 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangle and denoise: Tackling context misalignment for video moment retrieval
Aug 14, 2024Video Moment Retrieval, which aims to locate in-context video moments according to a natural language query, is an essential task for cross-modal grounding. Existing methods focus on enhancing the cross-modal interactions between all moments and the textual description for video understanding. However, constantly interacting with all locations is unreasonable because of uneven semantic distribution across the timeline and noisy visual backgrounds. This paper proposes a cross-modal Context Denoising Network (CDNet) for accurate moment retrieval by disentangling complex correlations and denoising irrelevant dynamics.Specifically, we propose a query-guided semantic disentanglement (QSD) to decouple video moments by estimating alignment levels according to the global and fine-grained correlation. A Context-aware Dynamic Denoisement (CDD) is proposed to enhance understanding of aligned spatial-temporal details by learning a group of query-relevant offsets. Extensive experiments on public benchmarks demonstrate that the proposed CDNet achieves state-of-the-art performances.
ProTA: Probabilistic Token Aggregation for Text-Video Retrieval
Apr 18, 2024



Text-video retrieval aims to find the most relevant cross-modal samples for a given query. Recent methods focus on modeling the whole spatial-temporal relations. However, since video clips contain more diverse content than captions, the model aligning these asymmetric video-text pairs has a high risk of retrieving many false positive results. In this paper, we propose Probabilistic Token Aggregation (\textit{ProTA}) to handle cross-modal interaction with content asymmetry. Specifically, we propose dual partial-related aggregation to disentangle and re-aggregate token representations in both low-dimension and high-dimension spaces. We propose token-based probabilistic alignment to generate token-level probabilistic representation and maintain the feature representation diversity. In addition, an adaptive contrastive loss is proposed to learn compact cross-modal distribution space. Based on extensive experiments, \textit{ProTA} achieves significant improvements on MSR-VTT (50.9%), LSMDC (25.8%), and DiDeMo (47.2%).
Integrating Listwise Ranking into Pairwise-based Image-Text Retrieval
May 26, 2023



Image-Text Retrieval (ITR) is essentially a ranking problem. Given a query caption, the goal is to rank candidate images by relevance, from large to small. The current ITR datasets are constructed in a pairwise manner. Image-text pairs are annotated as positive or negative. Correspondingly, ITR models mainly use pairwise losses, such as triplet loss, to learn to rank. Pairwise-based ITR increases positive pair similarity while decreasing negative pair similarity indiscriminately. However, the relevance between dissimilar negative pairs is different. Pairwise annotations cannot reflect this difference in relevance. In the current datasets, pairwise annotations miss many correlations. There are many potential positive pairs among the pairs labeled as negative. Pairwise-based ITR can only rank positive samples before negative samples, but cannot rank negative samples by relevance. In this paper, we integrate listwise ranking into conventional pairwise-based ITR. Listwise ranking optimizes the entire ranking list based on relevance scores. Specifically, we first propose a Relevance Score Calculation (RSC) module to calculate the relevance score of the entire ranked list. Then we choose the ranking metric, Normalized Discounted Cumulative Gain (NDCG), as the optimization objective. We transform the non-differentiable NDCG into a differentiable listwise loss, named Smooth-NDCG (S-NDCG). Our listwise ranking approach can be plug-and-play integrated into current pairwise-based ITR models. Experiments on ITR benchmarks show that integrating listwise ranking can improve the performance of current ITR models and provide more user-friendly retrieval results. The code is available at https://github.com/AAA-Zheng/Listwise_ITR.
Selectively Hard Negative Mining for Alleviating Gradient Vanishing in Image-Text Matching
Mar 01, 2023



