 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
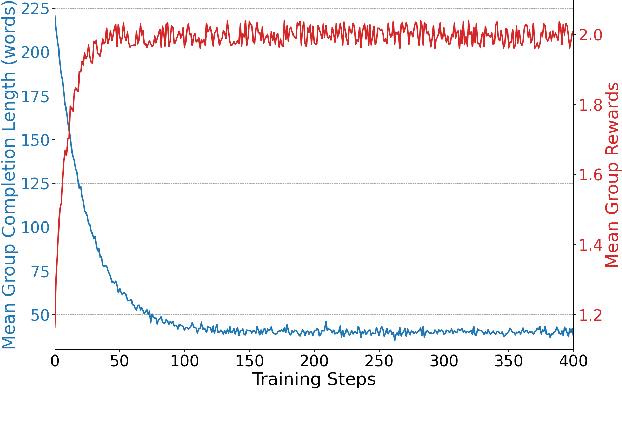
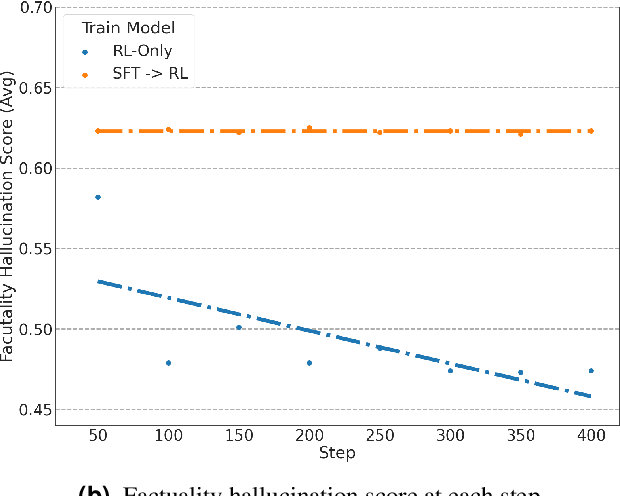
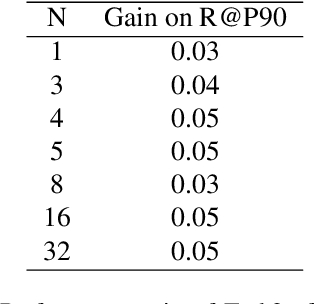
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
Robust Duality Learning for Unsupervised Visible-Infrared Person Re-Identfication
May 05, 2025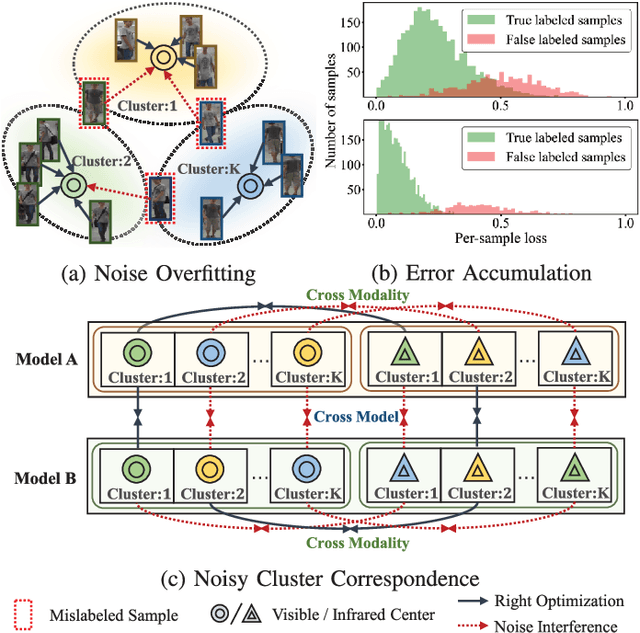
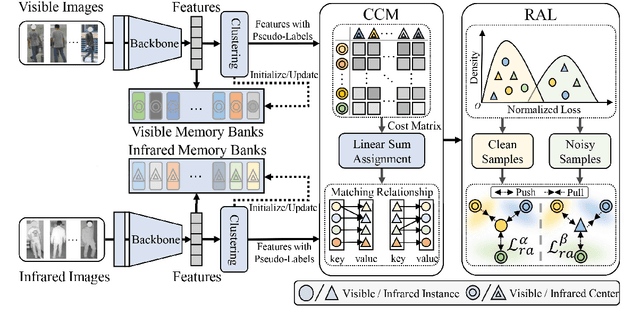
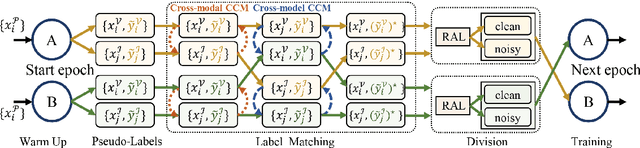
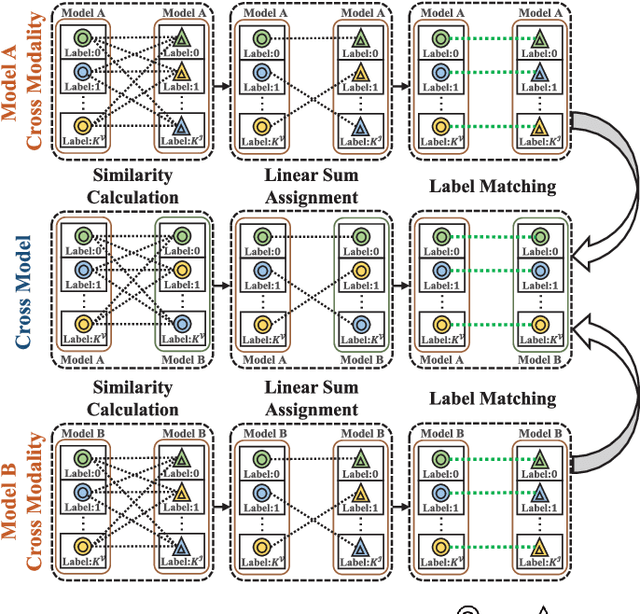
Unsupervised visible-infrared person re-identification (UVI-ReID) aims to retrieve pedestrian images across different modalities without costly annotations, but faces challenges due to the modality gap and lack of supervision. Existing methods often adopt self-training with clustering-generated pseudo-labels but implicitly assume these labels are always correct. In practice, however, this assumption fails due to inevitable pseudo-label noise, which hinders model learning. To address this, we introduce a new learning paradigm that explicitly considers Pseudo-Label Noise (PLN), characterized by three key challenges: noise overfitting, error accumulation, and noisy cluster correspondence. To this end, we propose a novel Robust Duality Learning framework (RoDE) for UVI-ReID to mitigate the effects of noisy pseudo-labels. First, to combat noise overfitting, a Robust Adaptive Learning mechanism (RAL) is proposed to dynamically emphasize clean samples while down-weighting noisy ones. Second, to alleviate error accumulation-where the model reinforces its own mistakes-RoDE employs dual distinct models that are alternately trained using pseudo-labels from each