 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Spectral Characteristics for Single Image Reflection Removal
Sep 16, 2025



Eliminating reflections caused by incident light interacting with reflective medium remains an ill-posed problem in the image restoration area. The primary challenge arises from the overlapping of reflection and transmission components in the captured images, which complicates the task of accurately distinguishing and recovering the clean background. Existing approaches typically address reflection removal solely in the image domain, ignoring the spectral property variations of reflected light, which hinders their ability to effectively discern reflections. In this paper, we start with a new perspective on spectral learning, and propose the Spectral Codebook to reconstruct the optical spectrum of the reflection image. The reflections can be effectively distinguished by perceiving the wavelength differences between different light sources in the spectrum. To leverage the reconstructed spectrum, we design two spectral prior refinement modules to re-distribute pixels in the spatial dimension and adaptively enhance the spectral differences along the wavelength dimension. Furthermore, we present the Spectrum-Aware Transformer to jointly recover the transmitted content in spectral and pixel domains. Experimental results on three different reflection benchmarks demonstrate the superiority and generalization ability of our method compared to state-of-the-art models.
TSAL: Few-shot Text Segmentation Based on Attribute Learning
Apr 15, 2025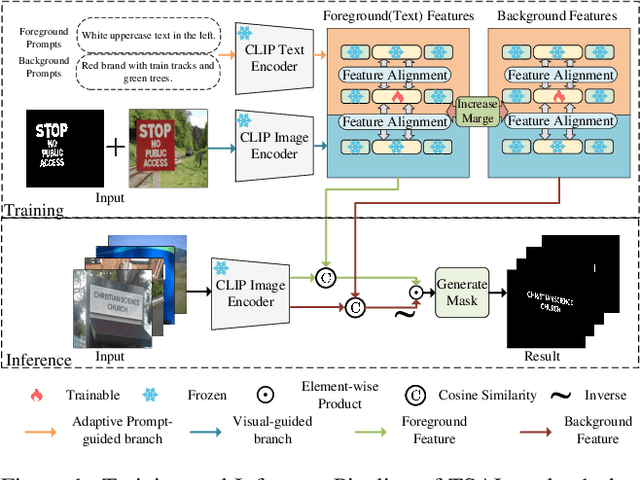
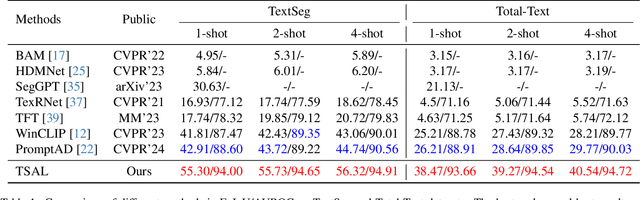
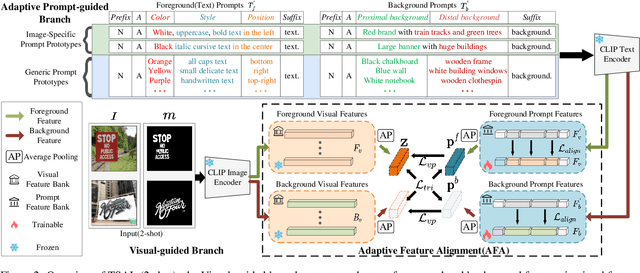
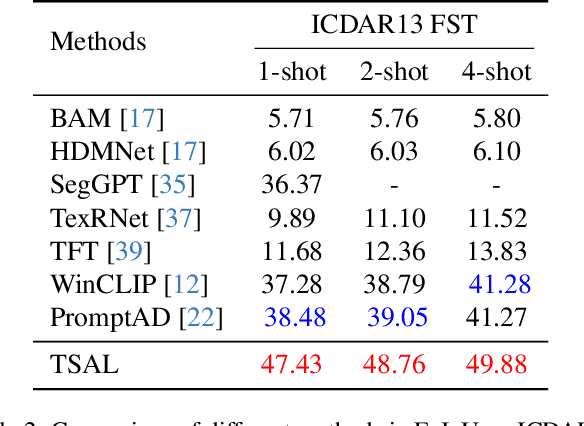
Recently supervised learning rapidly develops in scene text segmentation. However, the lack of high-quality datasets and the high cost of pixel annotation greatly limit the development of them. Considering the well-performed few-shot learning methods for downstream tasks, we investigate the application of the few-shot learning method to scene text segmentation. We propose TSAL, which leverages CLIP's prior knowledge to learn text attributes for segmentation. To fully utilize the semantic and texture information in the image, a visual-guided branch is proposed to separately extract text and background features. To reduce data dependency and improve text detection accuracy, the adaptive prompt-guided branch employs effective adaptive prompt templates to capture various text attributes. To enable adaptive prompts capture distinctive text features and complex background distribution, we propose Adaptive Feature Alignment module(AFA). By aligning learnable tokens of different attributes with visual features and prompt prototypes, AFA enables adaptive prompts to capture both general and distinctive attribute information. TSAL can capture the unique attributes of text and achieve precise segmentation using only few images. Experiments demonstrate that our method achieves SOTA performance on multiple text segmentation datasets under few-shot settings and show great potential in text-related domains.
