 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Conversational Agents via Task-Oriented Adversarial Memory Adaptation
Jan 29, 2026Conversational agents struggle to handle long conversations due to context window limitations. Therefore, memory systems are developed to leverage essential historical information. Existing memory systems typically follow a pipeline of offline memory construction and update, and online retrieval. Despite the flexible online phase, the offline phase remains fixed and task-independent. In this phase, memory construction operates under a predefined workflow and fails to emphasize task relevant information. Meanwhile, memory updates are guided by generic metrics rather than task specific supervision. This leads to a misalignment between offline memory preparation and task requirements, which undermines downstream task performance. To this end, we propose an Adversarial Memory Adaptation mechanism (AMA) that aligns memory construction and update with task objectives by simulating task execution. Specifically, first, a challenger agent generates question answer pairs based on the original dialogues. The constructed memory is then used to answer these questions, simulating downstream inference. Subsequently, an evaluator agent assesses the responses and performs error analysis. Finally, an adapter agent analyzes the error cases and performs dual level updates on both the construction strategy and the content. Through this process, the memory system receives task aware supervision signals in advance during the offline phase, enhancing its adaptability to downstream tasks. AMA can be integrated into various existing memory systems, and extensive experiments on long dialogue benchmark LoCoMo demonstrate its effectiveness.
Exploring Spectral Characteristics for Single Image Reflection Removal
Sep 16, 2025



Eliminating reflections caused by incident light interacting with reflective medium remains an ill-posed problem in the image restoration area. The primary challenge arises from the overlapping of reflection and transmission components in the captured images, which complicates the task of accurately distinguishing and recovering the clean background. Existing approaches typically address reflection removal solely in the image domain, ignoring the spectral property variations of reflected light, which hinders their ability to effectively discern reflections. In