenge of unseen data, we introduce a novel protocol vector-quantization strategy (PVQS), which ensures consistent performance across new clients by quantifying the unseen scanning code as one of the codes in the scanning codebook. Extensive experimental results demonstrate the superior performance of SCAN-PhysFed on public datasets.
Plaintext-Free Deep Learning for Privacy-Preserving Medical Image Analysis via Frequency Information Embedding
Mar 25, 2024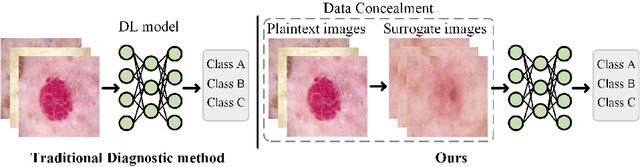
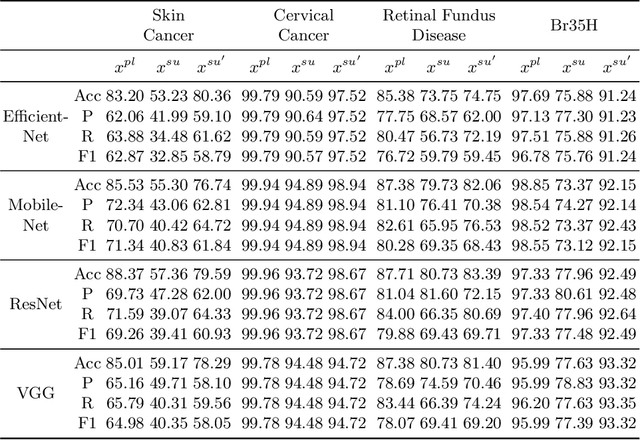
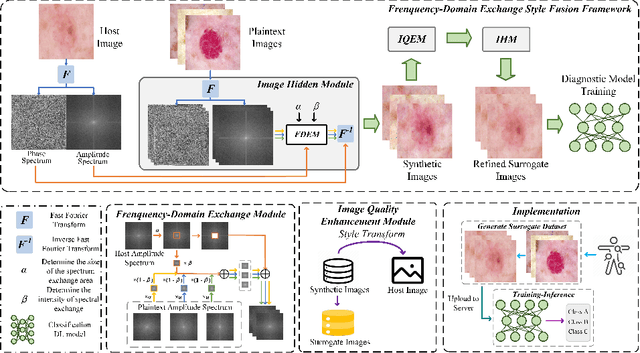
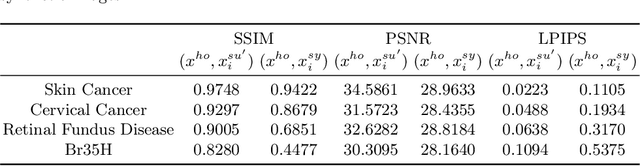
In the fast-evolving field of medical image analysis, Deep Learning (DL)-based methods have achieved tremendous success. However, these methods require plaintext data for training and inference stages, raising privacy concerns, especially in the sensitive area of medical data. To tackle these concerns, this paper proposes a novel framework that uses surrogate images for analysis, eliminating the need for plaintext images. This approach is called Frequency-domain Exchange Style Fusion (FESF). The framework includes two main components: Image Hidden Module (IHM) and Image Quality Enhancement Module~(IQEM). The~IHM performs in the frequency domain, blending the features of plaintext medical images into host medical images, and then combines this with IQEM to improve and create surrogate images effectively. During the diagnostic model training process, only surrogate images are used, enabling anonymous analysis without any plaintext data during both training and inference stages. Extensive evaluations demonstrate that our framework effectively preserves the privacy of medical images and maintains diagnostic accuracy of DL models at a relatively high level, proving its effectiveness across various datasets and DL-based models.
