 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTileQ: Efficient Low-Rank Quantization of Mixture-of-Experts with 2D Tiling
May 10, 2026Mixture-of-Experts (MoE) models achieve remarkable performance by sparsely activating specialized experts, yet their massive parameters in experts pose significant challenges for deployment. While low-rank quantization offers a promising route to compress MoE models, existing methods still incur nonnegligible memory overhead and inference latency. To address these limitations, we propose \textsc{TileQ}, a fine-tuning-free post-training quantization (PTQ) method that employs 2D-tiling structured low-rank quantization to share low-rank factors across both input and output dimensions of MoE experts. Furthermore, we introduce an efficient inference technique for \textsc{TileQ} that fuses multiple low-rank expert computations into a single-pass operation, significantly improving hardware utilization. Experiments show that \textsc{TileQ} cuts down additional memory usage up to 10$\times$ and reduces inference latency to $\sim$5\% while preserving state-of-the-art accuracy.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
LibraGen: Playing a Balance Game in Subject-Driven Video Generation
Mar 17, 2026With the advancement of video generation foundation models (VGFMs), customized generation, particularly subject-to-video (S2V), has attracted growing attention. However, a key challenge lies in balancing the intrinsic priors of a VGFM, such as motion coherence, visual aesthetics, and prompt alignment, with its newly derived S2V capability. Existing methods often neglect this balance by enhancing one aspect at the expense of others. To address this, we propose LibraGen, a novel framework that views extending foundation models for S2V generation as a balance game between intrinsic VGFM strengths and S2V capability. Specifically, guided by the core philosophy of "Raising the Fulcrum, Tuning to Balance," we identify data quality as the fulcrum and advocate a quality-over-quantity approach. We construct a hybrid pipeline that combines automated and manual data filtering to improve overall data quality. To further harmonize the VGFM's native capabilities with its S2V extension, we introduce a Tune-to-Balance post-training paradigm. During supervised fine-tuning, both cross-pair and in-pair data are incorporated, and model merging is employed to achieve an effective trade-off. Subsequently, two tailored direct preference optimization (DPO) pipelines, namely Consis-DPO and Real-Fake DPO, are designed and merged to consolidate this balance. During inference, we introduce a time-dependent dynamic classifier-free guidance scheme to enable flexible and fine-grained control. Experimental results demonstrate that LibraGen outperforms both open-source and commercial S2V models using only thousand-scale training data.
BRIGHT: A Collaborative Generalist-Specialist Foundation Model for Breast Pathology
Mar 03, 2026Generalist pathology foundation models (PFMs), pretrained on large-scale multi-organ datasets, have demonstrated remarkable predictive capabilities across diverse clinical applications. However, their proficiency on the full spectrum of clinically essential tasks within a specific organ system remains an open question due to the lack of large-scale validation cohorts for a single organ as well as the absence of a tailored training paradigm that can effectively translate broad histomorphological knowledge into the organ-specific expertise required for specialist-level interpretation. In this study, we propose BRIGHT, the first PFM specifically designed for breast pathology, trained on approximately 210 million histopathology tiles from over 51,000 breast whole-slide images derived from a cohort of over 40,000 patients across 19 hospitals. BRIGHT employs a collaborative generalist-specialist framework to capture both universal and organ-specific features. To comprehensively evaluate the performance of PFMs on breast oncology, we curate the largest multi-institutional cohorts to date for downstream task development and evaluation, comprising over 25,000 WSIs across 10 hospitals. The validation cohorts cover the full spectrum of breast pathology across 24 distinct clinical tasks spanning diagnosis, biomarker prediction, treatment response and survival prediction. Extensive experiments demonstrate that BRIGHT outperforms three leading generalist PFMs, achieving state-of-the-art (SOTA) performance in 21 of 24 internal validation tasks and in 5 of 10 external validation tasks with excellent heatmap interpretability. By evaluating on large-scale validation cohorts, this study not only demonstrates BRIGHT's clinical utility in breast oncology but also validates a collaborative generalist-specialist paradigm, providing a scalable template for developing PFMs on a specific organ system.