this paper, we start with a new perspective on spectral learning, and propose the Spectral Codebook to reconstruct the optical spectrum of the reflection image. The reflections can be effectively distinguished by perceiving the wavelength differences between different light sources in the spectrum. To leverage the reconstructed spectrum, we design two spectral prior refinement modules to re-distribute pixels in the spatial dimension and adaptively enhance the spectral differences along the wavelength dimension. Furthermore, we present the Spectrum-Aware Transformer to jointly recover the transmitted content in spectral and pixel domains. Experimental results on three different reflection benchmarks demonstrate the superiority and generalization ability of our method compared to state-of-the-art models.
Learning Deblurring Texture Prior from Unpaired Data with Diffusion Model
Jul 18, 2025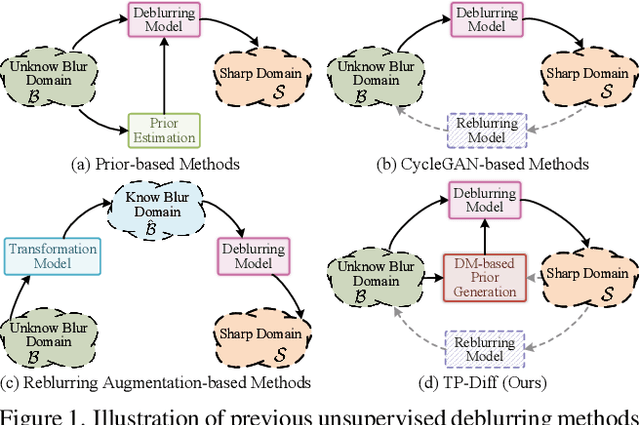
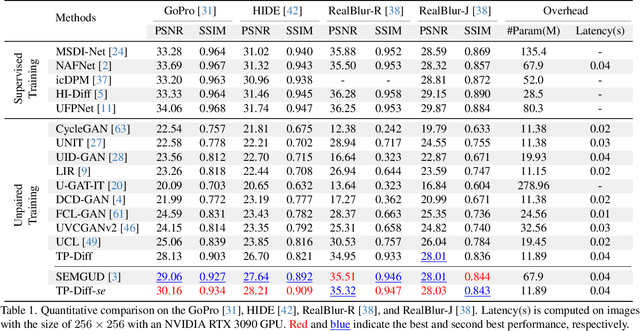
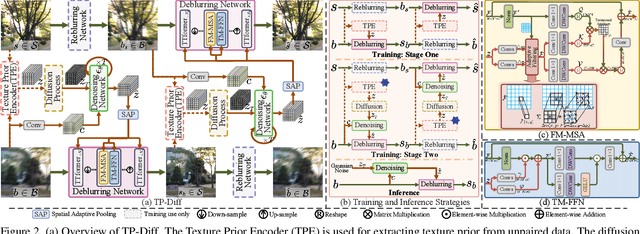
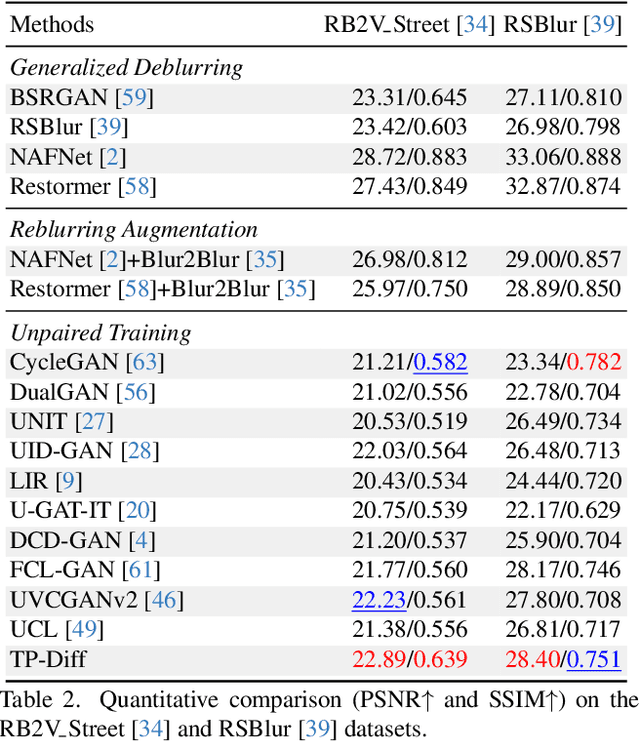
Since acquiring large amounts of realistic blurry-sharp image pairs is difficult and expensive, learning blind image deblurring from unpaired data is a more practical and promising solution. Unfortunately, dominant approaches rely heavily on adversarial learning to bridge the gap from blurry domains to sharp domains, ignoring the complex and unpredictable nature of real-world blur patterns. In this paper, we propose a novel diffusion model (DM)-based framework, dubbed \ours, for image deblurring by learning spatially varying texture prior from unpaired data. In particular, \ours performs DM to generate the prior knowledge that aids in recovering the textures of blurry images. To implement this, we propose a Texture Prior Encoder (TPE) that introduces a memory mechanism to represent the image textures and provides supervision for DM training. To fully exploit the generated texture priors, we present the Texture Transfer Transformer layer (TTformer), in which a novel Filter-Modulated Multi-head Self-Attention (FM-MSA) efficiently removes spatially varying blurring through adaptive filtering. Furthermore, we implement a wavelet-based adversarial loss to preserve high-frequency texture details. Extensive evaluations show that \ours provides a promising unsupervised deblurring solution and outperforms SOTA methods in widely-used benchmarks.
