 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Multimodal AI Help? Diagnostic Complementarity of Vision-Language Models and CNNs for Spectrum Management in Satellite-Terrestrial Networks
Apr 04, 2026The adoption of vision-language models (VLMs) for wireless network management is accelerating, yet no systematic understanding exists of where these large foundation models outperform lightweight convolutional neural networks (CNNs) for spectrum-related tasks. This paper presents the first diagnostic comparison of VLMs and CNNs for spectrum heatmap understanding in non-terrestrial network and terrestrial network (NTN-TN) cooperative systems. We introduce SpectrumQA, a benchmark comprising 108K visual question-answer pairs across four granularity levels: scene classification (L1), regional reasoning (L2), spatial localization (L3), and semantic reasoning (L4). Our experiments on three NTN-TN scenarios with a frozen Qwen2-VL-7B and a trained ResNet-18 reveal a clear taskdependent complementarity: CNN achieves 72.9% accuracy at severity classification (L1) and 0.552 IoU at spatial localization (L3), while VLM uniquely enables semantic reasoning (L4) with F1=0.576 using only three in-context examples-a capability fundamentally absent in CNN architectures. Chain-of-thought (CoT) prompting further improves VLM reasoning by 12.6% (F1: 0.209->0.233) while having zero effect on spatial tasks, confirming that the complementarity is rooted in architectural differences rather than prompting limitations. A deterministic task-type router that delegates supervised tasks to CNN and reasoning tasks to VLM achieves a composite score of 0.616, a 39.1% improvement over CNN alone. We further show that VLM representations exhibit stronger cross-scenario robustness, with smaller performance degradation in 5 out of 6 transfer directions. These findings provide actionable guidelines: deploy CNNs for spatial localization and VLMs for semantic spectrum reasoning, rather than treating them as substitutes.
When Adaptive Rewards Hurt: Causal Probing and the Switching-Stability Dilemma in LLM-Guided LEO Satellite Scheduling
Apr 04, 2026Adaptive reward design for deep reinforcement learning (DRL) in multi-beam LEO satellite scheduling is motivated by the intuition that regime-aware reward weights should outperform static ones. We systematically test this intuition and uncover a switching-stability dilemma: near-constant reward weights (342.1 Mbps) outperform carefully-tuned dynamic weights (103.3+/-96.8 Mbps) because PPO requires a quasistationary reward signal for value function convergence. Weight adaptation-regardless of quality-degrades performance by repeatedly restarting convergence. To understand why specific weights matter, we introduce a single-variable causal probing method that independently perturbs each reward term by +/-20% and measures PPO response after 50k steps. Probing reveals counterintuitive leverage: a +20% increase in the switching penalty yields +157 Mbps for polar handover and +130 Mbps for hot-cold regimes-findings inaccessible to human experts or trained MLPs without systematic probing. We evaluate four MDP architect variants (fixed, rule-based, learned MLP, finetuned LLM) across known and novel traffic regimes. The MLP achieves 357.9 Mbps on known regimes and 325.2 Mbps on novel regimes, while the fine-tuned LLM collapses to 45.3+/-43.0 Mbps due to weight oscillation rather than lack of domain knowledge-output consistency, not knowledge, is the binding constraint. Our findings provide an empirically-grounded roadmap for LLM-DRL integration in communication systems, identifying where LLMs add irreplaceable value (natural language intent understanding) versus where simpler methods suffice.
MLV-Edit: Towards Consistent and Highly Efficient Editing for Minute-Level Videos
Feb 02, 2026We propose MLV-Edit, a training-free, flow-based framework that address the unique challenges of minute-level video editing. While existing techniques excel in short-form video manipulation, scaling them to long-duration videos remains challenging due to prohibitive computational overhead and the difficulty of maintaining global temporal consistency across thousands of frames. To address this, MLV-Edit employs a divide-and-conquer strategy for segment-wise editing, facilitated by two core modules: Velocity Blend rectifies motion inconsistencies at segment boundaries by aligning the flow fields of adjacent chunks, eliminating flickering and boundary artifacts commonly observed in fragmented video processing; and Attention Sink anchors local segment features to global reference frames, effectively suppressing cumulative structural drift. Extensive quantitative and qualitative experiments demonstrate that MLV-Edit consistently outperforms state-of-the-art methods in terms of temporal stability and semantic fidelity.
