 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelectively Hard Negative Mining for Alleviating Gradient Vanishing in Image-Text Matching
Mar 01, 2023



Recently, a series of Image-Text Matching (ITM) methods achieve impressive performance. However, we observe that most existing ITM models suffer from gradients vanishing at the beginning of training, which makes these models prone to falling into local minima. Most ITM models adopt triplet loss with Hard Negative mining (HN) as the optimization objective. We find that optimizing an ITM model using only the hard negative samples can easily lead to gradient vanishing. In this paper, we derive the condition under which the gradient vanishes during training. When the difference between the positive pair similarity and the negative pair similarity is close to 0, the gradients on both the image and text encoders will approach 0. To alleviate the gradient vanishing problem, we propose a Selectively Hard Negative Mining (SelHN) strategy, which chooses whether to mine hard negative samples according to the gradient vanishing condition. SelHN can be plug-and-play applied to existing ITM models to give them better training behavior. To further ensure the back-propagation of gradients, we construct a Residual Visual Semantic Embedding model with SelHN, denoted as RVSE++. Extensive experiments on two ITM benchmarks demonstrate the strength of RVSE++, achieving state-of-the-art performance.
Unified Loss of Pair Similarity Optimization for Vision-Language Retrieval
Sep 28, 2022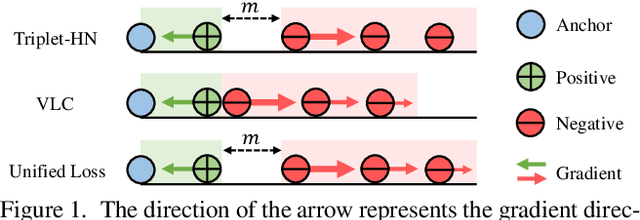
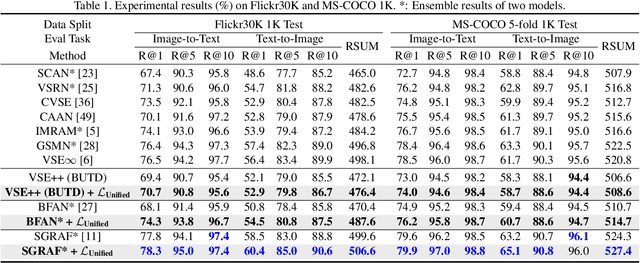
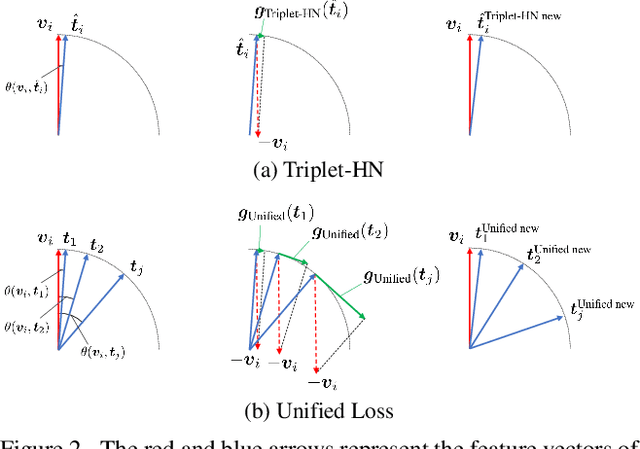

There are two popular loss functions used for vision-language retrieval, i.e., triplet loss and contrastive learning loss, both of them essentially minimize the difference between the similarities of negative pairs and positive pairs. More specifically, Triplet loss with Hard Negative mining (Triplet-HN), which is widely used in existing retrieval models to improve the discriminative ability, is easy to fall into local minima in training. On the other hand, Vision-Language Contrastive learning loss (VLC), which is widely used in the vision-language pre-training, has been shown to achieve significant performance gains on vision-language retrieval, but the performance of fine-tuning with VLC on small datasets is not satisfactory. This paper proposes a unified loss of pair similarity optimization for vision-language retrieval, providing a powerful tool for understanding existing loss functions. Our unified loss includes the hard sample mining strategy of VLC and introduces the margin used by the triplet loss for better similarity separation. It is shown that both Triplet-HN and VLC are special forms of our unified loss. Compared with the Triplet-HN, our unified loss has a fast convergence speed. Compared with the VLC, our unified loss is more discriminative and can provide better generalization in downstream fine-tuning tasks. Experiments on image-text and video-text retrieval benchmarks show that our unified loss can significantly improve the performance of the state-of-the-art retrieval models.