Frequency Domain-Based Diffusion Model for Unpaired Image Dehazing
Jul 02, 2025Unpaired image dehazing has attracted increasing attention due to its flexible data requirements during model training. Dominant methods based on contrastive learning not only introduce haze-unrelated content information, but also ignore haze-specific properties in the frequency domain (\ie,~haze-related degradation is mainly manifested in the amplitude spectrum). To address these issues, we propose a novel frequency domain-based diffusion model, named \ours, for fully exploiting the beneficial knowledge in unpaired clear data. In particular, inspired by the strong generative ability shown by Diffusion Models (DMs), we tackle the dehazing task from the perspective of frequency domain reconstruction and perform the DMs to yield the amplitude spectrum consistent with the distribution of clear images. To implement it, we propose an Amplitude Residual Encoder (ARE) to extract the amplitude residuals, which effectively compensates for the amplitude gap from the hazy to clear domains, as well as provide supervision for the DMs training. In addition, we propose a Phase Correction Module (PCM) to eliminate artifacts by further refining the phase spectrum during dehazing with a simple attention mechanism. Experimental results demonstrate that our \ours outperforms other state-of-the-art methods on both synthetic and real-world datasets.
TSAL: Few-shot Text Segmentation Based on Attribute Learning
Apr 15, 2025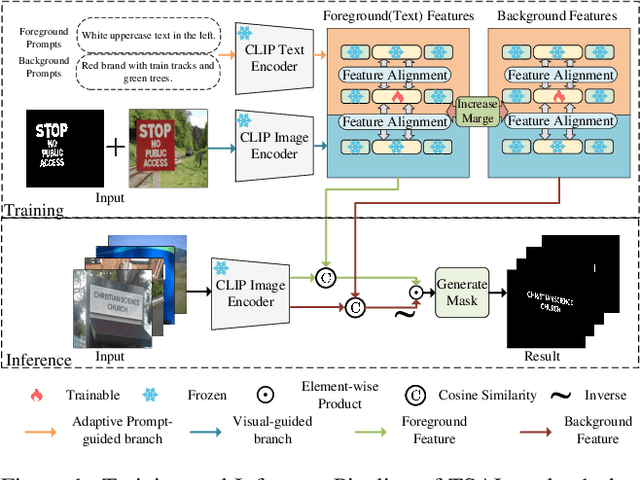
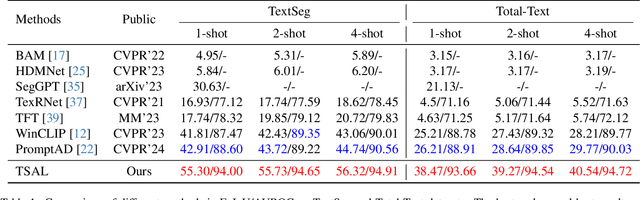
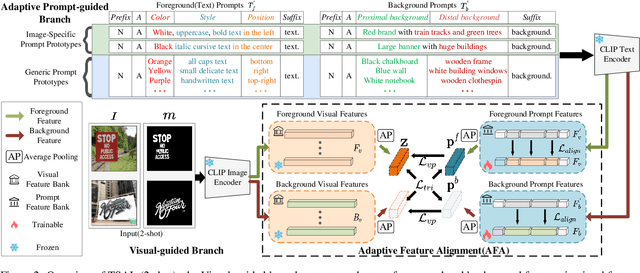
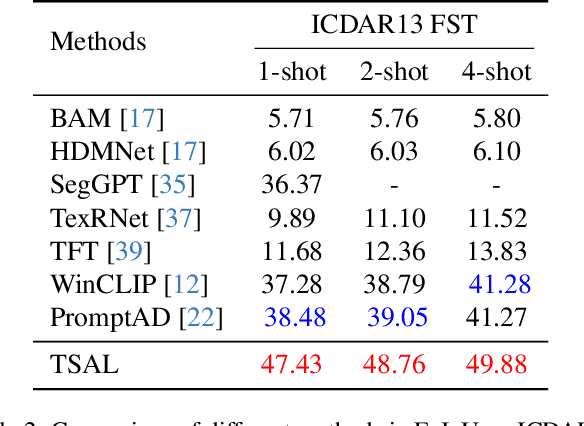
Recently supervised learning rapidly develops in scene text segmentation. However, the lack of high-quality datasets and the high cost of pixel annotation greatly limit the development of them. Considering the well-performed few-shot learning methods for downstream tasks, we investigate the application of the few-shot learning method to scene text segmentation. We propose TSAL, which leverages CLIP's prior knowledge to learn text attributes for segmentation. To fully utilize the semantic and texture information in the image, a visual-guided branch is proposed to separately extract text and background features. To reduce data dependency and improve text detection accuracy, the adaptive prompt-guided branch employs effective adaptive prompt templates to capture various text attributes. To enable adaptive prompts capture distinctive text features and complex background distribution, we propose Adaptive Feature Alignment module(AFA). By aligning learnable tokens of different attributes with visual features and prompt prototypes, AFA enables adaptive prompts to capture both general and distinctive attribute information. TSAL can capture the unique attributes of text and achieve precise segmentation using only few images. Experiments demonstrate that our method achieves SOTA performance on multiple text segmentation datasets under few-shot settings and show great potential in text-related domains.