QueryCDR: Query-based Controllable Distortion Rectification Network for Fisheye Images
Dec 18, 2024Fisheye image rectification aims to correct distortions in images taken with fisheye cameras. Although current models show promising results on images with a similar degree of distortion as the training data, they will produce sub-optimal results when the degree of distortion changes and without retraining. The lack of generalization ability for dealing with varying degrees of distortion limits their practical application. In this paper, we take one step further to enable effective distortion rectification for images with varying degrees of distortion without retraining. We propose a novel Query-based Controllable Distortion Rectification network for fisheye images (QueryCDR). In particular, we first present the Distortion-aware Learnable Query Mechanism (DLQM), which defines the latent spatial relationships for different distortion degrees as a series of learnable queries. Each query can be learned to obtain position-dependent rectification control conditions, providing control over the rectification process. Then, we propose two kinds of controllable modulating blocks to enable the control conditions to guide the modulation of the distortion features better. These core components cooperate with each other to effectively boost the generalization ability of the model at varying degrees of distortion. Extensive experiments on fisheye image datasets with different distortion degrees demonstrate our approach achieves high-quality and controllable distortion rectification.
Disentangle and denoise: Tackling context misalignment for video moment retrieval
Aug 14, 2024Video Moment Retrieval, which aims to locate in-context video moments according to a natural language query, is an essential task for cross-modal grounding. Existing methods focus on enhancing the cross-modal interactions between all moments and the textual description for video understanding. However, constantly interacting with all locations is unreasonable because of uneven semantic distribution across the timeline and noisy visual backgrounds. This paper proposes a cross-modal Context Denoising Network (CDNet) for accurate moment retrieval by disentangling complex correlations and denoising irrelevant dynamics.Specifically, we propose a query-guided semantic disentanglement (QSD) to decouple video moments by estimating alignment levels according to the global and fine-grained correlation. A Context-aware Dynamic Denoisement (CDD) is proposed to enhance understanding of aligned spatial-temporal details by learning a group of query-relevant offsets. Extensive experiments on public benchmarks demonstrate that the proposed CDNet achieves state-of-the-art performances.
Exploiting Inter-Image Similarity Prior for Low-Bitrate Remote Sensing Image Compression
Jul 17, 2024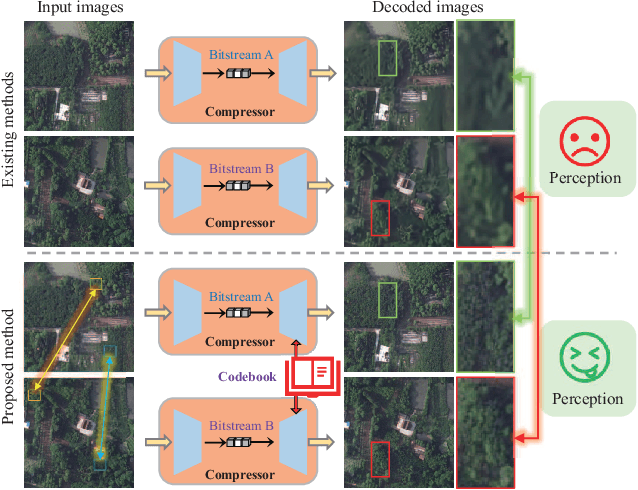

