 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Inverse Perspective Mapping for Automatic Vectorized Road Map Generation
Jan 27, 2026In this study, we present a low-cost and unified framework for vectorized road mapping leveraging enhanced inverse perspective mapping (IPM). In this framework, Catmull-Rom splines are utilized to characterize lane lines, and all the other ground markings are depicted using polygons uniformly. The results from instance segmentation serve as references to refine the three-dimensional position of spline control points and polygon corner points. In conjunction with this process, the homography matrix of IPM and vehicle poses are optimized simultaneously. Our proposed framework significantly reduces the mapping errors associated with IPM. It also improves the accuracy of the initial IPM homography matrix and the predicted vehicle poses. Furthermore, it addresses the limitations imposed by the coplanarity assumption in IPM. These enhancements enable IPM to be effectively applied to vectorized road mapping, which serves a cost-effective solution with enhanced accuracy. In addition, our framework generalizes road map elements to include all common ground markings and lane lines. The proposed framework is evaluated in two different practical scenarios, and the test results show that our method can automatically generate high-precision maps with near-centimeter-level accuracy. Importantly, the optimized IPM matrix achieves an accuracy comparable to that of manual calibration, while the accuracy of vehicle poses is also significantly improved.
NetRoller: Interfacing General and Specialized Models for End-to-End Autonomous Driving
Jun 17, 2025Integrating General Models (GMs) such as Large Language Models (LLMs), with Specialized Models (SMs) in autonomous driving tasks presents a promising approach to mitigating challenges in data diversity and model capacity of existing specialized driving models. However, this integration leads to problems of asynchronous systems, which arise from the distinct characteristics inherent in GMs and SMs. To tackle this challenge, we propose NetRoller, an adapter that incorporates a set of novel mechanisms to facilitate the seamless integration of GMs and specialized driving models. Specifically, our mechanisms for interfacing the asynchronous GMs and SMs are organized into three key stages. NetRoller first harvests semantically rich and computationally efficient representations from the reasoning processes of LLMs using an early stopping mechanism, which preserves critical insights on driving context while maintaining low overhead. It then applies learnable query embeddings, nonsensical embeddings, and positional layer embeddings to facilitate robust and efficient cross-modality translation. At last, it employs computationally efficient Query Shift and Feature Shift mechanisms to enhance the performance of SMs through few-epoch fine-tuning. Based on the mechanisms formalized in these three stages, NetRoller enables specialized