QueryCDR: Query-based Controllable Distortion Rectification Network for Fisheye Images
Dec 18, 2024Fisheye image rectification aims to correct distortions in images taken with fisheye cameras. Although current models show promising results on images with a similar degree of distortion as the training data, they will produce sub-optimal results when the degree of distortion changes and without retraining. The lack of generalization ability for dealing with varying degrees of distortion limits their practical application. In this paper, we take one step further to enable effective distortion rectification for images with varying degrees of distortion without retraining. We propose a novel Query-based Controllable Distortion Rectification network for fisheye images (QueryCDR). In particular, we first present the Distortion-aware Learnable Query Mechanism (DLQM), which defines the latent spatial relationships for different distortion degrees as a series of learnable queries. Each query can be learned to obtain position-dependent rectification control conditions, providing control over the rectification process. Then, we propose two kinds of controllable modulating blocks to enable the control conditions to guide the modulation of the distortion features better. These core components cooperate with each other to effectively boost the generalization ability of the model at varying degrees of distortion. Extensive experiments on fisheye image datasets with different distortion degrees demonstrate our approach achieves high-quality and controllable distortion rectification.
AdaDiffSR: Adaptive Region-aware Dynamic Acceleration Diffusion Model for Real-World Image Super-Resolution
Oct 23, 2024
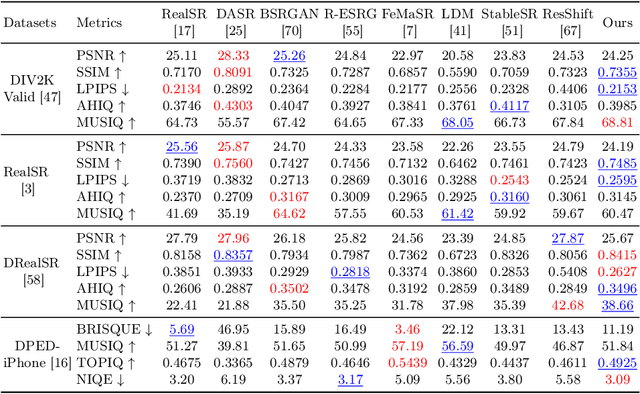
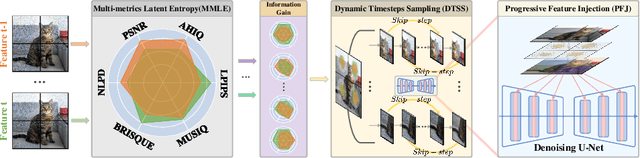
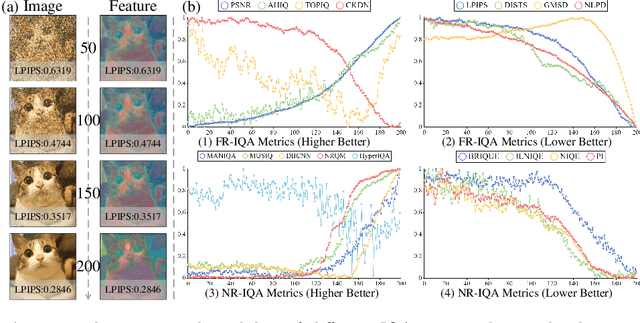
Diffusion models (DMs) have shown promising results on single-image super-resolution and other image-to-image translation tasks. Benefiting from more computational resources and longer inference times, they are able to yield more realistic images. Existing DMs-based super-resolution methods try to achieve an overall average recovery over all regions via iterative refinement, ignoring the consideration