 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Inverse Perspective Mapping for Automatic Vectorized Road Map Generation
Jan 27, 2026In this study, we present a low-cost and unified framework for vectorized road mapping leveraging enhanced inverse perspective mapping (IPM). In this framework, Catmull-Rom splines are utilized to characterize lane lines, and all the other ground markings are depicted using polygons uniformly. The results from instance segmentation serve as references to refine the three-dimensional position of spline control points and polygon corner points. In conjunction with this process, the homography matrix of IPM and vehicle poses are optimized simultaneously. Our proposed framework significantly reduces the mapping errors associated with IPM. It also improves the accuracy of the initial IPM homography matrix and the predicted vehicle poses. Furthermore, it addresses the limitations imposed by the coplanarity assumption in IPM. These enhancements enable IPM to be effectively applied to vectorized road mapping, which serves a cost-effective solution with enhanced accuracy. In addition, our framework generalizes road map elements to include all common ground markings and lane lines. The proposed framework is evaluated in two different practical scenarios, and the test results show that our method can automatically generate high-precision maps with near-centimeter-level accuracy. Importantly, the optimized IPM matrix achieves an accuracy comparable to that of manual calibration, while the accuracy of vehicle poses is also significantly improved.
Enhancing Campus Mobility: Achievements and Challenges of Autonomous Shuttle "Snow Lion''
Jan 17, 2024The rapid evolution of autonomous vehicles (AVs) has significantly influenced global transportation systems. In this context, we present ``Snow Lion'', an autonomous shuttle meticulously designed to revolutionize on-campus transportation, offering a safer and more efficient mobility solution for students, faculty, and visitors. The primary objective of this research is to enhance campus mobility by providing a reliable, efficient, and eco-friendly transportation solution that seamlessly integrates with existing infrastructure and meets the diverse needs of a university setting. To achieve this goal, we delve into the intricacies of the system design, encompassing sensing, perception, localization, planning, and control aspects. We evaluate the autonomous shuttle's performance in real-world scenarios, involving a 1146-kilometer road haul and the transportation of 442 passengers over a two-month period. These experiments demonstrate the effectiveness of our system and offer valuable insights into the intricate process of integrating an autonomous vehicle within campus shuttle operations. Furthermore, a thorough analysis of the lessons derived from this experience furnishes a valuable real-world case study, accompanied by recommendations for future research and development in the field of autonomous driving.
Every Dataset Counts: Scaling up Monocular 3D Object Detection with Joint Datasets Training
Oct 02, 2023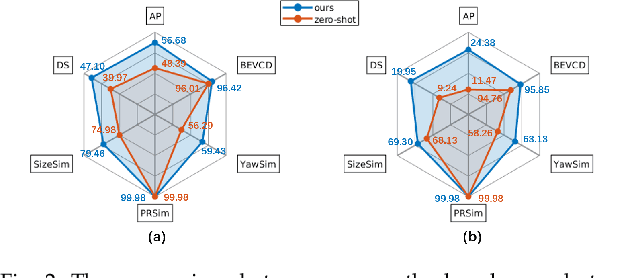
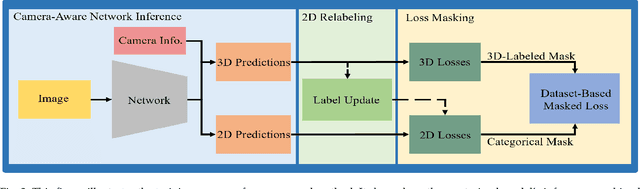


Monocular 3D object detection plays a crucial role in autonomous driving. However, existing monocular 3D detection algorithms depend on 3D labels derived from LiDAR measurements, which are costly to acquire for new datasets and challenging to deploy in novel environments. Specifically, this study investigates the pipeline for training a monocular 3D object detection model on a diverse collection of 3D and 2D datasets. The proposed framework comprises three components: (1) a robust monocular 3D model capable of functioning across various camera settings, (2) a selective-training strategy to accommodate datasets with differing class annotations, and (3) a pseudo 3D training approach using 2D labels to enhance detection performance in scenes containing only 2D labels. With this framework, we could train models on a joint set of various open 3D/2D datasets to obtain models with significantly stronger generalization capability and enhanced performance on new dataset with only 2D labels. We conduct extensive experiments on KITTI/nuScenes/ONCE/Cityscapes/BDD100K datasets to demonstrate the scaling ability of the proposed method.
Dual Degradation-Inspired Deep Unfolding Network for Low-Light Image Enhancement
Aug 05, 2023