ReCo-Diff: Explore Retinex-Based Condition Strategy in Diffusion Model for Low-Light Image Enhancement
Dec 20, 2023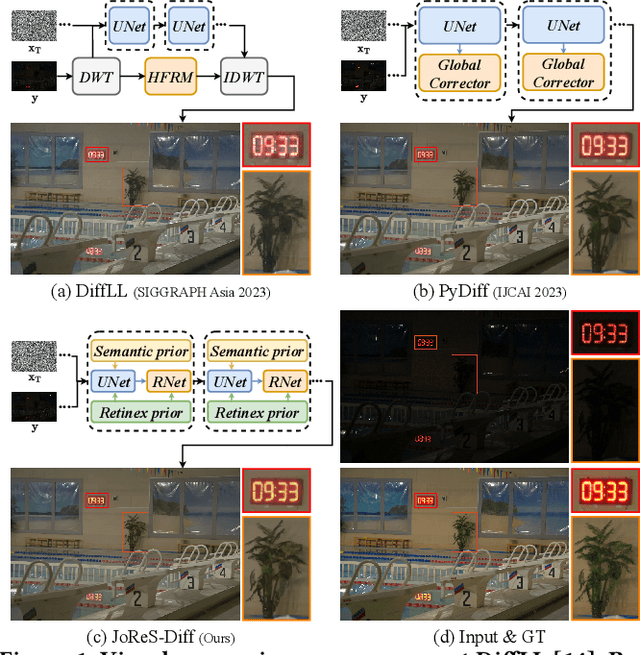
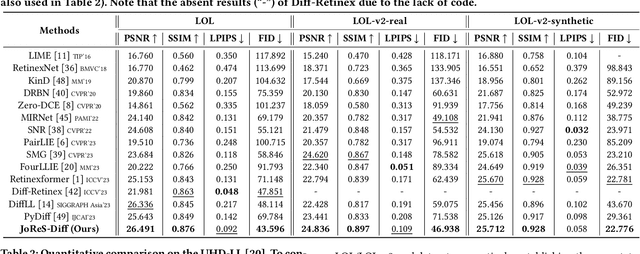
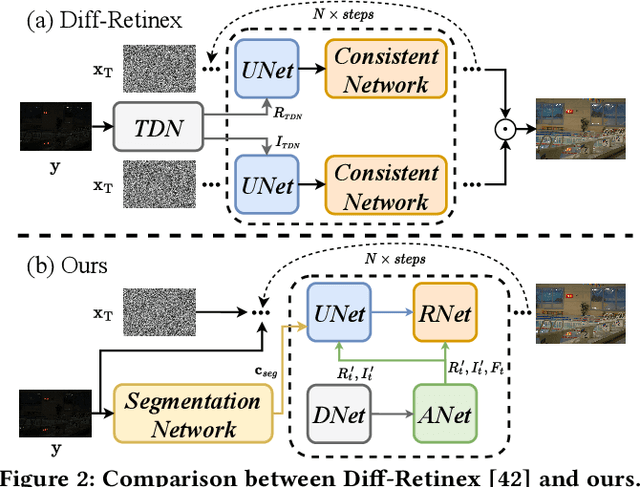
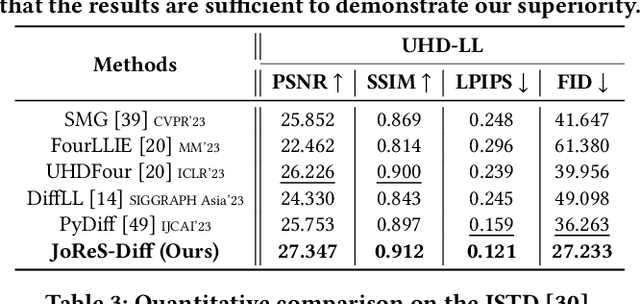
Low-light image enhancement (LLIE) has achieved promising performance by employing conditional diffusion models. In this study, we propose ReCo-Diff, a novel approach that incorporates Retinex-based prior as an additional pre-processing condition to regulate the generating capabilities of the diffusion model. ReCo-Diff first leverages a pre-trained decomposition network to produce initial reflectance and illumination maps of the low-light image. Then, an adjustment network is introduced to suppress the noise in the reflectance map and brighten the illumination map, thus forming the learned Retinex-based condition. The condition is integrated into a refinement network, implementing Retinex-based conditional modules that offer sufficient guidance at both feature- and image-levels. By treating Retinex theory as a condition, ReCo-Diff presents a unique perspective for establishing an LLIE-specific diffusion model. Extensive experiments validate the rationality and superiority of our ReCo-Diff approach. The code will be made publicly available.