IC-Effect: Precise and Efficient Video Effects Editing via In-Context Learning
Dec 17, 2025

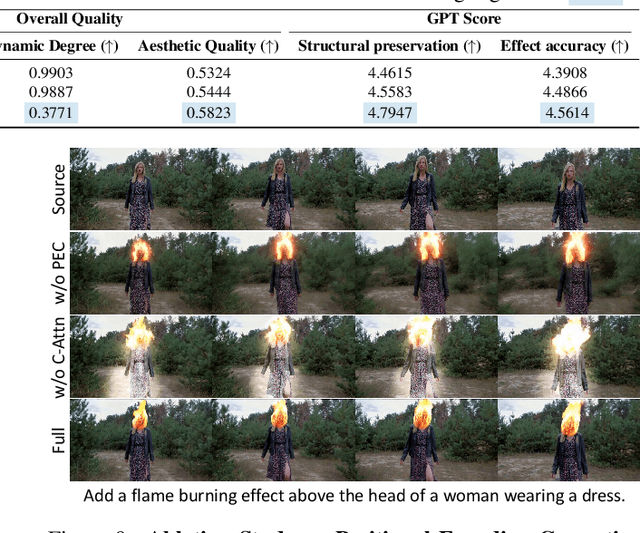

We propose \textbf{IC-Effect}, an instruction-guided, DiT-based framework for few-shot video VFX editing that synthesizes complex effects (\eg flames, particles and cartoon characters) while strictly preserving spatial and temporal consistency. Video VFX editing is highly challenging because injected effects must blend seamlessly with the background, the background must remain entirely unchanged, and effect patterns must be learned efficiently from limited paired data. However, existing video editing models fail to satisfy these requirements. IC-Effect leverages the source video as clean contextual conditions, exploiting the contextual learning capability of DiT models to achieve precise background preservation and natural effect injection. A two-stage training strategy, consisting of general editing adaptation followed by effect-specific learning via Effect-LoRA, ensures strong instruction following and robust effect modeling. To further improve efficiency, we introduce spatiotemporal sparse tokenization, enabling high fidelity with substantially reduced computation. We also release a paired VFX editing dataset spanning $15$ high-quality visual styles. Extensive experiments show that IC-Effect delivers high-quality, controllable, and temporally consistent VFX editing, opening new possibilities for video creation.
Real-Time Metric-Semantic Mapping for Autonomous Navigation in Outdoor Environments
Nov 30, 2024


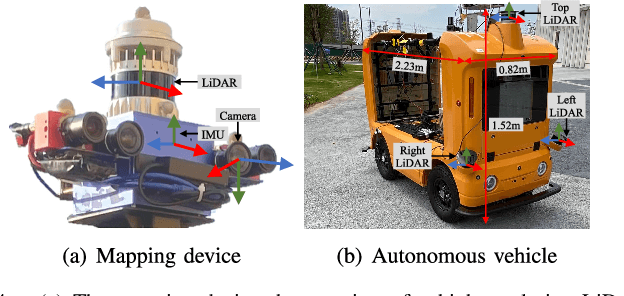
The creation of a metric-semantic map, which encodes human-prior knowledge, represents a high-level abstraction of environments. However, constructing such a map poses challenges related to the fusion of multi-modal sensor data, the attainment of real-time mapping performance, and the preservation of structural and semantic information consistency. In this paper, we introduce an online metric-semantic mapping system that utilizes LiDAR-Visual-Inertial sensing to generate a global metric-semantic mesh map of large-scale outdoor environments. Leveraging GPU acceleration, our mapping process achieves exceptional speed, with frame processing taking less than 7ms, regardless of scenario scale. Furthermore, we seamlessly integrate the resultant map into a real-world navigation system, enabling metric-semantic-based terrain assessment and autonomous point-to-point navigation within a campus environment. Through extensive experiments conducted on both publicly available and self-collected datasets comprising 24 sequences, we demonstrate the effectiveness of our mapping and navigation methodologies. Code has been publicly released: https://github.com/gogojjh/cobra