that different input image regions require different timesteps to reconstruct. In this work, we notice that previous DMs-based super-resolution methods suffer from wasting computational resources to reconstruct invisible details. To further improve the utilization of computational resources, we propose AdaDiffSR, a DMs-based SR pipeline with dynamic timesteps sampling strategy (DTSS). Specifically, by introducing the multi-metrics latent entropy module (MMLE), we can achieve dynamic perception of the latent spatial information gain during the denoising process, thereby guiding the dynamic selection of the timesteps. In addition, we adopt a progressive feature injection module (PFJ), which dynamically injects the original image features into the denoising process based on the current information gain, so as to generate images with both fidelity and realism. Experiments show that our AdaDiffSR achieves comparable performance over current state-of-the-art DMs-based SR methods while consuming less computational resources and inference time on both synthetic and real-world datasets.
Motion-adaptive Separable Collaborative Filters for Blind Motion Deblurring
Apr 19, 2024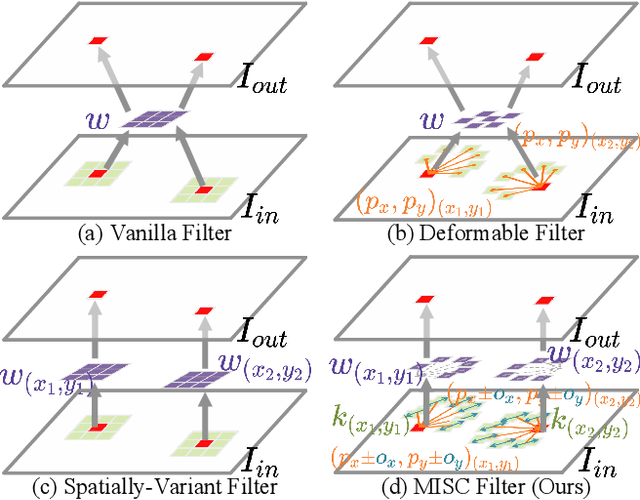
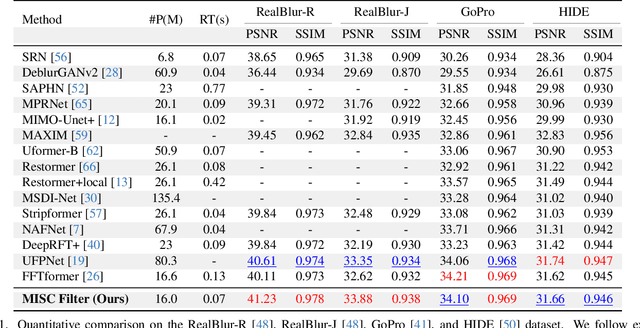
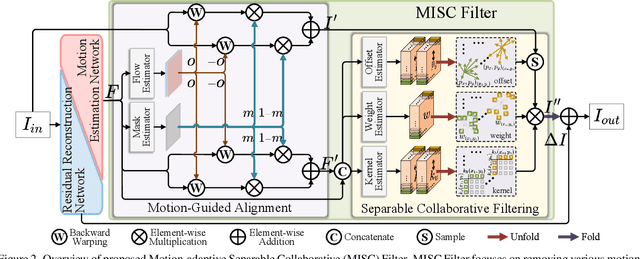
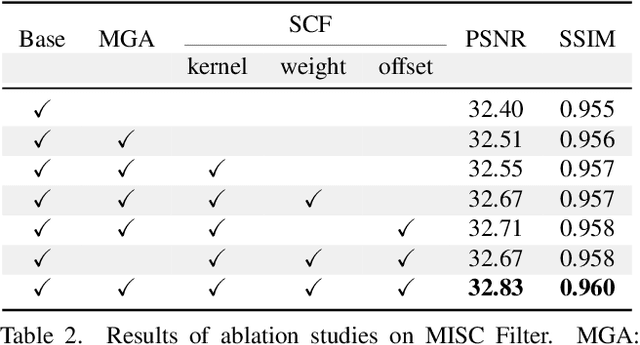
Eliminating image blur produced by various kinds of motion has been a challenging problem. Dominant approaches rely heavily on model capacity to remove blurring by reconstructing residual from blurry observation in feature space. These practices not only prevent the capture of spatially variable motion in the real world but also ignore the tailored handling of various motions in image space. In this paper, we propose a novel real-world deblurring filtering model called the Motion-adaptive Separable Collaborative (MISC) Filter. In particular, we use a motion estimation network to capture motion information from neighborhoods, thereby adaptively estimating spatially-variant motion flow, mask, kernels, weights, and offsets to obtain the MISC Filter. The MISC Filter first aligns the motion-induced blurring patterns to the motion middle along the predicted flow direction, and then