other, encouraging diversity and preventing collapse. However, this dual-model strategy introduces misalignment between clusters across models and modalities, creating noisy cluster correspondence. To resolve this, we introduce Cluster Consistency Matching (CCM), which aligns clusters across models and modalities by measuring cross-cluster similarity. Extensive experiments on three benchmarks demonstrate the effectiveness of RoDE.
SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL
Feb 17, 2025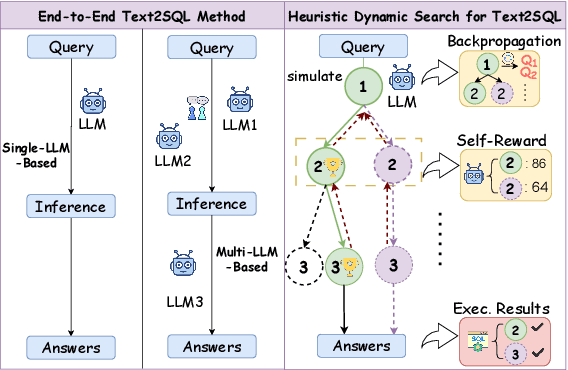


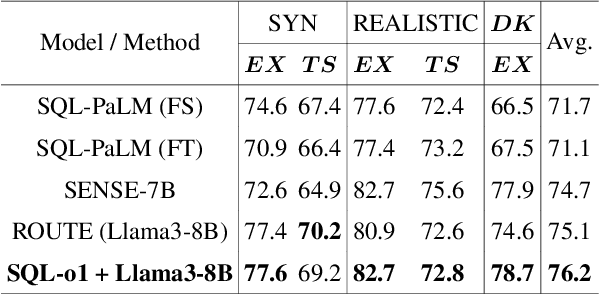
The Text-to-SQL(Text2SQL) task aims to convert natural language queries into executable SQL queries. Thanks to the application of large language models (LLMs), significant progress has been made in this field. However, challenges such as model scalability, limited generation space, and coherence issues in SQL generation still persist. To address these issues, we propose SQL-o1, a Self-Reward-based heuristic search method designed to enhance the reasoning ability of LLMs in SQL query generation. SQL-o1 combines Monte Carlo Tree Search (MCTS) for heuristic process-level search and constructs a Schema-Aware dataset to help the model better understand database schemas. Extensive experiments on the Bird and Spider datasets demonstrate that SQL-o1 improves execution accuracy by 10.8\% on the complex Bird dataset compared to the latest baseline methods, even outperforming GPT-4-based approaches. Additionally, SQL-o1 excels in few-shot learning scenarios and shows strong cross-model transferability. Our code is publicly available at:https://github.com/ShuaiLyu0110/SQL-o1.