LoPRo: Enhancing Low-Rank Quantization via Permuted Block-Wise Rotation
Jan 27, 2026Post-training quantization (PTQ) enables effective model compression while preserving relatively high accuracy. Current weight-only PTQ methods primarily focus on the challenging sub-3-bit regime, where approaches often suffer significant accuracy degradation, typically requiring fine-tuning to achieve competitive performance. In this work, we revisit the fundamental characteristics of weight quantization and analyze the challenges in quantizing the residual matrix under low-rank approximation. We propose LoPRo, a novel fine-tuning-free PTQ algorithm that enhances residual matrix quantization by applying block-wise permutation and Walsh-Hadamard transformations to rotate columns of similar importance, while explicitly preserving the quantization accuracy of the most salient column blocks. Furthermore, we introduce a mixed-precision fast low-rank decomposition based on rank-1 sketch (R1SVD) to further minimize quantization costs. Experiments demonstrate that LoPRo outperforms existing fine-tuning-free PTQ methods at both 2-bit and 3-bit quantization, achieving accuracy comparable to fine-tuning baselines. Specifically, LoPRo achieves state-of-the-art quantization accuracy on LLaMA-2 and LLaMA-3 series models while delivering up to a 4$\times$ speedup. In the MoE model Mixtral-8x7B, LoPRo completes quantization within 2.5 hours, simultaneously reducing perplexity by 0.4$\downarrow$ and improving accuracy by 8\%$\uparrow$. Moreover, compared to other low-rank quantization methods, LoPRo achieves superior accuracy with a significantly lower rank, while maintaining high inference efficiency and minimal additional latency.
FLRQ: Faster LLM Quantization with Flexible Low-Rank Matrix Sketching
Jan 09, 2026Traditional post-training quantization (PTQ) is considered an effective approach to reduce model size and accelerate inference of large-scale language models (LLMs). However, existing low-rank PTQ methods require costly fine-tuning to determine a compromise rank for diverse data and layers in large models, failing to exploit their full potential. Additionally, the current SVD-based low-rank approximation compounds the computational overhead. In this work, we thoroughly analyze the varying effectiveness of low-rank approximation across different layers in representative models. Accordingly, we introduce \underline{F}lexible \underline{L}ow-\underline{R}ank \underline{Q}uantization (FLRQ), a novel solution designed to quickly identify the accuracy-optimal ranks and aggregate them to achieve minimal storage combinations. FLRQ comprises two powerful components, Rank1-Sketch-based Flexible Rank Selection (R1-FLR) and Best Low-rank Approximation under Clipping (BLC). R1-FLR applies the R1-Sketch with Gaussian projection for the fast low-rank approximation, enabling outlier-aware rank extraction for each layer. Meanwhile, BLC aims at minimizing the low-rank quantization error under the scaling and clipping strategy through an iterative method. FLRQ demonstrates strong effectiveness and robustness in comprehensive experiments, achieving state-of-the-art performance in both quantization quality and algorithm efficiency.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
Jun 06, 2024Text attribute person search aims to find specific pedestrians through given textual attributes, which is very meaningful in the scene of searching for designated pedestrians through witness descriptions. The key challenge is the significant modality gap between textual attributes and images. Previous methods focused on achieving explicit representation and alignment through unimodal pre-trained models. Nevertheless, the absence of inter-modality correspondence in these models may lead to distortions in the local information of intra-modality. Moreover, these methods only considered the alignment of inter-modality and ignored the differences between different attribute categories. To mitigate the above problems, we propose an Attribute-Aware Implicit Modality Alignment (AIMA) framework to learn the correspondence of local representations between textual attributes and images and combine global representation matching to narrow the modality gap. Firstly, we introduce the CLIP model as the backbone and design prompt templates to transform attribute combinations into structured sentences. This facilitates the model's ability to better understand and match image details. Next, we design a Masked Attribute Prediction (MAP) module that predicts the masked attributes after the interaction of image and masked textual attribute features through multi-modal interaction, thereby achieving implicit local relationship alignment. Finally, we propose an Attribute-IoU Guided Intra-Modal Contrastive (A-IoU IMC) loss, aligning the distribution of different textual attributes in the embedding space with their IoU distribution, achieving better semantic arrangement. Extensive experiments on the Market-1501 Attribute, PETA, and PA100K datasets show that the performance of our proposed method significantly surpasses the current state-of-the-art methods.