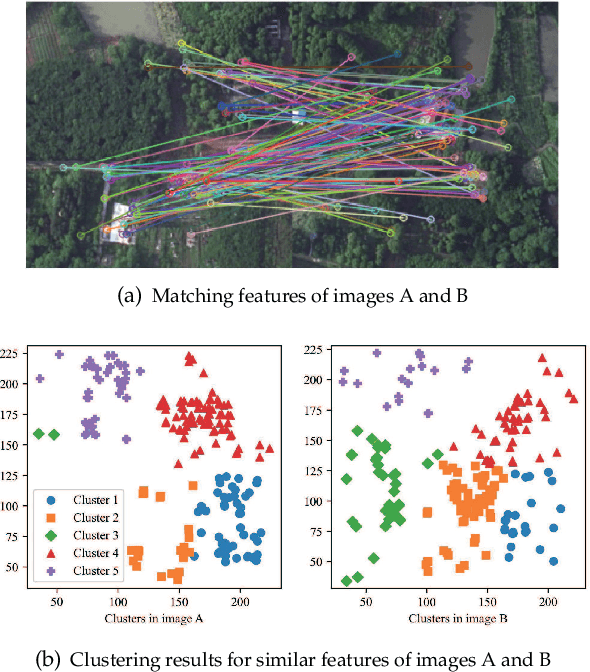

Deep learning-based methods have garnered significant attention in remote sensing (RS) image compression due to their superior performance. Most of these methods focus on enhancing the coding capability of the compression network and improving entropy model prediction accuracy. However, they typically compress and decompress each image independently, ignoring the significant inter-image similarity prior. In this paper, we propose a codebook-based RS image compression (Code-RSIC) method with a generated discrete codebook, which is deployed at the decoding end of a compression algorithm to provide inter-image similarity prior. Specifically, we first pretrain a high-quality discrete codebook using the competitive generation model VQGAN. We then introduce a Transformer-based prediction model to align the latent features of the decoded images from an existing compression algorithm with the frozen high-quality codebook. Finally, we develop a hierarchical prior integration network (HPIN), which mainly consists of Transformer blocks and multi-head cross-attention modules (MCMs) that can query hierarchical prior from the codebook, thus enhancing the ability of the proposed method to decode texture-rich RS images. Extensive experimental results demonstrate that the proposed Code-RSIC significantly outperforms state-of-the-art traditional and learning-based image compression algorithms in terms of perception quality. The code will be available at \url{https://github.com/mlkk518/Code-RSIC/
LDM-RSIC: Exploring Distortion Prior with Latent Diffusion Models for Remote Sensing Image Compression
Jun 06, 2024Deep learning-based image compression algorithms typically focus on designing encoding and decoding networks and improving the accuracy of entropy model estimation to enhance the rate-distortion (RD) performance. However, few algorithms leverage the compression distortion prior from existing compression algorithms to improve RD performance. In this paper, we propose a latent diffusion model-based remote sensing image compression (LDM-RSIC) method, which aims to enhance the final decoding quality of RS images by utilizing the generated distortion prior from a LDM. Our approach consists of two stages. In the first stage, a self-encoder learns prior from the high-quality input image. In the second stage, the prior is generated through an LDM, conditioned on the decoded image of an existing learning-based image compression algorithm, to be used as auxiliary information for generating the texture-rich enhanced image. To better utilize the prior, a channel attention and gate-based dynamic feature attention module (DFAM) is embedded into a Transformer-based multi-scale enhancement network (MEN) for image enhancement. Extensive experiments demonstrate the proposed LDM-RSIC significantly outperforms existing state-of-the-art traditional and learning-based image compression algorithms in terms of both subjective perception and objective metrics. Additionally, we use the LDM-based scheme to improve the traditional image compression algorithm JPEG2000 and obtain 32.00% bit savings on the DOTA testing set. The code will be available at https://github.com/mlkk518/LDM-RSIC.
Enhancing Perception Quality in Remote Sensing Image Compression via Invertible Neural Network
May 17, 2024



Decoding remote sensing images to achieve high perceptual quality, particularly at low bitrates, remains a significant challenge. To address this problem, we propose the invertible neural network-based remote sensing image compression (INN-RSIC) method. Specifically, we capture compression distortion from an existing image compression algorithm and encode it as a set of Gaussian-distributed latent variables via INN. This ensures that the compression distortion in the decoded image becomes independent of the ground truth. Therefore, by leveraging the inverse mapping of INN, we can input the decoded image along with a set of randomly resampled Gaussian distributed variables into the inverse network, effectively generating enhanced images with better perception quality. To effectively learn compression distortion, channel expansion, Haar transformation, and invertible blocks are employed to construct the INN. Additionally, we introduce a quantization module (QM) to mitigate the impact of format conversion, thus enhancing the framework's generalization and improving the perceptual quality of enhanced images. Extensive experiments demonstrate that our INN-RSIC significantly outperforms the existing state-of-the-art traditional and deep learning-based image compression methods in terms of perception quality.
CRS-Diff: Controllable Generative Remote Sensing Foundation Model
Mar 25, 2024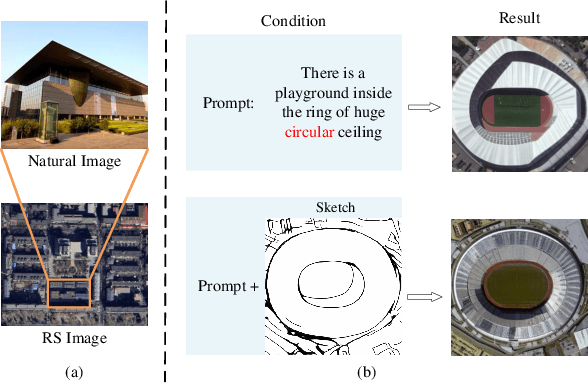

