 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataEvolver: Let Your Data Build and Improve Itself via Goal-Driven Loop Agents
May 03, 2026Constructing controllable visual data is a major bottleneck for image editing and multimodal understanding. Useful supervision is rarely produced by a single rendering pass; instead it emerges through iterative generation, inspection, correction, filtering, and export. We present DataEvolver, a closed-loop visual data engine that organizes this process around explicit goals, persistent artifacts, bounded corrective actions, and acceptance decisions. DataEvolver supports multiple artifact types, including RGB images, masks, depth maps, normal maps, meshes, poses, trajectories, and review traces. In the current release, the system operates through two coupled loops: generation-time self-correction within each sample and validation-time self-expansion across dataset rounds. We validate the framework on an image-level object-rotation setting. With a fixed Qwen-Edit LoRA probe, our final Ours+DualGate model outperforms both the unadapted base model and a public multi-angle LoRA on SpatialEdit and a held-out evaluation set. Ablations show a consistent improvement path from scene-aware generation to feedback-driven correction and dual-gated validation. Beyond the released rotation data, our main contribution is a reusable framework for building visual datasets through explicit goal tracking, review, correction, and acceptance loops.
Boosting Robust AIGI Detection with LoRA-based Pairwise Training
Apr 14, 2026The proliferation of highly realistic AI-Generated Image (AIGI) has necessitated the development of practical detection methods. While current AIGI detectors perform admirably on clean datasets, their detection performance frequently decreases when deployed "in the wild", where images are subjected to unpredictable, complex distortions. To resolve the critical vulnerability, we propose a novel LoRA-based Pairwise Training (LPT) strategy designed specifically to achieve robust detection for AIGI under severe distortions. The core of our strategy involves the targeted finetuning of a visual foundation model, the deliberate simulation of data distribution during the training phase, and a unique pairwise training process. Specifically, we introduce distortion and size simulations to better fit the distribution from the validation and test sets. Based on the strong visual representation capability of the visual foundation model, we finetune the model to achieve AIGI detection. The pairwise training is utilized to improve the detection via decoupling the generalization and robustness optimization. Experiments show that our approach secured the 3th placement in the NTIRE Robust AI-Generated Image Detection in the Wild challenge
WAT: Online Video Understanding Needs Watching Before Thinking
Mar 12, 2026Multimodal Large Language Models (MLLMs) have shown strong capabilities in image understanding, motivating recent efforts to extend them to video reasoning. However, existing Video LLMs struggle in online streaming scenarios, where long temporal context must be preserved under strict memory constraints. We propose WAT (Watching Before Thinking), a two-stage framework for online video reasoning. WAT separates processing into a query-independent watching stage and a query-triggered thinking stage. The watching stage builds a hierarchical memory system with a Short-Term Memory (STM) that buffers recent frames and a fixed-capacity Long-Term Memory (LTM) that maintains a diverse summary of historical content using a redundancy-aware eviction policy. In the thinking stage, a context-aware retrieval mechanism combines the query with the current STM context to retrieve relevant historical frames from the LTM for cross-temporal reasoning. To support training for online video tasks, we introduce WAT-85K, a dataset containing streaming-style annotations emphasizing real-time perception, backward tracing, and forecasting. Experiments show that WAT achieves state-of-the-art performance on online video benchmarks, including 77.7% accuracy on StreamingBench and 55.2% on OVO-Bench, outperforming existing open-source online Video LLMs while operating at real-time frame rates.