Deep Multi-Scale U-Net Architecture and Noise-Robust Training Strategies for Histopathological Image Segmentation
May 03, 2022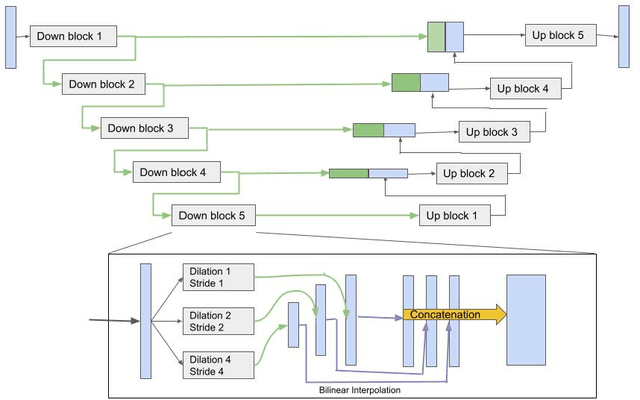
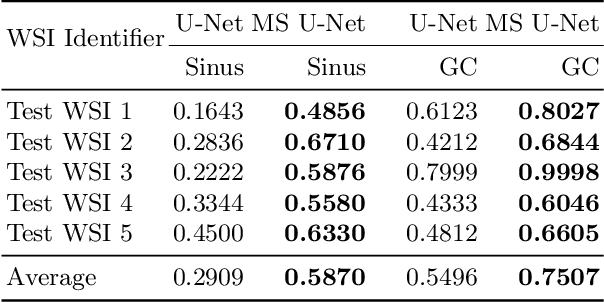

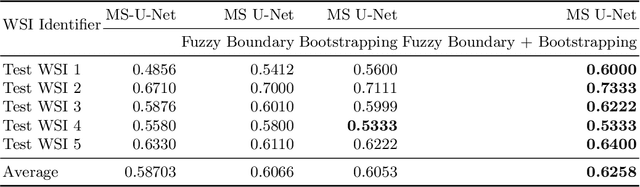
Although the U-Net architecture has been extensively used for segmentation of medical images, we address two of its shortcomings in this work. Firstly, the accuracy of vanilla U-Net degrades when the target regions for segmentation exhibit significant variations in shape and size. Even though the U-Net already possesses some capability to analyze features at various scales, we propose to explicitly add multi-scale feature maps in each convolutional module of the U-Net encoder to improve segmentation of histology images. Secondly, the accuracy of a U-Net model also suffers when the annotations for supervised learning are noisy or incomplete. This can happen due to the inherent difficulty for a human expert to identify and delineate all instances of specific pathology very precisely and accurately. We address this challenge by introducing auxiliary confidence maps that emphasize less on the boundaries of the given target regions. Further, we utilize the bootstrapping properties of the deep network to address the missing annotation problem intelligently. In our experiments on a private dataset of breast cancer lymph nodes, where the primary task was to segment germinal centres and sinus histiocytosis, we observed substantial improvement over a U-Net baseline based on the two proposed augmentations.
Task-Oriented Semantic Communication Systems Based on Extended Rate-Distortion Theory
Jan 26, 2022


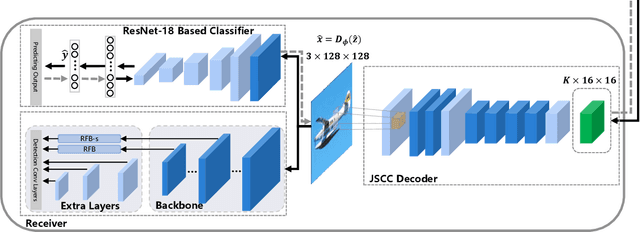
Considering the performance of intelligent task during signal exchange can help the communication system to automatically select those semantic parts which are helpful to perform the target task for compression and reconstruction, which can both greatly reduce the redundancy in signal and ensure the performance of the task. The traditional communication system based on rate-distortion theory treats all the information in the signal equally, but ignores their different importance to accomplish the task, which leads to waste of communication resources. In this paper, combined with the information bottleneck method, we present an extended rate-distortion theory which considers both concise representation and semantic distortion. Based on this theory, a task-oriented semantic image communication system is proposed. In order to verify that the proposed system can achieve performance improvement on different intelligent tasks, we apply the basic system trained with classification task to the system with object detection as the target task. The experimental results demonstrate that the proposed method outperforms the traditional and multi-task based communication system in terms of task performance at the same signal compression degree and noise interference degree. Furthermore, it is necessary to consider a compromise between rate-distortion theory and information bottleneck theory by comparing the pure rate-distortion scheme and the pure IB scheme.