HGTUL: A Hypergraph-based Model For Trajectory User Linking
Feb 11, 2025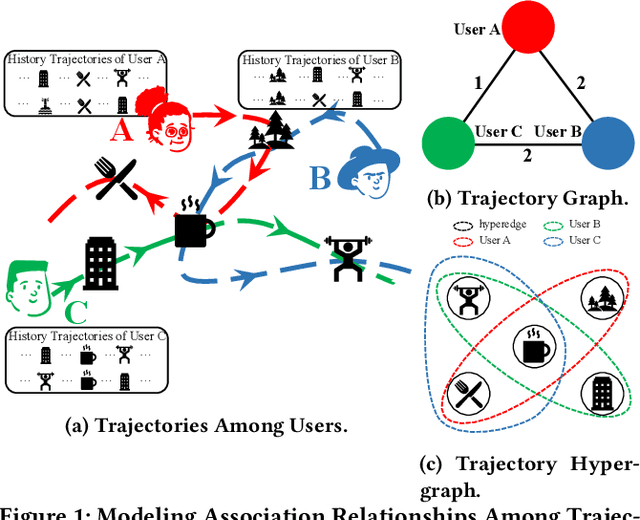
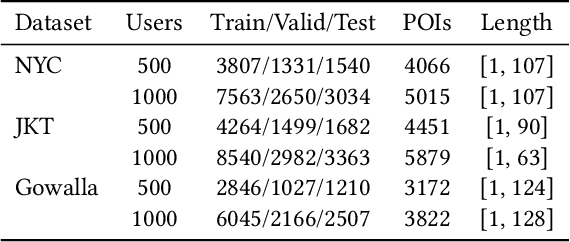
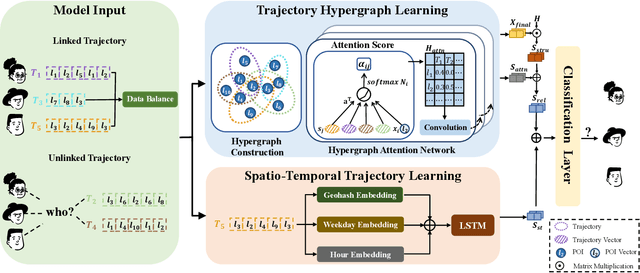

Trajectory User Linking (TUL), which links anonymous trajectories with users who generate them, plays a crucial role in modeling human mobility. Despite significant advancements in this field, existing studies primarily neglect the high-order inter-trajectory relationships, which represent complex associations among multiple trajectories, manifested through multi-location co-occurrence patterns emerging when trajectories intersect at various Points of Interest (POIs). Furthermore, they also overlook the variable influence of POIs on different trajectories, as well as the user class imbalance problem caused by disparities in user activity levels and check-in frequencies. To address these limitations, we propose a novel HyperGraph-based multi-perspective Trajectory User Linking model (HGTUL). Our model learns trajectory representations from both relational and spatio-temporal perspectives: (1) it captures high-order associations among trajectories by constructing a trajectory hypergraph and leverages a hypergraph attention network to learn the variable impact of POIs on trajectories; (2) it models the spatio-temporal characteristics of trajectories by incorporating their temporal and spatial information into a sequential encoder. Moreover, we design a data balancing method to effectively address the user class imbalance problem and experimentally validate its significance in TUL. Extensive experiments on three real-world datasets demonstrate that HGTUL outperforms state-of-the-art baselines, achieving improvements of 2.57%~20.09% and 5.68%~26.00% in ACC@1 and Macro-F1 metrics, respectively.