Although low-light image enhancement has achieved great stride based on deep enhancement models, most of them mainly stress on enhancement performance via an elaborated black-box network and rarely explore the physical significance of enhancement models. Towards this issue, we propose a Dual degrAdation-inSpired deep Unfolding network, termed DASUNet, for low-light image enhancement. Specifically, we construct a dual degradation model (DDM) to explicitly simulate the deterioration mechanism of low-light images. It learns two distinct image priors via considering degradation specificity between luminance and chrominance spaces. To make the proposed scheme tractable, we design an alternating optimization solution to solve the proposed DDM. Further, the designed solution is unfolded into a specified deep network, imitating the iteration updating rules, to form DASUNet. Local and long-range information are obtained by prior modeling module (PMM), inheriting the advantages of convolution and Transformer, to enhance the representation capability of dual degradation priors. Additionally, a space aggregation module (SAM) is presented to boost the interaction of two degradation models. Extensive experiments on multiple popular low-light image datasets validate the effectiveness of DASUNet compared to canonical state-of-the-art low-light image enhancement methods. Our source code and pretrained model will be publicly available.
Division Gets Better: Learning Brightness-Aware and Detail-Sensitive Representations for Low-Light Image Enhancement
Jul 18, 2023Low-light image enhancement strives to improve the contrast, adjust the visibility, and restore the distortion in color and texture. Existing methods usually pay more attention to improving the visibility and contrast via increasing the lightness of low-light images, while disregarding the significance of color and texture restoration for high-quality images. Against above issue, we propose a novel luminance and chrominance dual branch network, termed LCDBNet, for low-light image enhancement, which divides low-light image enhancement into two sub-tasks, e.g., luminance adjustment and chrominance restoration. Specifically, LCDBNet is composed of two branches, namely luminance adjustment network (LAN) and chrominance restoration network (CRN). LAN takes responsibility for learning brightness-aware features leveraging long-range dependency and local attention correlation. While CRN concentrates on learning detail-sensitive features via multi-level wavelet decomposition. Finally, a fusion network is designed to blend their learned features to produce visually impressive images. Extensive experiments conducted on seven benchmark datasets validate the effectiveness of our proposed LCDBNet, and the results manifest that LCDBNet achieves superior performance in terms of multiple reference/non-reference quality evaluators compared to other state-of-the-art competitors. Our code and pretrained model will be available.
V2HDM-Mono: A Framework of Building a Marking-Level HD Map with One or More Monocular Cameras
Sep 16, 2022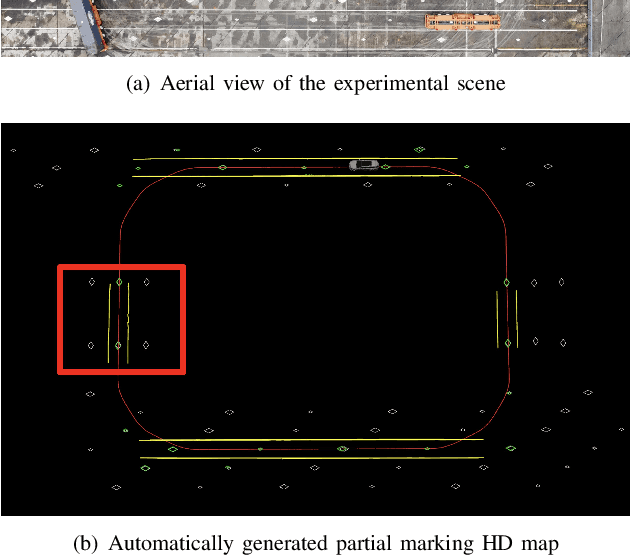
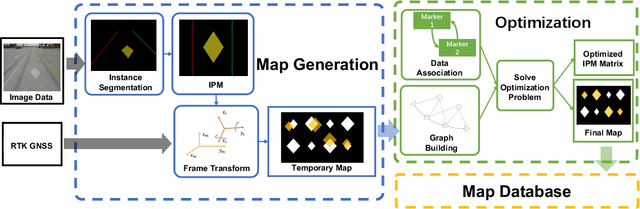

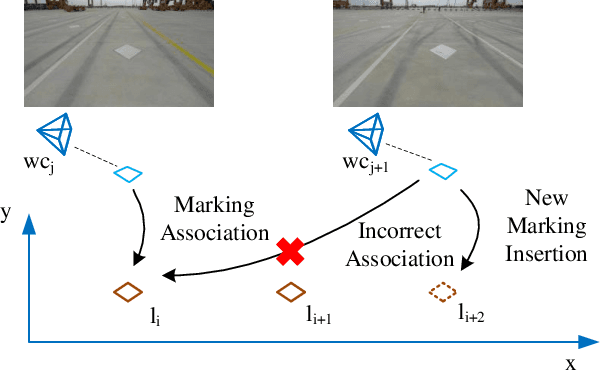
Marking-level high-definition maps (HD maps) are of great significance for autonomous vehicles, especially in large-scale, appearance-changing scenarios where autonomous vehicles rely on markings for localization and lanes for safe driving. In this paper, we propose a highly feasible framework for automatically building a marking-level HD map using a simple sensor setup (one or more monocular cameras). We optimize the position of the marking corners to fit the result of marking segmentation and simultaneously optimize the inverse perspective mapping (IPM) matrix of the corresponding camera to obtain an accurate transformation from the front view image to the bird's-eye view (BEV). In the quantitative evaluation, the built HD map almost attains centimeter-level accuracy. The accuracy of the optimized IPM matrix is similar to that of the manual calibration. The method can also be generalized to build HD maps in a broader sense by increasing the types of recognizable markings.