driving models to operate at their native frequencies while maintaining situational awareness of the GM. Experiments conducted on the nuScenes dataset demonstrate that integrating GM through NetRoller significantly improves human similarity and safety in planning tasks, and it also achieves noticeable precision improvements in detection and mapping tasks for end-to-end autonomous driving. The code and models are available at https://github.com/Rex-sys-hk/NetRoller .
MGCBS: An Optimal and Efficient Algorithm for Solving Multi-Goal Multi-Agent Path Finding Problem
Apr 30, 2024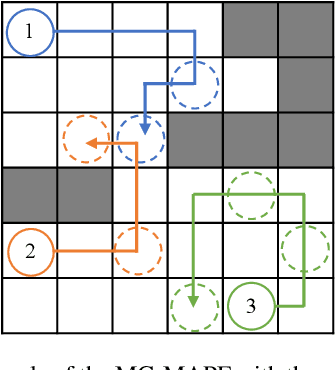
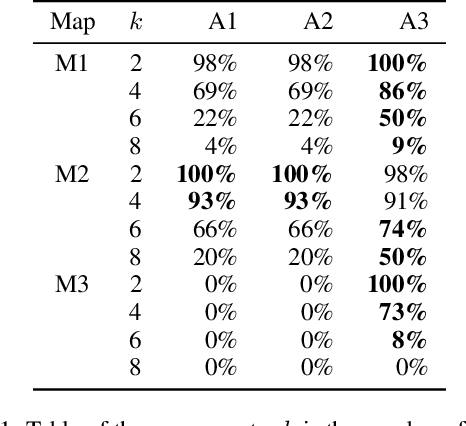
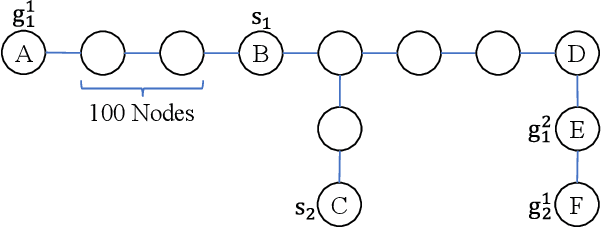
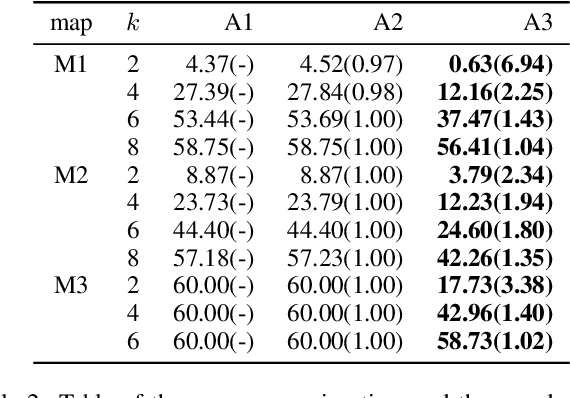
With the expansion of the scale of robotics applications, the multi-goal multi-agent pathfinding (MG-MAPF) problem began to gain widespread attention. This problem requires each agent to visit pre-assigned multiple goal points at least once without conflict. Some previous methods have been proposed to solve the MG-MAPF problem based on Decoupling the goal Vertex visiting order search and the Single-agent pathfinding (DVS). However, this paper demonstrates that the methods based on DVS cannot always obtain the optimal solution. To obtain the optimal result, we propose the Multi-Goal Conflict-Based Search (MGCBS), which is based on Decoupling the goal Safe interval visiting order search and the Single-agent pathfinding (DSS). Additionally, we present the Time-Interval-Space Forest (TIS Forest) to enhance the efficiency of MGCBS by maintaining the shortest paths from any start point at any start time step to each safe interval at the goal points. The experiment demonstrates that our method can consistently obtain optimal results and execute up to 7 times faster than the state-of-the-art method in our evaluation.
A Generic Trajectory Planning Method for Constrained All-Wheel-Steering Robots
Apr 15, 2024This paper presents a trajectory planning method for wheeled robots with fixed steering axes while the steering angle of each wheel is constrained. In the past, All-Wheel-Steering(AWS) robots, incorporating modes such as rotation-free translation maneuvers, in-situ rotational maneuvers, and proportional steering, exhibited inefficient performance due to time-consuming mode switches. This inefficiency arises from wheel rotation constraints and inter-wheel cooperation requirements. The direct application of a holonomic moving strategy can lead to significant slip angles or even structural failure. Additionally, the limited steering range of AWS wheeled robots exacerbates nonlinearity issues, thereby complicating control processes. To address these challenges, we developed a novel planning method termed Constrained AWS(C-AWS), which integrates second-order discrete search with predictive control techniques. Experimental results demonstrate that our method adeptly generates feasible and smooth trajectories for C-AWS while adhering to steering angle constraints.