collaboratively filters the aligned image through the predicted kernels, weights, and offsets to generate the output. This design can handle more generalized and complex motion in a spatially differentiated manner. Furthermore, we analyze the relationships between the motion estimation network and the residual reconstruction network. Extensive experiments on four widely used benchmarks demonstrate that our method provides an effective solution for real-world motion blur removal and achieves state-of-the-art performance. Code is available at https://github.com/ChengxuLiu/MISCFilter
Decoupling Degradations with Recurrent Network for Video Restoration in Under-Display Camera
Mar 08, 2024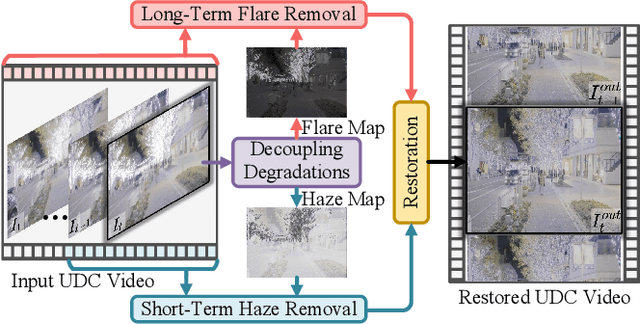
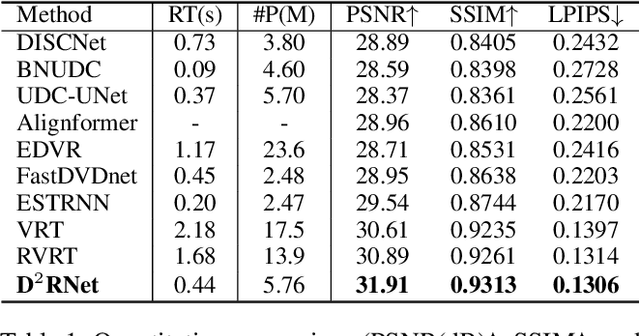
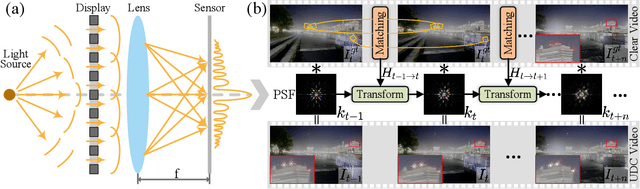

Under-display camera (UDC) systems are the foundation of full-screen display devices in which the lens mounts under the display. The pixel array of light-emitting diodes used for display diffracts and attenuates incident light, causing various degradations as the light intensity changes. Unlike general video restoration which recovers video by treating different degradation factors equally, video restoration for UDC systems is more challenging that concerns removing diverse degradation over time while preserving temporal consistency. In this paper, we introduce a novel video restoration network, called D$^2$RNet, specifically designed for UDC systems. It employs a set of Decoupling Attention Modules (DAM) that effectively separate the various video degradation factors. More specifically, a soft mask generation function is proposed to formulate each frame into flare and haze based on the diffraction arising from incident light of different intensities, followed by the proposed flare and haze removal components that leverage long- and short-term feature learning to handle the respective degradations. Such a design offers an targeted and effective solution to eliminating various types of degradation in UDC systems. We further extend our design into multi-scale to overcome the scale-changing of degradation that often occur in long-range videos. To demonstrate the superiority of D$^2$RNet, we propose a