Recently, a series of Image-Text Matching (ITM) methods achieve impressive performance. However, we observe that most existing ITM models suffer from gradients vanishing at the beginning of training, which makes these models prone to falling into local minima. Most ITM models adopt triplet loss with Hard Negative mining (HN) as the optimization objective. We find that optimizing an ITM model using only the hard negative samples can easily lead to gradient vanishing. In this paper, we derive the condition under which the gradient vanishes during training. When the difference between the positive pair similarity and the negative pair similarity is close to 0, the gradients on both the image and text encoders will approach 0. To alleviate the gradient vanishing problem, we propose a Selectively Hard Negative Mining (SelHN) strategy, which chooses whether to mine hard negative samples according to the gradient vanishing condition. SelHN can be plug-and-play applied to existing ITM models to give them better training behavior. To further ensure the back-propagation of gradients, we construct a Residual Visual Semantic Embedding model with SelHN, denoted as RVSE++. Extensive experiments on two ITM benchmarks demonstrate the strength of RVSE++, achieving state-of-the-art performance.
Image-Text Retrieval with Binary and Continuous Label Supervision
Oct 20, 2022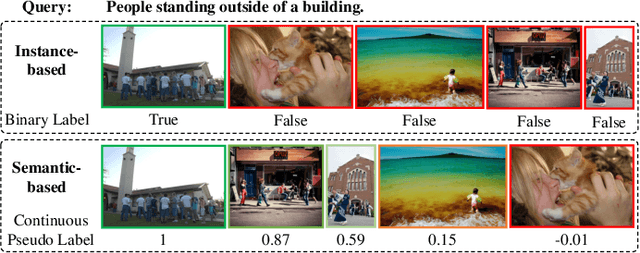
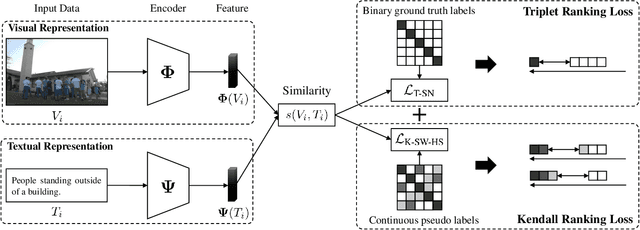
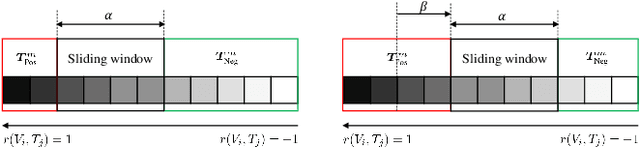
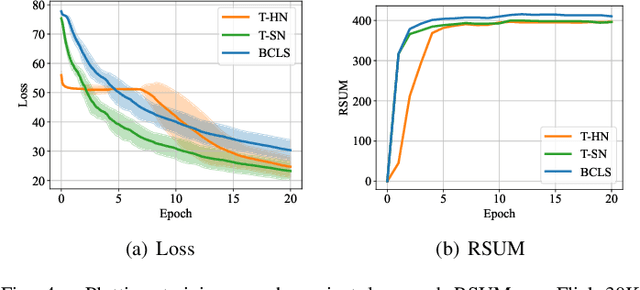
Most image-text retrieval work adopts binary labels indicating whether a pair of image and text matches or not. Such a binary indicator covers only a limited subset of image-text semantic relations, which is insufficient to represent relevance degrees between images and texts described by continuous labels such as image captions. The visual-semantic embedding space obtained by learning binary labels is incoherent and cannot fully characterize the relevance degrees. In addition to the use of binary labels, this paper further incorporates continuous pseudo labels (generally approximated by text similarity between captions) to indicate the relevance degrees. To learn a coherent embedding space, we propose an image-text retrieval framework with Binary and Continuous Label Supervision (BCLS), where binary labels are used to guide the retrieval model to learn limited binary correlations, and continuous labels are complementary to the learning of image-text semantic relations. For the learning of binary labels, we improve the common Triplet ranking loss with Soft Negative mining (Triplet-SN) to improve convergence. For the learning of continuous labels, we design Kendall ranking loss inspired by Kendall rank correlation coefficient (Kendall), which improves the correlation between the similarity scores predicted by the retrieval model and the continuous labels. To mitigate the noise introduced by the continuous pseudo labels, we further design Sliding Window sampling and Hard Sample mining strategy (SW-HS) to alleviate the impact of noise and reduce the complexity of our framework to the same order of magnitude as the triplet ranking loss. Extensive experiments on two image-text retrieval benchmarks demonstrate that our method can improve the performance of state-of-the-art image-text retrieval models.
Unified Loss of Pair Similarity Optimization for Vision-Language Retrieval
Sep 28, 2022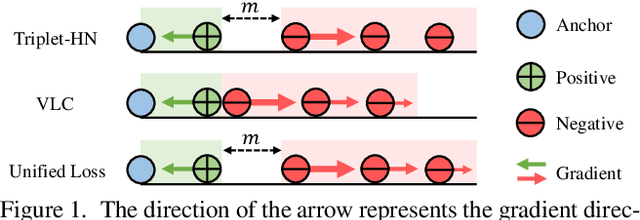
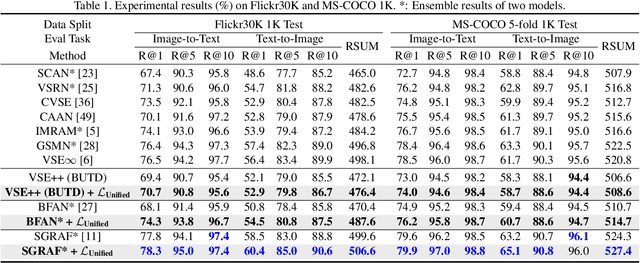
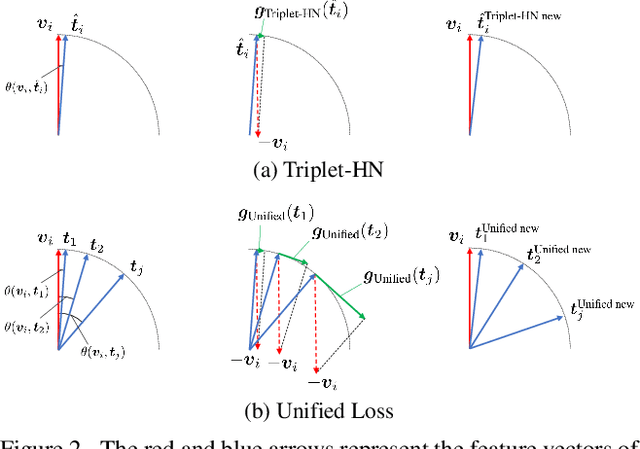