DHP-Mapping: A Dense Panoptic Mapping System with Hierarchical World Representation and Label Optimization Techniques
Mar 25, 2024
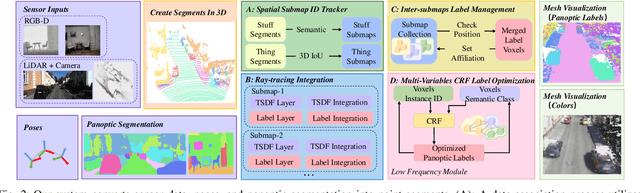
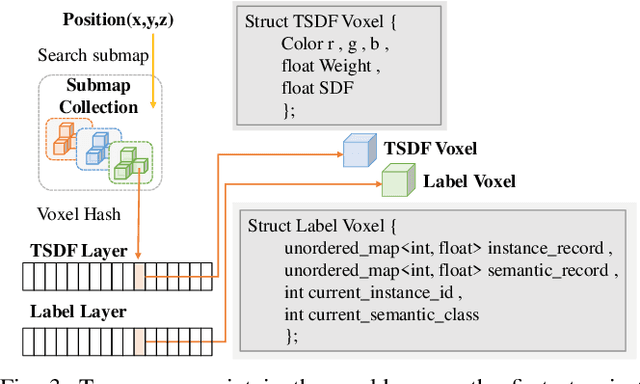
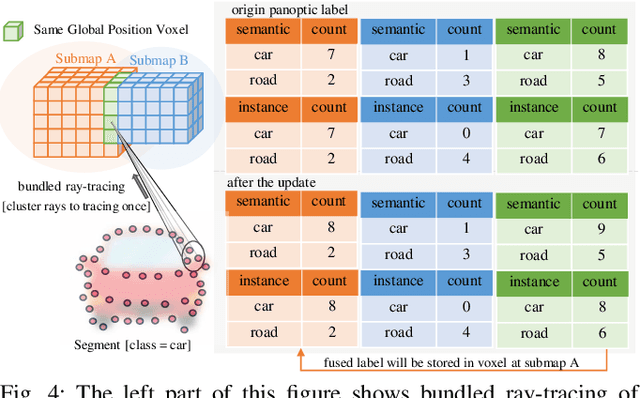
Maps provide robots with crucial environmental knowledge, thereby enabling them to perform interactive tasks effectively. Easily accessing accurate abstract-to-detailed geometric and semantic concepts from maps is crucial for robots to make informed and efficient decisions. To comprehensively model the environment and effectively manage the map data structure, we propose DHP-Mapping, a dense mapping system that utilizes multiple Truncated Signed Distance Field (TSDF) submaps and panoptic labels to hierarchically model the environment. The output map is able to maintain both voxel- and submap-level metric and semantic information. Two modules are presented to enhance the mapping efficiency and label consistency: (1) an inter-submaps label fusion strategy to eliminate duplicate points across submaps and (2) a conditional random field (CRF) based approach to enhance panoptic labels through object label comprehension and contextual information. We conducted experiments with two public datasets including indoor and outdoor scenarios. Our system performs comparably to state-of-the-art (SOTA) methods across geometry and label accuracy evaluation metrics. The experiment results highlight the effectiveness and scalability of our system, as it is capable of constructing precise geometry and maintaining consistent panoptic labels. Our code is publicly available at https://github.com/hutslib/DHP-Mapping.
Enhancing Campus Mobility: Achievements and Challenges of Autonomous Shuttle "Snow Lion''
Jan 17, 2024The rapid evolution of autonomous vehicles (AVs) has significantly influenced global transportation systems. In this context, we present ``Snow Lion'', an autonomous shuttle meticulously designed to revolutionize on-campus transportation, offering a safer and more efficient mobility solution for students, faculty, and visitors. The primary objective of this research is to enhance campus mobility by providing a reliable, efficient, and eco-friendly transportation solution that seamlessly integrates with existing infrastructure and meets the diverse needs of a university setting. To achieve this goal, we delve into the intricacies of the system design, encompassing sensing, perception, localization, planning, and control aspects. We evaluate the autonomous shuttle's performance in real-world scenarios, involving a 1146-kilometer road haul and the transportation of 442 passengers over a two-month period. These experiments demonstrate the effectiveness of our system and offer valuable insights into the intricate process of integrating an autonomous vehicle within campus shuttle operations. Furthermore, a thorough analysis of the lessons derived from this experience furnishes a valuable real-world case study, accompanied by recommendations for future research and development in the field of autonomous driving.
SoloPose: One-Shot Kinematic 3D Human Pose Estimation with Video Data Augmentation
Dec 15, 2023While recent two-stage many-to-one deep learning models have demonstrated great success in 3D human pose estimation, such models are inefficient ways to detect 3D key points in a sequential video relative to one-shot and many-to-many models. Another key drawback of two-stage and many-to-one models is that errors in the first stage will be passed onto the second stage. In this paper, we introduce SoloPose, a novel one-shot, many-to-many spatio-temporal transformer model for kinematic 3D human pose estimation of video. SoloPose is further fortified by HeatPose, a 3D heatmap based on Gaussian Mixture Model distributions that factors target key points as well as kinematically adjacent key points. Finally, we address data diversity constraints with the 3D AugMotion Toolkit, a methodology to augment existing 3D human pose datasets, specifically by projecting four top public 3D human pose datasets (Humans3.6M, MADS, AIST Dance++, MPI INF 3DHP) into a novel dataset (Humans7.1M) with a universal coordinate system. Extensive experiments are conducted on Human3.6M as well as the augmented Humans7.1M dataset, and SoloPose demonstrates superior results relative to the state-of-the-art approaches.