large-scale UDC video benchmark by gathering HDR videos and generating realistically degraded videos using the point spread function measured by a commercial UDC system. Extensive quantitative and qualitative evaluations demonstrate the superiority of D$^2$RNet compared to other state-of-the-art video restoration and UDC image restoration methods. Code is available at https://github.com/ChengxuLiu/DDRNet.git
4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement
Sep 05, 2022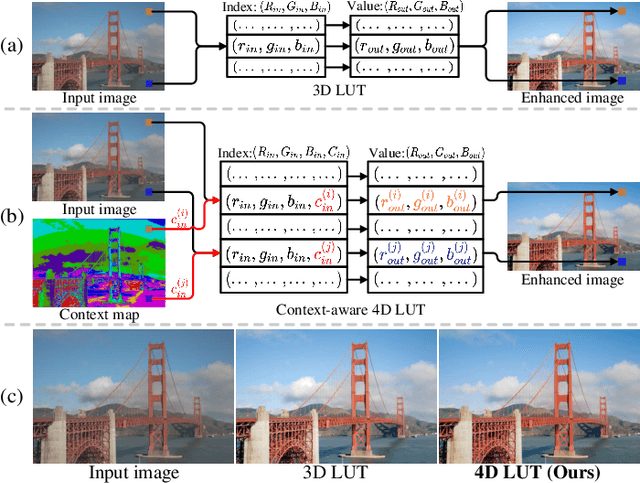
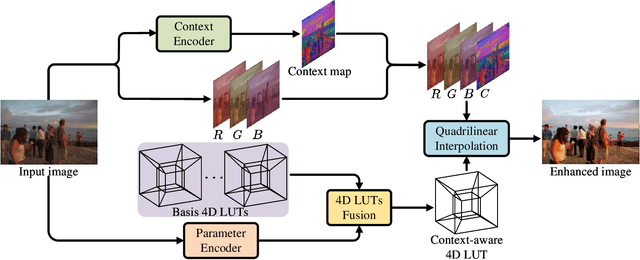


Image enhancement aims at improving the aesthetic visual quality of photos by retouching the color and tone, and is an essential technology for professional digital photography. Recent years deep learning-based image enhancement algorithms have achieved promising performance and attracted increasing popularity. However, typical efforts attempt to construct a uniform enhancer for all pixels' color transformation. It ignores the pixel differences between different content (e.g., sky, ocean, etc.) that are significant for photographs, causing unsatisfactory results. In this paper, we propose a novel learnable context-aware 4-dimensional lookup table (4D LUT), which achieves content-dependent enhancement of different contents in each image via adaptively learning of photo context. In particular, we first introduce a lightweight context encoder and a parameter encoder to learn a context map for the pixel-level category and a group of image-adaptive coefficients, respectively. Then, the context-aware 4D LUT is generated by integrating multiple basis 4D LUTs via the coefficients. Finally, the enhanced image can be obtained by feeding the source image and context map into fused context-aware 4D~LUT via quadrilinear interpolation. Compared with traditional 3D LUT, i.e., RGB mapping to RGB, which is usually used in camera imaging pipeline systems or tools, 4D LUT, i.e., RGBC(RGB+Context) mapping to RGB, enables finer control of color transformations for pixels with different content in each image, even though they have the same RGB values. Experimental results demonstrate that our method outperforms other state-of-the-art methods in widely-used benchmarks.