 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Communication with an LLM-enabled Knowledge Base
Apr 07, 2026Semantic communication (SC) can achieve superior coding and transmission performance based on the knowledge contained in the semantic knowledge base (KB). However, conventional KBs consist of source KBs and channel KBs, which are often costly to obtain data and limited in data scale. Fortunately, large language models (LLMs) have recently emerged with extensive knowledge and generative capabilities. Therefore, this paper proposes an SC system with LLM-enabled knowledge base (SC-LMKB), which utilizes the generation ability of LLMs to significantly enrich the KB of SC systems. In particular, we first design an LLM-enabled generation mechanism with a prompt engineering strategy for source data generation (SDG) and a cross-attention alignment method for channel data generation (CDG). However, hallucinations from LLMs may cause semantic noise, thus degrading SC performance. To mitigate the hallucination issue, a cross-domain fusion codec (CDFC) framework with a hallucination filtering phase and a cross-domain fusion phase is then proposed for SDG. In particular, the first phase filters out new data generated by the LMKB irrelevant to the original data based on semantic similarity. Then, a cross-domain fusion phase is proposed, which fuses source data with LLM-generated data based on their semantic importance, thereby enhancing task performance. Besides, a joint training objective that combines cross-entropy loss and reconstruction loss is proposed to reduce the impact of hallucination on CDG. Experiment results on three cross-modality retrieval tasks demonstrate that the proposed SC-LMKB can achieve up to 72.6\% and 90.7\% performance gains compared to conventional SC systems and LLM-enabled SC systems, respectively.
Lightweight Task-Oriented Semantic Communication Empowered by Large-Scale AI Models
Jun 16, 2025Recent studies have focused on leveraging large-scale artificial intelligence (LAI) models to improve semantic representation and compression capabilities. However, the substantial computational demands of LAI models pose significant challenges for real-time communication scenarios. To address this, this paper proposes utilizing knowledge distillation (KD) techniques to extract and condense knowledge from LAI models, effectively reducing model complexity and computation latency. Nevertheless, the inherent complexity of LAI models leads to prolonged inference times during distillation, while their lack of channel awareness compromises the distillation performance. These limitations make standard KD methods unsuitable for task-oriented semantic communication scenarios. To address these issues, we propose a fast distillation method featuring a pre-stored compression mechanism that eliminates the need for repetitive inference, significantly improving efficiency. Furthermore, a channel adaptive module is incorporated to dynamically adjust the transmitted semantic information based on varying channel conditions, enhancing communication reliability and adaptability. In addition, an information bottleneck-based loss function is derived to guide the fast distillation process. Simulation results verify that the proposed scheme outperform baselines in term of task accuracy, model size, computation latency, and training data requirements.
A New Paradigm of User-Centric Wireless Communication Driven by Large Language Models
Apr 16, 2025The next generation of wireless communications seeks to deeply integrate artificial intelligence (AI) with user-centric communication networks, with the goal of developing AI-native networks that more accurately address user requirements. The rapid development of large language models (LLMs) offers significant potential in realizing these goals. However, existing efforts that leverage LLMs for wireless communication often overlook the considerable gap between human natural language and the intricacies of real-world communication systems, thus failing to fully exploit the capabilities of LLMs. To address this gap, we propose a novel LLM-driven paradigm for wireless communication that innovatively incorporates the nature language to structured query language (NL2SQL) tool. Specifically, in this paradigm, user personal requirements is the primary focus. Upon receiving a user request, LLMs first analyze the user intent in terms of relevant communication metrics and system parameters. Subsequently, a structured query language (SQL) statement is generated to retrieve the specific parameter values from a high-performance real-time database. We further utilize LLMs to formulate and solve an optimization problem based on the user request and the retrieved parameters. The solution to this optimization problem then drives adjustments in the communication system to fulfill the user's requirements. To validate the feasibility of the proposed paradigm, we present a prototype system. In this prototype, we consider user-request centric semantic communication (URC-SC) system in which a dynamic semantic representation network at the physical layer adapts its encoding depth to meet user requirements. Additionally, two LLMs are employed to analyze user requests and generate SQL statements, respectively. Simulation results demonstrate the effectiveness.