Privacy-Preserving Encrypted Low-Dose CT Denoising
Oct 13, 2023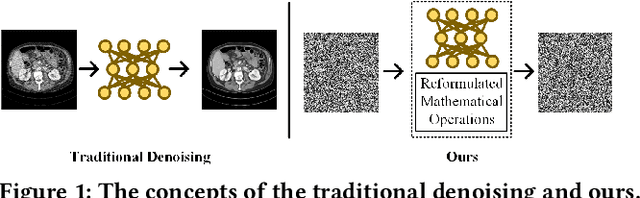

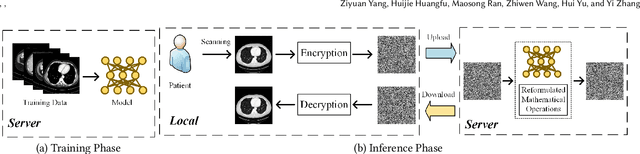
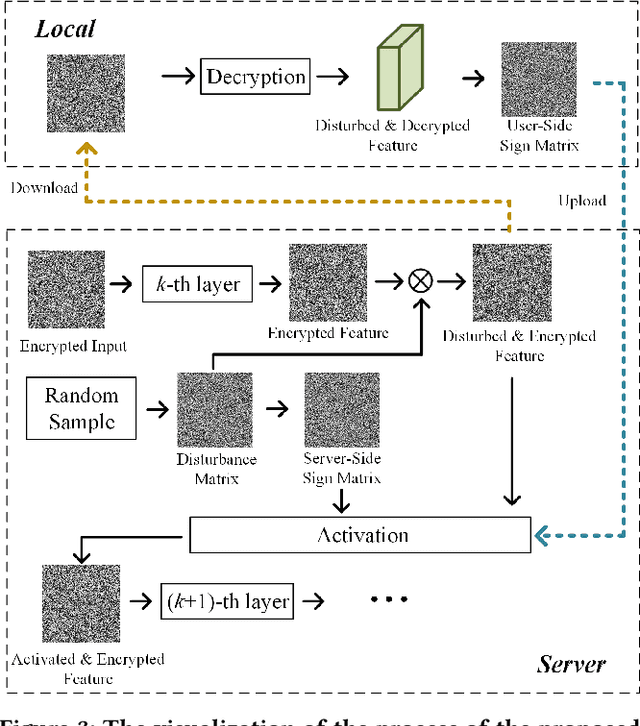
Deep learning (DL) has made significant advancements in tomographic imaging, particularly in low-dose computed tomography (LDCT) denoising. A recent trend involves servers training powerful models with large amounts of self-collected private data and providing application programming interfaces (APIs) for users, such as Chat-GPT. To avoid model leakage, users are required to upload their data to the server model, but this way raises public concerns about the potential risk of privacy disclosure, especially for medical data. Hence, to alleviate related concerns, in this paper, we propose to directly denoise LDCT in the encrypted domain to achieve privacy-preserving cloud services without exposing private data to the server. To this end, we employ homomorphic encryption to encrypt private LDCT data, which is then transferred to the server model trained with plaintext LDCT for further denoising. However, since traditional operations, such as convolution and linear transformation, in DL methods cannot be directly used in the encrypted domain, we transform the fundamental mathematic operations in the plaintext domain into the operations in the encrypted domain. In addition, we present two interactive frameworks for linear and nonlinear models in this paper, both of which can achieve lossless operating. In this way, the proposed methods can achieve two merits, the data privacy is well protected and the server model is free from the risk of model leakage. Moreover, we provide theoretical proof to validate the lossless property of our framework. Finally, experiments were conducted to demonstrate that the transferred contents are well protected and cannot be reconstructed. The code will be released once the paper is accepted.
