 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonTabQA: A Comprehensive Benchmark for Table Question Answering from Real World Industrial Scenarios
Jan 12, 2026Recent advancements in Large Language Models (LLMs) have significantly catalyzed table-based question answering (TableQA). However, existing TableQA benchmarks often overlook the intricacies of industrial scenarios, which are characterized by multi-table structures, nested headers, and massive scales. These environments demand robust table reasoning through deep structured inference, presenting a significant challenge that remains inadequately addressed by current methodologies. To bridge this gap, we present ReasonTabQA, a large-scale bilingual benchmark encompassing 1,932 tables across 30 industry domains such as energy and automotive. ReasonTabQA provides high-quality annotations for both final answers and explicit reasoning chains, supporting both thinking and no-thinking paradigms. Furthermore, we introduce TabCodeRL, a reinforcement learning method that leverages table-aware verifiable rewards to guide the generation of logical reasoning paths. Extensive experiments on ReasonTabQA and 4 TableQA datasets demonstrate that while TabCodeRL yields substantial performance gains on open-source LLMs, the persistent performance gap on ReasonTabQA underscores the inherent complexity of real-world industrial TableQA.
A Unified Spoken Language Model with Injected Emotional-Attribution Thinking for Human-like Interaction
Jan 08, 2026This paper presents a unified spoken language model for emotional intelligence, enhanced by a novel data construction strategy termed Injected Emotional-Attribution Thinking (IEAT). IEAT incorporates user emotional states and their underlying causes into the model's internal reasoning process, enabling emotion-aware reasoning to be internalized rather than treated as explicit supervision. The model is trained with a two-stage progressive strategy. The first stage performs speech-text alignment and emotional attribute modeling via self-distillation, while the second stage conducts end-to-end cross-modal joint optimization to ensure consistency between textual and spoken emotional expressions. Experiments on the Human-like Spoken Dialogue Systems Challenge (HumDial) Emotional Intelligence benchmark demonstrate that the proposed approach achieves top-ranked performance across emotional trajectory modeling, emotional reasoning, and empathetic response generation under both LLM-based and human evaluations.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Outlier detection in mixed-attribute data: a semi-supervised approach with fuzzy approximations and relative entropy
Dec 22, 2025Outlier detection is a critical task in data mining, aimed at identifying objects that significantly deviate from the norm. Semi-supervised methods improve detection performance by leveraging partially labeled data but typically overlook the uncertainty and heterogeneity of real-world mixed-attribute data. This paper introduces a semi-supervised outlier detection method, namely fuzzy rough sets-based outlier detection (FROD), to effectively handle these challenges. Specifically, we first utilize a small subset of labeled data to construct fuzzy decision systems, through which we introduce the attribute classification accuracy based on fuzzy approximations to evaluate the contribution of attribute sets in outlier detection. Unlabeled data is then used to compute fuzzy relative entropy, which provides a characterization of outliers from the perspective of uncertainty. Finally, we develop the detection algorithm by combining attribute classification accuracy with fuzzy relative entropy. Experimental results on 16 public datasets show that FROD is comparable with or better than leading detection algorithms. All datasets and source codes are accessible at https://github.com/ChenBaiyang/FROD. This manuscript is the accepted author version of a paper published by Elsevier. The final published version is available at https://doi.org/10.1016/j.ijar.2025.109373
* Author's accepted manuscript
Multi-Intent Spoken Language Understanding: Methods, Trends, and Challenges
Dec 12, 2025Multi-intent spoken language understanding (SLU) involves two tasks: multiple intent detection and slot filling, which jointly handle utterances containing more than one intent. Owing to this characteristic, which closely reflects real-world applications, the task has attracted increasing research attention, and substantial progress has been achieved. However, there remains a lack of a comprehensive and systematic review of existing studies on multi-intent SLU. To this end, this paper presents a survey of recent advances in multi-intent SLU. We provide an in-depth overview of previous research from two perspectives: decoding paradigms and modeling approaches. On this basis, we further compare the performance of representative models and analyze their strengths and limitations. Finally, we discuss the current challenges and outline promising directions for future research. We hope this survey will offer valuable insights and serve as a useful reference for advancing research in multi-intent SLU.
MR-UIE: Multi-Perspective Reasoning with Reinforcement Learning for Universal Information Extraction
Sep 11, 2025Large language models (LLMs) demonstrate robust capabilities across diverse research domains. However, their performance in universal information extraction (UIE) remains insufficient, especially when tackling structured output scenarios that involve complex schema descriptions and require multi-step reasoning. While existing approaches enhance the performance of LLMs through in-context learning and instruction tuning, significant limitations nonetheless persist. To enhance the model's generalization ability, we propose integrating reinforcement learning (RL) with multi-perspective reasoning for information extraction (IE) tasks. Our work transitions LLMs from passive extractors to active reasoners, enabling them to understand not only what to extract but also how to reason. Experiments conducted on multiple IE benchmarks demonstrate that MR-UIE consistently elevates extraction accuracy across domains and surpasses state-of-the-art methods on several datasets. Furthermore, incorporating multi-perspective reasoning into RL notably enhances generalization in complex IE tasks, underscoring the critical role of reasoning in challenging scenarios.