Fusing Bluetooth with Pedestrian Dead Reckoning: A Floor Plan-Assisted Positioning Approach
Apr 14, 2025
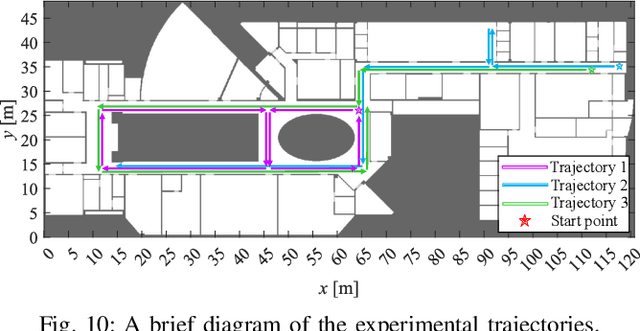
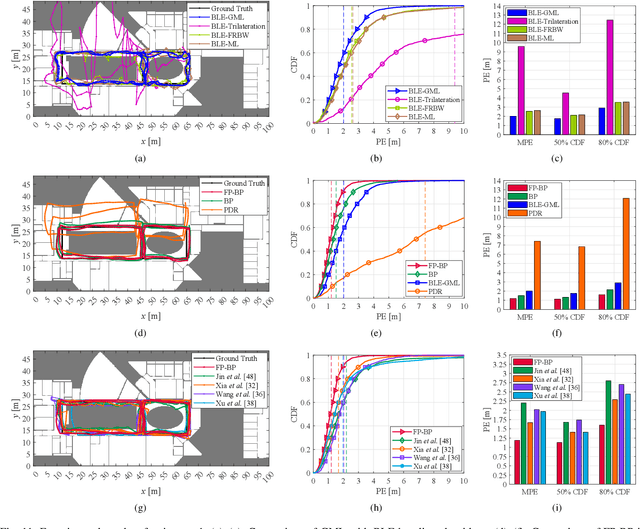
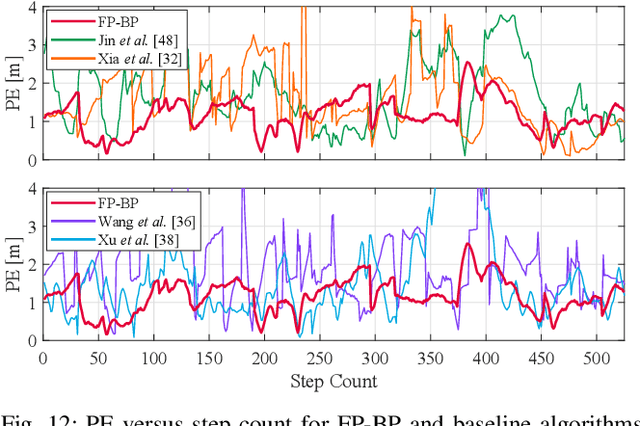
Floor plans can provide valuable prior information that helps enhance the accuracy of indoor positioning systems. However, existing research typically faces challenges in efficiently leveraging floor plan information and applying it to complex indoor layouts. To fully exploit information from floor plans for positioning, we propose a floor plan-assisted fusion positioning algorithm (FP-BP) using Bluetooth low energy (BLE) and pedestrian dead reckoning (PDR). In the considered system, a user holding a smartphone walks through a positioning area with BLE beacons installed on the ceiling, and can locate himself in real time. In particular, FP-BP consists of two phases. In the offline phase, FP-BP programmatically extracts map features from a stylized floor plan based on their binary masks, and constructs a mapping function to identify the corresponding map feature of any given position on the map. In the online phase, FP-BP continuously computes BLE positions and PDR results from BLE signals and smartphone sensors, where a novel grid-based maximum likelihood estimation (GML) algorithm is introduced to enhance BLE positioning. Then, a particle filter is used to fuse them and obtain an initial estimate. Finally, FP-BP performs post-position correction to obtain the final position based on its specific map feature. Experimental results show that FP-BP can achieve a real-time mean positioning accuracy of 1.19 m, representing an improvement of over 28% compared to existing floor plan-fused baseline algorithms.
Conformal Distributed Remote Inference in Sensor Networks Under Reliability and Communication Constraints
Sep 12, 2024



This paper presents communication-constrained distributed conformal risk control (CD-CRC) framework, a novel decision-making framework for sensor networks under communication constraints. Targeting multi-label classification problems, such as segmentation, CD-CRC dynamically adjusts local and global thresholds used to identify significant labels with the goal of ensuring a target false negative rate (FNR), while adhering to communication capacity limits. CD-CRC builds on online exponentiated gradient descent to estimate the relative quality of the observations of different sensors, and on online conformal risk control (CRC) as a mechanism to control local and global thresholds. CD-CRC is proved to offer deterministic worst-case performance guarantees in terms of FNR and communication overhead, while the regret performance in terms of false positive rate (FPR) is characterized as a function of the key hyperparameters. Simulation results highlight the effectiveness of CD-CRC, particularly in communication resource-constrained environments, making it a valuable tool for enhancing the performance and reliability of distributed sensor networks.
Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
Jun 06, 2024Text attribute person search aims to find specific pedestrians through given textual attributes, which is very meaningful in the scene of searching for designated pedestrians through witness descriptions. The key challenge is the significant modality gap between textual attributes and images. Previous methods focused on achieving explicit representation and alignment through unimodal pre-trained models. Nevertheless, the absence of inter-modality correspondence in these models may lead to distortions in the local information of intra-modality. Moreover, these methods only considered the alignment of inter-modality and ignored the differences between different attribute categories. To mitigate the above problems, we propose an Attribute-Aware Implicit Modality Alignment (AIMA) framework to learn the correspondence of local representations between textual attributes and images and combine global representation matching to narrow the modality gap. Firstly, we introduce the CLIP model as the backbone and design prompt templates to transform attribute combinations into structured sentences. This facilitates the model's ability to better understand and match image details. Next, we design a Masked Attribute Prediction (MAP) module that predicts the masked attributes after the interaction of image and masked textual attribute features through multi-modal interaction, thereby achieving implicit local relationship alignment. Finally, we propose an Attribute-IoU Guided Intra-Modal Contrastive (A-IoU IMC) loss, aligning the distribution of different textual attributes in the embedding space with their IoU distribution, achieving better semantic arrangement. Extensive experiments on the Market-1501 Attribute, PETA, and PA100K datasets show that the performance of our proposed method significantly surpasses the current state-of-the-art methods.
Data Augmentation for Text-based Person Retrieval Using Large Language Models
May 20, 2024



Text-based Person Retrieval (TPR) aims to retrieve person images that match the description given a text query. The performance improvement of the TPR model relies on high-quality data for supervised training. However, it is difficult to construct a large-scale, high-quality TPR dataset due to expensive annotation and privacy protection. Recently, Large Language Models (LLMs) have approached or even surpassed human performance on many NLP tasks, creating the possibility to expand high-quality TPR datasets. This paper proposes an LLM-based Data Augmentation (LLM-DA) method for TPR. LLM-DA uses LLMs to rewrite the text in the current TPR dataset, achieving high-quality expansion of the dataset concisely and efficiently. These rewritten texts are able to increase the diversity of vocabulary and sentence structure while retaining the original key concepts and semantic information. In order to alleviate the hallucinations of LLMs, LLM-DA introduces a Text Faithfulness Filter (TFF) to filter out unfaithful rewritten text. To balance the contributions of original text and augmented text, a Balanced Sampling Strategy (BSS) is proposed to control the proportion of original text and augmented text used for training. LLM-DA is a plug-and-play method that can be easily integrated into various TPR models. Comprehensive experiments on three TPR benchmarks show that LLM-DA can improve the retrieval performance of current TPR models.
Uncertainty, Calibration, and Membership Inference Attacks: An Information-Theoretic Perspective
Feb 16, 2024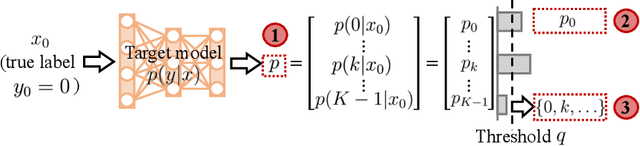


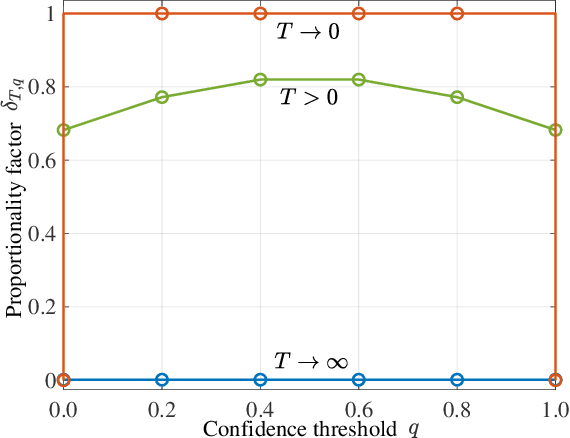
In a membership inference attack (MIA), an attacker exploits the overconfidence exhibited by typical machine learning models to determine whether a specific data point was used to train a target model. In this paper, we analyze the performance of the state-of-the-art likelihood ratio attack (LiRA) within an information-theoretical framework that allows the investigation of the impact of the aleatoric uncertainty in the true data generation process, of the epistemic uncertainty caused by a limited training data set, and of the calibration level of the target model. We compare three different settings, in which the attacker receives decreasingly informative feedback from the target model: confidence vector (CV) disclosure, in which the output probability vector is released; true label confidence (TLC) disclosure, in which only the probability assigned to the true label is made available by the model; and decision set (DS) disclosure, in which an adaptive prediction set is produced as in conformal prediction. We derive bounds on the advantage of an MIA adversary with the aim of offering insights into the impact of uncertainty and calibration on the effectiveness of MIAs. Simulation results demonstrate that the derived analytical bounds predict well the effectiveness of MIAs.