Solving multiscale elliptic problems by sparse radial basis function neural networks
Sep 01, 2023



Machine learning has been successfully applied to various fields of scientific computing in recent years. In this work, we propose a sparse radial basis function neural network method to solve elliptic partial differential equations (PDEs) with multiscale coefficients. Inspired by the deep mixed residual method, we rewrite the second-order problem into a first-order system and employ multiple radial basis function neural networks (RBFNNs) to approximate unknown functions in the system. To aviod the overfitting due to the simplicity of RBFNN, an additional regularization is introduced in the loss function. Thus the loss function contains two parts: the $L_2$ loss for the residual of the first-order system and boundary conditions, and the $\ell_1$ regularization term for the weights of radial basis functions (RBFs). An algorithm for optimizing the specific loss function is introduced to accelerate the training process. The accuracy and effectiveness of the proposed method are demonstrated through a collection of multiscale problems with scale separation, discontinuity and multiple scales from one to three dimensions. Notably, the $\ell_1$ regularization can achieve the goal of representing the solution by fewer RBFs. As a consequence, the total number of RBFs scales like $\mathcal{O}(\varepsilon^{-n\tau})$, where $\varepsilon$ is the smallest scale, $n$ is the dimensionality, and $\tau$ is typically smaller than $1$. It is worth mentioning that the proposed method not only has the numerical convergence and thus provides a reliable numerical solution in three dimensions when a classical method is typically not affordable, but also outperforms most other available machine learning methods in terms of accuracy and robustness.
EVIL: Evidential Inference Learning for Trustworthy Semi-supervised Medical Image Segmentation
Jul 18, 2023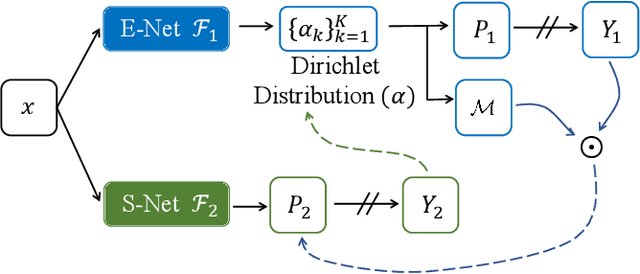
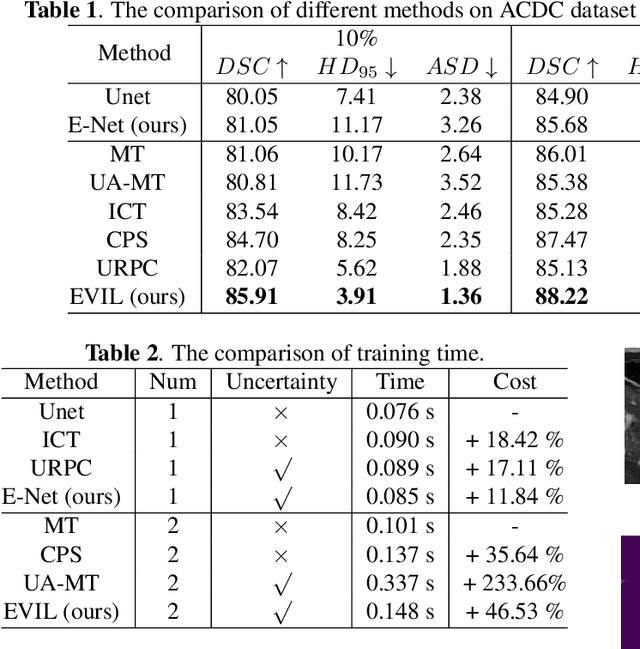

Recently, uncertainty-aware methods have attracted increasing attention in semi-supervised medical image segmentation. However, current methods usually suffer from the drawback that it is difficult to balance the computational cost, estimation accuracy, and theoretical support in a unified framework. To alleviate this problem, we introduce the Dempster-Shafer Theory of Evidence (DST) into semi-supervised medical image segmentation, dubbed Evidential Inference Learning (EVIL). EVIL provides a theoretically guaranteed solution to infer accurate uncertainty quantification in a single forward pass. Trustworthy pseudo labels on unlabeled data are generated after uncertainty estimation. The recently proposed consistency regularization-based training paradigm is adopted in our framework, which enforces the consistency on the perturbed predictions to enhance the generalization with few labeled data. Experimental results show that EVIL achieves competitive performance in comparison with several state-of-the-art methods on the public dataset.