Deep Reversible Consistency Learning for Cross-modal Retrieval
Jan 10, 2025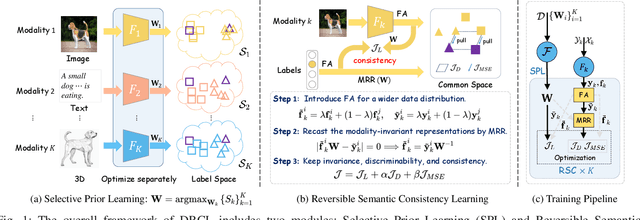
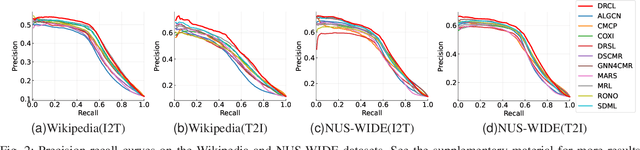
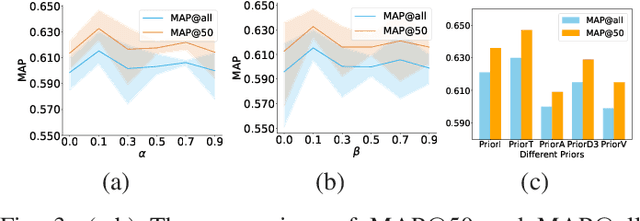
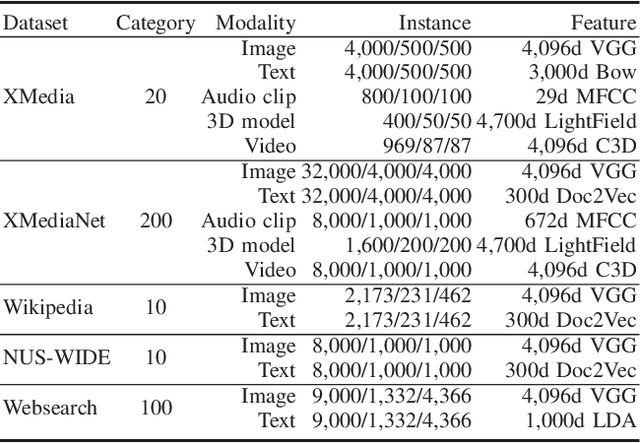
Cross-modal retrieval (CMR) typically involves learning common representations to directly measure similarities between multimodal samples. Most existing CMR methods commonly assume multimodal samples in pairs and employ joint training to learn common representations, limiting the flexibility of CMR. Although some methods adopt independent training strategies for each modality to improve flexibility in CMR, they utilize the randomly initialized orthogonal matrices to guide representation learning, which is suboptimal since they assume inter-class samples are independent of each other, limiting the potential of semantic alignments between sample representations and ground-truth labels. To address these issues, we propose a novel method termed Deep Reversible Consistency Learning (DRCL) for cross-modal retrieval. DRCL includes two core modules, \ie Selective Prior Learning (SPL) and Reversible Semantic Consistency learning (RSC). More specifically, SPL first learns a transformation weight matrix on each modality and selects the best one based on the quality score as the Prior, which greatly avoids blind selection of priors learned from low-quality modalities. Then, RSC employs a Modality-invariant Representation Recasting mechanism (MRR) to recast the potential modality-invariant representations from sample semantic labels by the generalized inverse matrix of the prior. Since labels are devoid of modal-specific information, we utilize the recast features to guide the representation learning, thus maintaining semantic consistency to the fullest extent possible. In addition, a feature augmentation mechanism (FA) is introduced in RSC to encourage the model to learn over a wider data distribution for diversity. Finally, extensive experiments conducted on five widely used datasets and comparisons with 15 state-of-the-art baselines demonstrate the effectiveness and superiority of our DRCL.