There are two popular loss functions used for vision-language retrieval, i.e., triplet loss and contrastive learning loss, both of them essentially minimize the difference between the similarities of negative pairs and positive pairs. More specifically, Triplet loss with Hard Negative mining (Triplet-HN), which is widely used in existing retrieval models to improve the discriminative ability, is easy to fall into local minima in training. On the other hand, Vision-Language Contrastive learning loss (VLC), which is widely used in the vision-language pre-training, has been shown to achieve significant performance gains on vision-language retrieval, but the performance of fine-tuning with VLC on small datasets is not satisfactory. This paper proposes a unified loss of pair similarity optimization for vision-language retrieval, providing a powerful tool for understanding existing loss functions. Our unified loss includes the hard sample mining strategy of VLC and introduces the margin used by the triplet loss for better similarity separation. It is shown that both Triplet-HN and VLC are special forms of our unified loss. Compared with the Triplet-HN, our unified loss has a fast convergence speed. Compared with the VLC, our unified loss is more discriminative and can provide better generalization in downstream fine-tuning tasks. Experiments on image-text and video-text retrieval benchmarks show that our unified loss can significantly improve the performance of the state-of-the-art retrieval models.
Exploiting Visual Semantic Reasoning for Video-Text Retrieval
Jun 16, 2020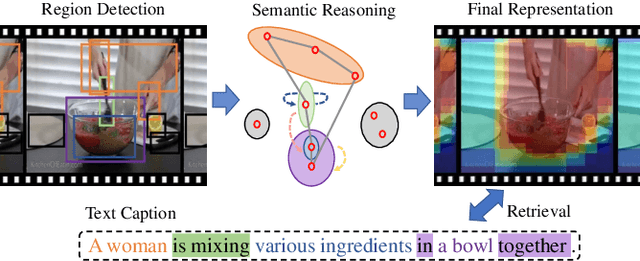

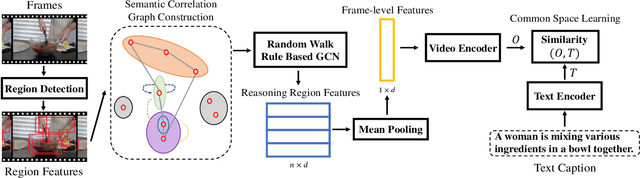

Video retrieval is a challenging research topic bridging the vision and language areas and has attracted broad attention in recent years. Previous works have been devoted to representing videos by directly encoding from frame-level features. In fact, videos consist of various and abundant semantic relations to which existing methods pay less attention. To address this issue, we propose a Visual Semantic Enhanced Reasoning Network (ViSERN) to exploit reasoning between frame regions. Specifically, we consider frame regions as vertices and construct a fully-connected semantic correlation graph. Then, we perform reasoning by novel random walk rule-based graph convolutional networks to generate region features involved with semantic relations. With the benefit of reasoning, semantic interactions between regions are considered, while the impact of redundancy is suppressed. Finally, the region features are aggregated to form frame-level features for further encoding to measure video-text similarity. Extensive experiments on two public benchmark datasets validate the effectiveness of our method by achieving state-of-the-art performance due to the powerful semantic reasoning.