Target-Aware Tracking with Long-term Context Attention
Feb 27, 2023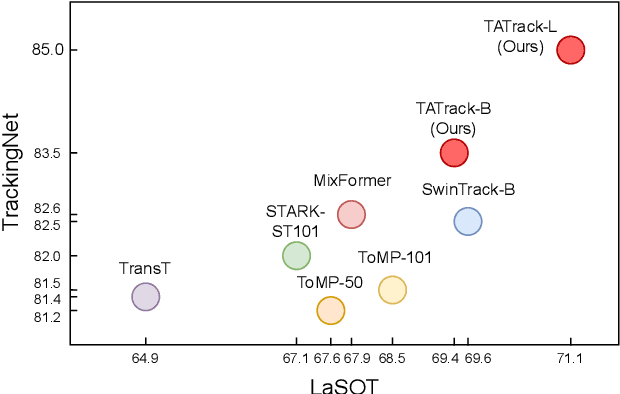
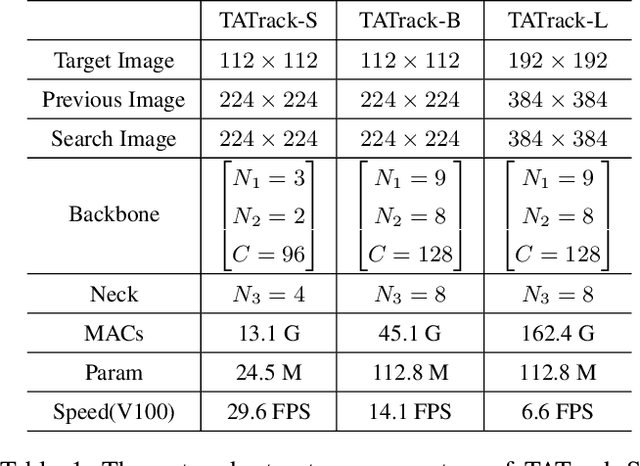
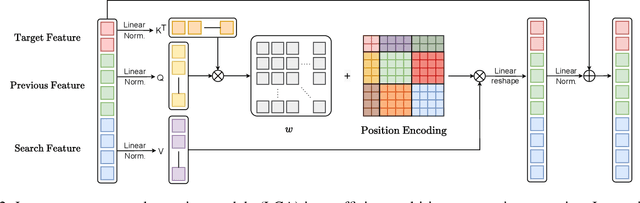
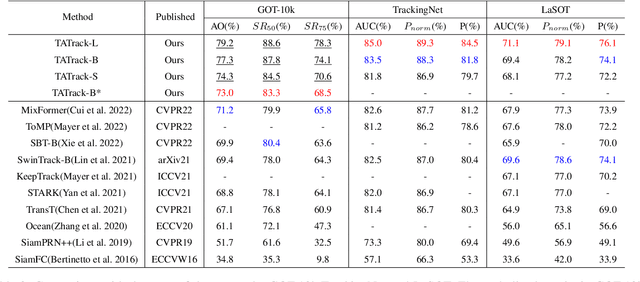
Most deep trackers still follow the guidance of the siamese paradigms and use a template that contains only the target without any contextual information, which makes it difficult for the tracker to cope with large appearance changes, rapid target movement, and attraction from similar objects. To alleviate the above problem, we propose a long-term context attention (LCA) module that can perform extensive information fusion on the target and its context from long-term frames, and calculate the target correlation while enhancing target features. The complete contextual information contains the location of the target as well as the state around the target. LCA uses the target state from the previous frame to exclude the interference of similar objects and complex backgrounds, thus accurately locating the target and enabling the tracker to obtain higher robustness and regression accuracy. By embedding the LCA module in Transformer, we build a powerful online tracker with a target-aware backbone, termed as TATrack. In addition, we propose a dynamic online update algorithm based on the classification confidence of historical information without additional calculation burden. Our tracker achieves state-of-the-art performance on multiple benchmarks, with 71.1\% AUC, 89.3\% NP, and 73.0\% AO on LaSOT, TrackingNet, and GOT-10k. The code and trained models are available on https://github.com/hekaijie123/TATrack.