Robust Self-Paced Hashing for Cross-Modal Retrieval with Noisy Labels
Jan 03, 2025



Cross-modal hashing (CMH) has appeared as a popular technique for cross-modal retrieval due to its low storage cost and high computational efficiency in large-scale data. Most existing methods implicitly assume that multi-modal data is correctly labeled, which is expensive and even unattainable due to the inevitable imperfect annotations (i.e., noisy labels) in real-world scenarios. Inspired by human cognitive learning, a few methods introduce self-paced learning (SPL) to gradually train the model from easy to hard samples, which is often used to mitigate the effects of feature noise or outliers. It is a less-touched problem that how to utilize SPL to alleviate the misleading of noisy labels on the hash model. To tackle this problem, we propose a new cognitive cross-modal retrieval method called Robust Self-paced Hashing with Noisy Labels (RSHNL), which can mimic the human cognitive process to identify the noise while embracing robustness against noisy labels. Specifically, we first propose a contrastive hashing learning (CHL) scheme to improve multi-modal consistency, thereby reducing the inherent semantic gap. Afterward, we propose center aggregation learning (CAL) to mitigate the intra-class variations. Finally, we propose Noise-tolerance Self-paced Hashing (NSH) that dynamically estimates the learning difficulty for each instance and distinguishes noisy labels through the difficulty level. For all estimated clean pairs, we further adopt a self-paced regularizer to gradually learn hash codes from easy to hard. Extensive experiments demonstrate that the proposed RSHNL performs remarkably well over the state-of-the-art CMH methods.
ROUTE: Robust Multitask Tuning and Collaboration for Text-to-SQL
Dec 13, 2024



Despite the significant advancements in Text-to-SQL (Text2SQL) facilitated by large language models (LLMs), the latest state-of-the-art techniques are still trapped in the in-context learning of closed-source LLMs (e.g., GPT-4), which limits their applicability in open scenarios. To address this challenge, we propose a novel RObust mUltitask Tuning and collaboration mEthod (ROUTE) to improve the comprehensive capabilities of open-source LLMs for Text2SQL, thereby providing a more practical solution. Our approach begins with multi-task supervised fine-tuning (SFT) using various synthetic training data related to SQL generation. Unlike existing SFT-based Text2SQL methods, we introduced several additional SFT tasks, including schema linking, noise correction, and continuation writing. Engaging in a variety of SQL generation tasks enhances the model's understanding of SQL syntax and improves its ability to generate high-quality SQL queries. Additionally, inspired by the collaborative modes of LLM agents, we introduce a Multitask Collaboration Prompting (MCP) strategy. This strategy leverages collaboration across several SQL-related tasks to reduce hallucinations during SQL generation, thereby maximizing the potential of enhancing Text2SQL performance through explicit multitask capabilities. Extensive experiments and in-depth analyses have been performed on eight open-source LLMs and five widely-used benchmarks. The results demonstrate that our proposal outperforms the latest Text2SQL methods and yields leading performance.
A dataset of primary nasopharyngeal carcinoma MRI with multi-modalities segmentation
Apr 04, 2024Multi-modality magnetic resonance imaging data with various sequences facilitate the early diagnosis, tumor segmentation, and disease staging in the management of nasopharyngeal carcinoma (NPC). The lack of publicly available, comprehensive datasets limits advancements in diagnosis, treatment planning, and the development of machine learning algorithms for NPC. Addressing this critical need, we introduce the first comprehensive NPC MRI dataset, encompassing MR axial imaging of 277 primary NPC patients. This dataset includes T1-weighted, T2-weighted, and contrast-enhanced T1-weighted sequences, totaling 831 scans. In addition to the corresponding clinical data, manually annotated and labeled segmentations by experienced radiologists offer high-quality data resources from untreated primary NPC.