T2R-bench: A Benchmark for Generating Article-Level Reports from Real World Industrial Tables
Aug 27, 2025Extensive research has been conducted to explore the capabilities of large language models (LLMs) in table reasoning. However, the essential task of transforming tables information into reports remains a significant challenge for industrial applications. This task is plagued by two critical issues: 1) the complexity and diversity of tables lead to suboptimal reasoning outcomes; and 2) existing table benchmarks lack the capacity to adequately assess the practical application of this task. To fill this gap, we propose the table-to-report task and construct a bilingual benchmark named T2R-bench, where the key information flow from the tables to the reports for this task. The benchmark comprises 457 industrial tables, all derived from real-world scenarios and encompassing 19 industry domains as well as 4 types of industrial tables. Furthermore, we propose an evaluation criteria to fairly measure the quality of report generation. The experiments on 25 widely-used LLMs reveal that even state-of-the-art models like Deepseek-R1 only achieves performance with 62.71 overall score, indicating that LLMs still have room for improvement on T2R-bench. Source code and data will be available after acceptance.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
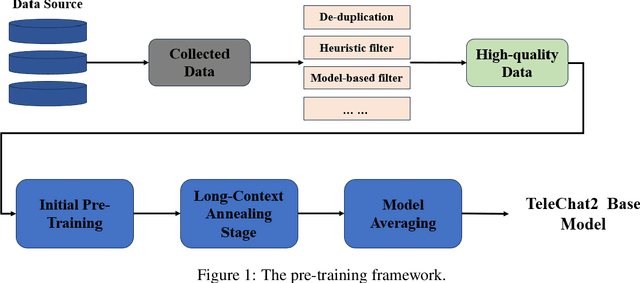

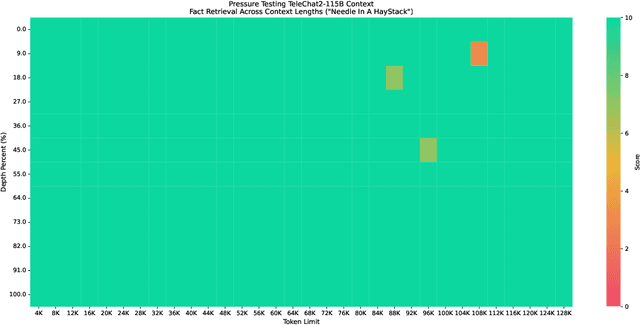
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
TELEVAL: A Dynamic Benchmark Designed for Spoken Language Models in Chinese Interactive Scenarios
Jul 24, 2025Spoken language models (SLMs) have seen rapid progress in recent years, along with the development of numerous benchmarks for evaluating their performance. However, most existing benchmarks primarily focus on evaluating whether SLMs can perform complex tasks comparable to those tackled by large language models (LLMs), often failing to align with how users naturally interact in real-world conversational scenarios. In this paper, we propose TELEVAL, a dynamic benchmark specifically designed to evaluate SLMs' effectiveness as conversational agents in realistic Chinese interactive settings. TELEVAL defines three evaluation dimensions: Explicit Semantics, Paralinguistic and Implicit Semantics, and System Abilities. It adopts a dialogue format consistent with real-world usage and evaluates text and audio outputs separately. TELEVAL particularly focuses on the model's ability to extract implicit cues from user speech and respond appropriately without additional instructions. Our experiments demonstrate that despite recent progress, existing SLMs still have considerable room for improvement in natural conversational tasks. We hope that TELEVAL can serve as a user-centered evaluation framework that directly reflects the user experience and contributes to the development of more capable dialogue-oriented SLMs.
BoSS: Beyond-Semantic Speech
Jul 23, 2025Human communication involves more than explicit semantics, with implicit signals and contextual cues playing a critical role in shaping meaning. However, modern speech technologies, such as Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) often fail to capture these beyond-semantic dimensions. To better characterize and benchmark the progression of speech intelligence, we introduce Spoken Interaction System Capability Levels (L1-L5), a hierarchical framework illustrated the evolution of spoken dialogue systems from basic command recognition to human-like social interaction. To support these advanced capabilities, we propose Beyond-Semantic Speech (BoSS), which refers to the set of information in speech communication that encompasses but transcends explicit semantics. It conveys emotions, contexts, and modifies or extends meanings through multidimensional features such as affective cues, contextual dynamics, and implicit semantics, thereby enhancing the understanding of communicative intentions and scenarios. We present a formalized framework for BoSS, leveraging cognitive relevance theories and machine learning models to analyze temporal and contextual speech dynamics. We evaluate BoSS-related attributes across five different dimensions, reveals that current spoken language models (SLMs) are hard to fully interpret beyond-semantic signals. These findings highlight the need for advancing BoSS research to enable richer, more context-aware human-machine communication.