One Network to Solve Them All: A Sequential Multi-Task Joint Learning Network Framework for MR Imaging Pipeline
May 14, 2021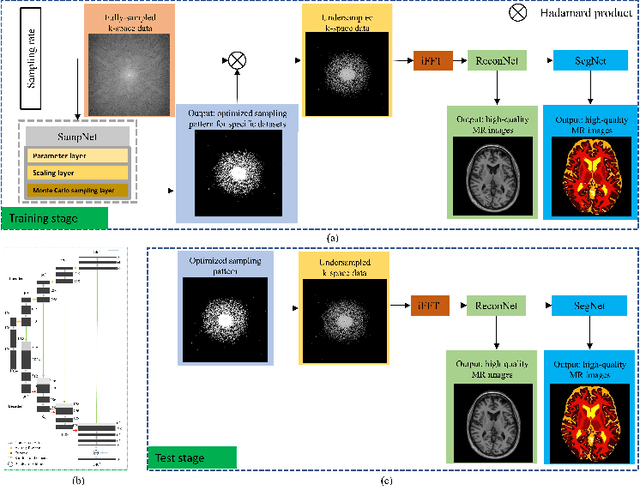
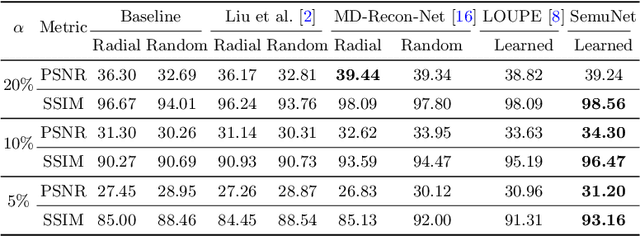
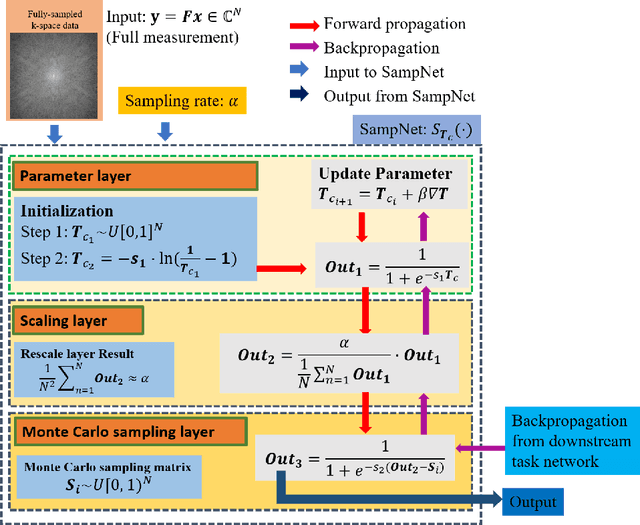
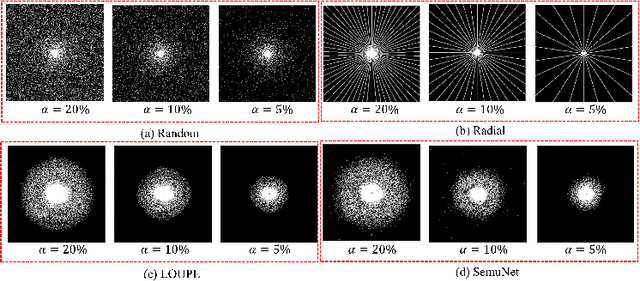
Magnetic resonance imaging (MRI) acquisition, reconstruction, and segmentation are usually processed independently in the conventional practice of MRI workflow. It is easy to notice that there are significant relevances among these tasks and this procedure artificially cuts off these potential connections, which may lead to losing clinically important information for the final diagnosis. To involve these potential relations for further performance improvement, a sequential multi-task joint learning network model is proposed to train a combined end-to-end pipeline in a differentiable way, aiming at exploring the mutual influence among those tasks simultaneously. Our design consists of three cascaded modules: 1) deep sampling pattern learning module optimizes the $k$-space sampling pattern with predetermined sampling rate; 2) deep reconstruction module is dedicated to reconstructing MR images from the undersampled data using the learned sampling pattern; 3) deep segmentation module encodes MR images reconstructed from the previous module to segment the interested tissues. The proposed model retrieves the latently interactive and cyclic relations among those tasks, from which each task will be mutually beneficial. The proposed framework is verified on MRB dataset, which achieves superior performance on other SOTA methods in terms of both reconstruction and segmentation.