PointCloud-Text Matching: Benchmark Datasets and a Baseline
Mar 28, 2024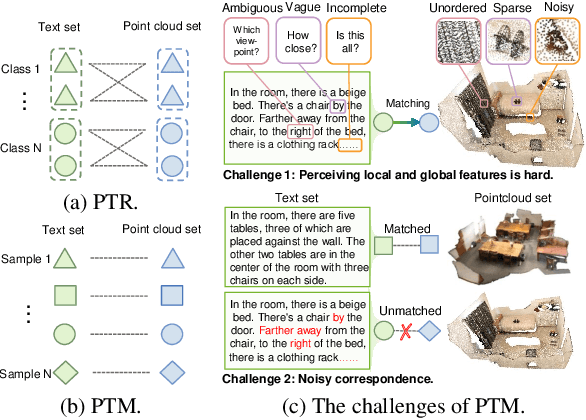



In this paper, we present and study a new instance-level retrieval task: PointCloud-Text Matching~(PTM), which aims to find the exact cross-modal instance that matches a given point-cloud query or text query. PTM could be applied to various scenarios, such as indoor/urban-canyon localization and scene retrieval. However, there exists no suitable and targeted dataset for PTM in practice. Therefore, we construct three new PTM benchmark datasets, namely 3D2T-SR, 3D2T-NR, and 3D2T-QA. We observe that the data is challenging and with noisy correspondence due to the sparsity, noise, or disorder of point clouds and the ambiguity, vagueness, or incompleteness of texts, which make existing cross-modal matching methods ineffective for PTM. To tackle these challenges, we propose a PTM baseline, named Robust PointCloud-Text Matching method (RoMa). RoMa consists of two modules: a Dual Attention Perception module (DAP) and a Robust Negative Contrastive Learning module (RNCL). Specifically, DAP leverages token-level and feature-level attention to adaptively focus on useful local and global features, and aggregate them into common representations, thereby reducing the adverse impact of noise and ambiguity. To handle noisy correspondence, RNCL divides negative pairs, which are much less error-prone than positive pairs, into clean and noisy subsets, and assigns them forward and reverse optimization directions respectively, thus enhancing robustness against noisy correspondence. We conduct extensive experiments on our benchmarks and demonstrate the superiority of our RoMa.
Cross-modal Active Complementary Learning with Self-refining Correspondence
Oct 26, 2023
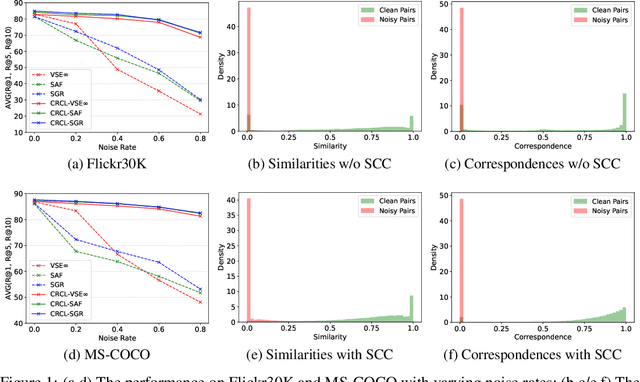

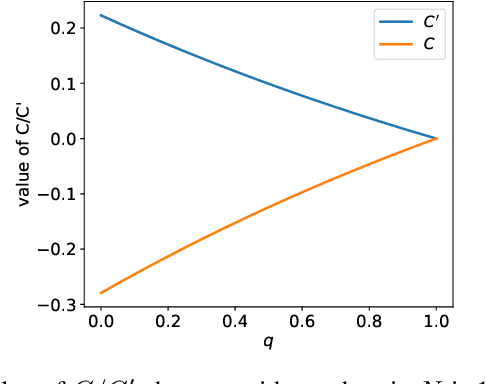
Recently, image-text matching has attracted more and more attention from academia and industry, which is fundamental to understanding the latent correspondence across visual and textual modalities. However, most existing methods implicitly assume the training pairs are well-aligned while ignoring the ubiquitous annotation noise, a.k.a noisy correspondence (NC), thereby inevitably leading to a performance drop. Although some methods attempt to address such noise, they still face two challenging problems: excessive memorizing/overfitting and unreliable correction for NC, especially under high noise. To address the two problems, we propose a generalized Cross-modal Robust Complementary Learning framework (CRCL), which benefits from a novel Active Complementary Loss (ACL) and an efficient Self-refining Correspondence Correction (SCC) to improve the robustness of existing methods. Specifically, ACL exploits active and complementary learning losses to reduce the risk of providing erroneous supervision, leading to theoretically and experimentally demonstrated robustness against NC. SCC utilizes multiple self-refining processes with momentum correction to enlarge the receptive field for correcting correspondences, thereby alleviating error accumulation and achieving accurate and stable corrections. We carry out extensive experiments on three image-text benchmarks, i.e., Flickr30K, MS-COCO, and CC152K, to verify the superior robustness of our CRCL against synthetic and real-world noisy correspondences.