 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy-Correspondence Learning for Text-to-Image Person Re-identification
Paper and Code


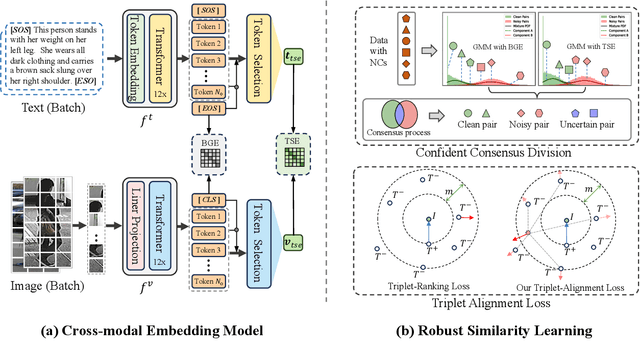

Text-to-image person re-identification (TIReID) is a compelling topic in the cross-modal community, which aims to retrieve the target person based on a textual query. Although numerous TIReID methods have been proposed and achieved promising performance, they implicitly assume the training image-text pairs are correctly aligned, which is not always the case in real-world scenarios. In practice, the image-text pairs inevitably exist under-correlated or even false-correlated, a.k.a noisy correspondence (NC), due to the low quality of the images and annotation errors. To address this problem, we propose a novel Robust Dual Embedding method (RDE) that can learn robust visual-semantic associations even with NC. Specifically, RDE consists of two main components: 1) A Confident Consensus Division (CCD) module that leverages the dual-grained decisions of dual embedding modules to obtain a consensus set of clean training data, which enables the model to learn correct and reliable visual-semantic associations. 2) A Triplet-Alignment Loss (TAL) relaxes the conventional triplet-ranking loss with hardest negatives, which tends to rapidly overfit NC, to a log-exponential upper bound over all negatives, thus preventing the model from overemphasizing false image-text pairs. We conduct extensive experiments on three public benchmarks, namely CUHK-PEDES, ICFG-PEDES, and RSTPReID, to evaluate the performance and robustness of our RDE. Our method achieves state-of-the-art results both with and without synthetic noisy correspondences on all three datasets.