Benchmarking Semantic Segmentation Models via Appearance and Geometry Attribute Editing
Mar 02, 2026Semantic segmentation takes pivotal roles in various applications such as autonomous driving and medical image analysis. When deploying segmentation models in practice, it is critical to test their behaviors in varied and complex scenes in advance. In this paper, we construct an automatic data generation pipeline Gen4Seg to stress-test semantic segmentation models by generating various challenging samples with different attribute changes. Beyond previous evaluation paradigms focusing solely on global weather and style transfer, we investigate variations in both appearance and geometry attributes at the object and image level. These include object color, material, size, position, as well as image-level variations such as weather and style. To achieve this, we propose to edit visual attributes of existing real images with precise control of structural information, empowered by diffusion models. In this way, the existing segmentation labels can be reused for the edited images, which greatly reduces the labor costs. Using our pipeline, we construct two new benchmarks, Pascal-EA and COCO-EA. We benchmark a wide variety of semantic segmentation models, spanning from closed-set models to open-vocabulary large models. We have several key findings: 1) advanced open-vocabulary models do not exhibit greater robustness compared to closed-set methods under geometric variations; 2) data augmentation techniques, such as CutOut and CutMix, are limited in enhancing robustness against appearance variations; 3) our pipeline can also be employed as a data augmentation tool and improve both in-distribution and out-of-distribution performances. Our work suggests the potential of generative models as effective tools for automatically analyzing segmentation models, and we hope our findings will assist practitioners and researchers in developing more robust and reliable segmentation models.
Geometric Image Editing via Effects-Sensitive In-Context Inpainting with Diffusion Transformers
Feb 09, 2026Recent advances in diffusion models have significantly improved image editing. However, challenges persist in handling geometric transformations, such as translation, rotation, and scaling, particularly in complex scenes. Existing approaches suffer from two main limitations: (1) difficulty in achieving accurate geometric editing of object translation, rotation, and scaling; (2) inadequate modeling of intricate lighting and shadow effects, leading to unrealistic results. To address these issues, we propose GeoEdit, a framework that leverages in-context generation through a diffusion transformer module, which integrates geometric transformations for precise object edits. Moreover, we introduce Effects-Sensitive Attention, which enhances the modeling of intricate lighting and shadow effects for improved realism. To further support training, we construct RS-Objects, a large-scale geometric editing dataset containing over 120,000 high-quality image pairs, enabling the model to learn precise geometric editing while generating realistic lighting and shadows. Extensive experiments on public benchmarks demonstrate that GeoEdit consistently outperforms state-of-the-art methods in terms of visual quality, geometric accuracy, and realism.
ReasonTabQA: A Comprehensive Benchmark for Table Question Answering from Real World Industrial Scenarios
Jan 12, 2026Recent advancements in Large Language Models (LLMs) have significantly catalyzed table-based question answering (TableQA). However, existing TableQA benchmarks often overlook the intricacies of industrial scenarios, which are characterized by multi-table structures, nested headers, and massive scales. These environments demand robust table reasoning through deep structured inference, presenting a significant challenge that remains inadequately addressed by current methodologies. To bridge this gap, we present ReasonTabQA, a large-scale bilingual benchmark encompassing 1,932 tables across 30 industry domains such as energy and automotive. ReasonTabQA provides high-quality annotations for both final answers and explicit reasoning chains, supporting both thinking and no-thinking paradigms. Furthermore, we introduce TabCodeRL, a reinforcement learning method that leverages table-aware verifiable rewards to guide the generation of logical reasoning paths. Extensive experiments on ReasonTabQA and 4 TableQA datasets demonstrate that while TabCodeRL yields substantial performance gains on open-source LLMs, the persistent performance gap on ReasonTabQA underscores the inherent complexity of real-world industrial TableQA.
MR-UIE: Multi-Perspective Reasoning with Reinforcement Learning for Universal Information Extraction
Sep 11, 2025Large language models (LLMs) demonstrate robust capabilities across diverse research domains. However, their performance in universal information extraction (UIE) remains insufficient, especially when tackling structured output scenarios that involve complex schema descriptions and require multi-step reasoning. While existing approaches enhance the performance of LLMs through in-context learning and instruction tuning, significant limitations nonetheless persist. To enhance the model's generalization ability, we propose integrating reinforcement learning (RL) with multi-perspective reasoning for information extraction (IE) tasks. Our work transitions LLMs from passive extractors to active reasoners, enabling them to understand not only what to extract but also how to reason. Experiments conducted on multiple IE benchmarks demonstrate that MR-UIE consistently elevates extraction accuracy across domains and surpasses state-of-the-art methods on several datasets. Furthermore, incorporating multi-perspective reasoning into RL notably enhances generalization in complex IE tasks, underscoring the critical role of reasoning in challenging scenarios.