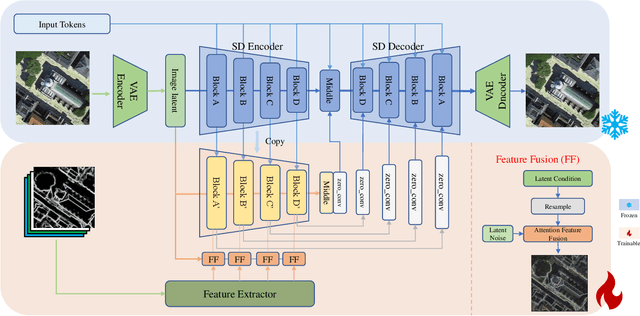

The emergence of diffusion models has revolutionized the field of image generation, providing new methods for creating high-quality, high-resolution images across various applications. However, the potential of these models for generating domain-specific images, particularly remote sensing (RS) images, remains largely untapped. RS images that are notable for their high resolution, extensive coverage, and rich information content, bring new challenges that general diffusion models may not adequately address. This paper proposes CRS-Diff, a pioneering diffusion modeling framework specifically tailored for generating remote sensing imagery, leveraging the inherent advantages of diffusion models while integrating advanced control mechanisms to ensure that the imagery is not only visually clear but also enriched with geographic and temporal information. The model integrates global and local control inputs, enabling precise combinations of generation conditions to refine the generation process. A comprehensive evaluation of CRS-Diff has demonstrated its superior capability to generate RS imagery both in a single condition and multiple conditions compared with previous methods in terms of image quality and diversity.
Dual Degradation-Inspired Deep Unfolding Network for Low-Light Image Enhancement
Aug 05, 2023



Although low-light image enhancement has achieved great stride based on deep enhancement models, most of them mainly stress on enhancement performance via an elaborated black-box network and rarely explore the physical significance of enhancement models. Towards this issue, we propose a Dual degrAdation-inSpired deep Unfolding network, termed DASUNet, for low-light image enhancement. Specifically, we construct a dual degradation model (DDM) to explicitly simulate the deterioration mechanism of low-light images. It learns two distinct image priors via considering degradation specificity between luminance and chrominance spaces. To make the proposed scheme tractable, we design an alternating optimization solution to solve the proposed DDM. Further, the designed solution is unfolded into a specified deep network, imitating the iteration updating rules, to form DASUNet. Local and long-range information are obtained by prior modeling module (PMM), inheriting the advantages of convolution and Transformer, to enhance the representation capability of dual degradation priors. Additionally, a space aggregation module (SAM) is presented to boost the interaction of two degradation models. Extensive experiments on multiple popular low-light image datasets validate the effectiveness of DASUNet compared to canonical state-of-the-art low-light image enhancement methods. Our source code and pretrained model will be publicly available.
Division Gets Better: Learning Brightness-Aware and Detail-Sensitive Representations for Low-Light Image Enhancement
Jul 18, 2023Low-light image enhancement strives to improve the contrast, adjust the visibility, and restore the distortion in color and texture. Existing methods usually pay more attention to improving the visibility and contrast via increasing the lightness of low-light images, while disregarding the significance of color and texture restoration for high-quality images. Against above issue, we propose a novel luminance and chrominance dual branch network, termed LCDBNet, for low-light image enhancement, which divides low-light image enhancement into two sub-tasks, e.g., luminance adjustment and chrominance restoration. Specifically, LCDBNet is composed of two branches, namely luminance adjustment network (LAN) and chrominance restoration network (CRN). LAN takes responsibility for learning brightness-aware features leveraging long-range dependency and local attention correlation. While CRN concentrates on learning detail-sensitive features via multi-level wavelet decomposition. Finally, a fusion network is designed to blend their learned features to produce visually impressive images. Extensive experiments conducted on seven benchmark datasets validate the effectiveness of our proposed LCDBNet, and the results manifest that LCDBNet achieves superior performance in terms of multiple reference/non-reference quality evaluators compared to other state-of-the-art competitors. Our code and pretrained model will be available.