IR-STP: Enhancing Autonomous Driving with Interaction Reasoning in Spatio-Temporal Planning
Nov 06, 2023



Considerable research efforts have been devoted to the development of motion planning algorithms, which form a cornerstone of the autonomous driving system (ADS). However, obtaining an interactive and secure trajectory for the ADS remains a formidable task, especially in scenarios with significant interaction complexities. Many contemporary prediction-based planning methods frequently overlook interaction modeling, leading to less effective planning performance. This paper introduces a novel prediction-based interactive planning framework that explicitly and mathematically models interactions among traffic entities during the planning process. Our method incorporates interaction reasoning into spatio-temporal (s-t) planning by defining interaction conditions and constraints. Furthermore, it records and continually updates interaction relations for each planned state throughout the forward search. We assess the performance of our approach alongside state-of-the-art methods using a series of experiments conducted in both single and multi-modal scenarios. These experiments encompass variations in the accuracy of prediction outcomes and different degrees of planner aggressiveness. The experimental findings demonstrate the effectiveness and robustness of our method, yielding insights applicable to the wider field of autonomous driving. For the community's reference, our code is accessible at https://github.com/ChenYingbing/IR-STP-Planner.
MoEmo Vision Transformer: Integrating Cross-Attention and Movement Vectors in 3D Pose Estimation for HRI Emotion Detection
Oct 15, 2023Emotion detection presents challenges to intelligent human-robot interaction (HRI). Foundational deep learning techniques used in emotion detection are limited by information-constrained datasets or models that lack the necessary complexity to learn interactions between input data elements, such as the the variance of human emotions across different contexts. In the current effort, we introduce 1) MoEmo (Motion to Emotion), a cross-attention vision transformer (ViT) for human emotion detection within robotics systems based on 3D human pose estimations across various contexts, and 2) a data set that offers full-body videos of human movement and corresponding emotion labels based on human gestures and environmental contexts. Compared to existing approaches, our method effectively leverages the subtle connections between movement vectors of gestures and environmental contexts through the use of cross-attention on the extracted movement vectors of full-body human gestures/poses and feature maps of environmental contexts. We implement a cross-attention fusion model to combine movement vectors and environment contexts into a joint representation to derive emotion estimation. Leveraging our Naturalistic Motion Database, we train the MoEmo system to jointly analyze motion and context, yielding emotion detection that outperforms the current state-of-the-art.
* IEEE/RSJ International Conference on Intelligent Robots (IROS), Detroit, Michigan
An Efficient Approach to the Online Multi-Agent Path Finding Problem by Using Sustainable Information
Jan 11, 2023Multi-agent path finding (MAPF) is the problem of moving agents to the goal vertex without collision. In the online MAPF problem, new agents may be added to the environment at any time, and the current agents have no information about future agents. The inability of existing online methods to reuse previous planning contexts results in redundant computation and reduces algorithm efficiency. Hence, we propose a three-level approach to solve online MAPF utilizing sustainable information, which can decrease its redundant calculations. The high-level solver, the Sustainable Replan algorithm (SR), manages the planning context and simulates the environment. The middle-level solver, the Sustainable Conflict-Based Search algorithm (SCBS), builds a conflict tree and maintains the planning context. The low-level solver, the Sustainable Reverse Safe Interval Path Planning algorithm (SRSIPP), is an efficient single-agent solver that uses previous planning context to reduce duplicate calculations. Experiments show that our proposed method has significant improvement in terms of computational efficiency. In one of the test scenarios, our algorithm can be 1.48 times faster than SOTA on average under different agent number settings.