TELEVAL: A Dynamic Benchmark Designed for Spoken Language Models in Chinese Interactive Scenarios
Jul 24, 2025Spoken language models (SLMs) have seen rapid progress in recent years, along with the development of numerous benchmarks for evaluating their performance. However, most existing benchmarks primarily focus on evaluating whether SLMs can perform complex tasks comparable to those tackled by large language models (LLMs), often failing to align with how users naturally interact in real-world conversational scenarios. In this paper, we propose TELEVAL, a dynamic benchmark specifically designed to evaluate SLMs' effectiveness as conversational agents in realistic Chinese interactive settings. TELEVAL defines three evaluation dimensions: Explicit Semantics, Paralinguistic and Implicit Semantics, and System Abilities. It adopts a dialogue format consistent with real-world usage and evaluates text and audio outputs separately. TELEVAL particularly focuses on the model's ability to extract implicit cues from user speech and respond appropriately without additional instructions. Our experiments demonstrate that despite recent progress, existing SLMs still have considerable room for improvement in natural conversational tasks. We hope that TELEVAL can serve as a user-centered evaluation framework that directly reflects the user experience and contributes to the development of more capable dialogue-oriented SLMs.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
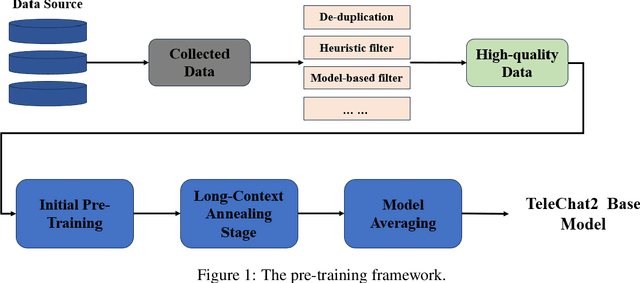

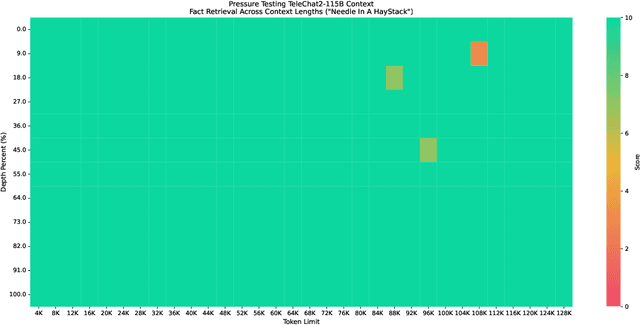
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
BoSS: Beyond-Semantic Speech
Jul 23, 2025Human communication involves more than explicit semantics, with implicit signals and contextual cues playing a critical role in shaping meaning. However, modern speech technologies, such as Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) often fail to capture these beyond-semantic dimensions. To better characterize and benchmark the progression of speech intelligence, we introduce Spoken Interaction System Capability Levels (L1-L5), a hierarchical framework illustrated the evolution of spoken dialogue systems from basic command recognition to human-like social interaction. To support these advanced capabilities, we propose Beyond-Semantic Speech (BoSS), which refers to the set of information in speech communication that encompasses but transcends explicit semantics. It conveys emotions, contexts, and modifies or extends meanings through multidimensional features such as affective cues, contextual dynamics, and implicit semantics, thereby enhancing the understanding of communicative intentions and scenarios. We present a formalized framework for BoSS, leveraging cognitive relevance theories and machine learning models to analyze temporal and contextual speech dynamics. We evaluate BoSS-related attributes across five different dimensions, reveals that current spoken language models (SLMs) are hard to fully interpret beyond-semantic signals. These findings highlight the need for advancing BoSS research to enable richer, more context-aware human-machine communication.