A Survey on Indoor Visible Light Positioning Systems: Fundamentals, Applications, and Challenges
Jan 25, 2024
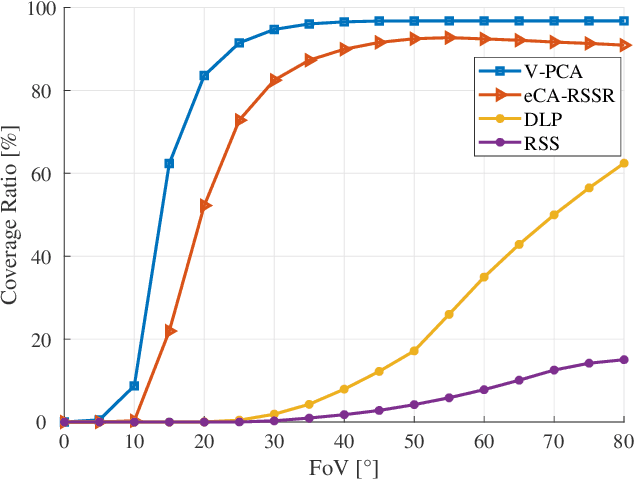
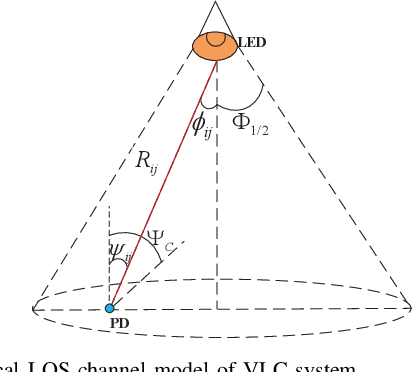
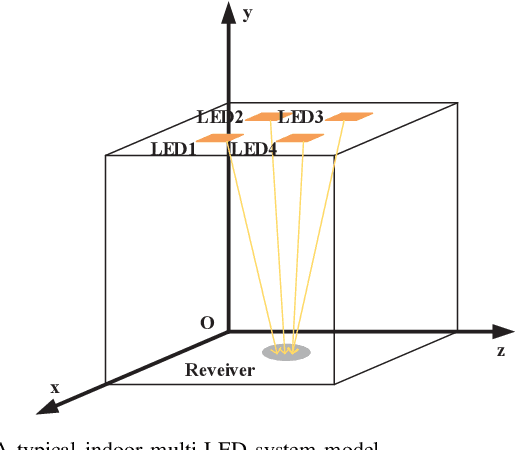
The growing demand for location-based services in areas like virtual reality, robot control, and navigation has intensified the focus on indoor localization. Visible light positioning (VLP), leveraging visible light communications (VLC), becomes a promising indoor positioning technology due to its high accuracy and low cost. This paper provides a comprehensive survey of VLP systems. In particular, since VLC lays the foundation for VLP, we first present a detailed overview of the principles of VLC. The performance of each positioning algorithm is also compared in terms of various metrics such as accuracy, coverage, and orientation limitation. Beyond the physical layer studies, the network design for a VLP system is also investigated, including multi-access technologies resource allocation, and light-emitting diode (LED) placements. Next, the applications of the VLP systems are overviewed. Finally, this paper outlines open issues, challenges, and future research directions for the research field. In a nutshell, this paper constitutes the first holistic survey on VLP from state-of-the-art studies to practical uses.
OFDM-Based Digital Semantic Communication with Importance Awareness
Jan 04, 2024



Semantic communication (SemCom) has received considerable attention for its ability to reduce data transmission size while maintaining task performance. However, existing works mainly focus on analog SemCom with simple channel models, which may limit its practical application. To reduce this gap, we propose an orthogonal frequency division multiplexing (OFDM)-based SemCom system that is compatible with existing digital communication infrastructures. In the considered system, the extracted semantics is quantized by scalar quantizers, transformed into OFDM signal, and then transmitted over the frequency-selective channel. Moreover, we propose a semantic importance measurement method to build the relationship between target task and semantic features. Based on semantic importance, we formulate a sub-carrier and bit allocation problem to maximize communication performance. However, the optimization objective function cannot be accurately characterized using a mathematical expression due to the neural network-based semantic codec. Given the complex nature of the problem, we first propose a low-complexity sub-carrier allocation method that assigns sub-carriers with better channel conditions to more critical semantics. Then, we propose a deep reinforcement learning-based bit allocation algorithm with dynamic action space. Simulation results demonstrate that the proposed system achieves 9.7% and 28.7% performance gains compared to analog SemCom and conventional bit-based communication systems, respectively.