MGCBS: An Optimal and Efficient Algorithm for Solving Multi-Goal Multi-Agent Path Finding Problem
Apr 30, 2024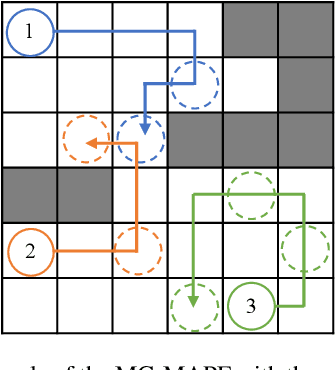
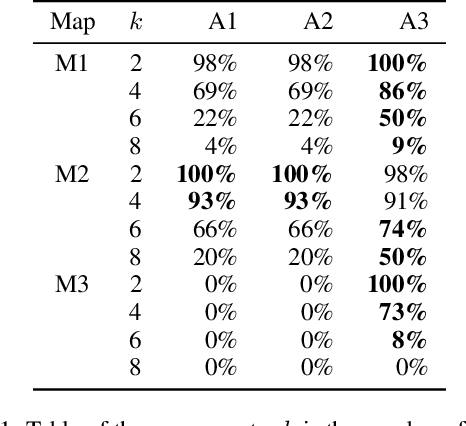
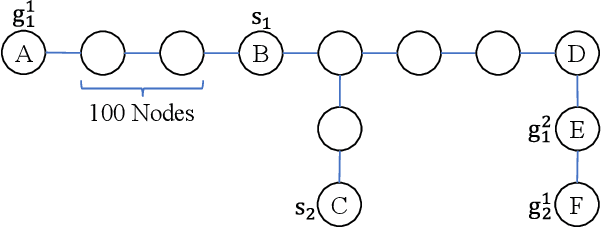
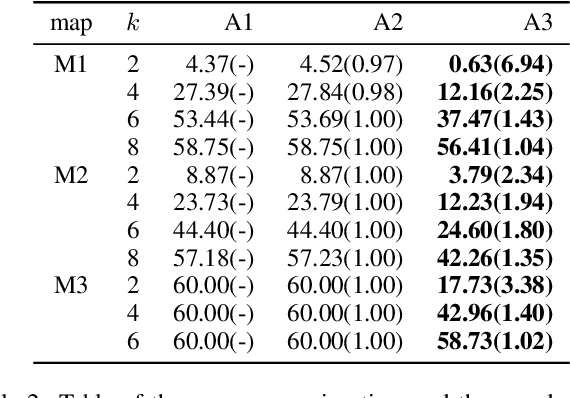
With the expansion of the scale of robotics applications, the multi-goal multi-agent pathfinding (MG-MAPF) problem began to gain widespread attention. This problem requires each agent to visit pre-assigned multiple goal points at least once without conflict. Some previous methods have been proposed to solve the MG-MAPF problem based on Decoupling the goal Vertex visiting order search and the Single-agent pathfinding (DVS). However, this paper demonstrates that the methods based on DVS cannot always obtain the optimal solution. To obtain the optimal result, we propose the Multi-Goal Conflict-Based Search (MGCBS), which is based on Decoupling the goal Safe interval visiting order search and the Single-agent pathfinding (DSS). Additionally, we present the Time-Interval-Space Forest (TIS Forest) to enhance the efficiency of MGCBS by maintaining the shortest paths from any start point at any start time step to each safe interval at the goal points. The experiment demonstrates that our method can consistently obtain optimal results and execute up to 7 times faster than the state-of-the-art method in our evaluation.
An Efficient Approach to the Online Multi-Agent Path Finding Problem by Using Sustainable Information
Jan 11, 2023Multi-agent path finding (MAPF) is the problem of moving agents to the goal vertex without collision. In the online MAPF problem, new agents may be added to the environment at any time, and the current agents have no information about future agents. The inability of existing online methods to reuse previous planning contexts results in redundant computation and reduces algorithm efficiency. Hence, we propose a three-level approach to solve online MAPF utilizing sustainable information, which can decrease its redundant calculations. The high-level solver, the Sustainable Replan algorithm (SR), manages the planning context and simulates the environment. The middle-level solver, the Sustainable Conflict-Based Search algorithm (SCBS), builds a conflict tree and maintains the planning context. The low-level solver, the Sustainable Reverse Safe Interval Path Planning algorithm (SRSIPP), is an efficient single-agent solver that uses previous planning context to reduce duplicate calculations. Experiments show that our proposed method has significant improvement in terms of computational efficiency. In one of the test scenarios, our algorithm can be 1.48 times faster than SOTA on average under different agent number settings.
Visual Subtitle Feature Enhanced Video Outline Generation
Sep 01, 2022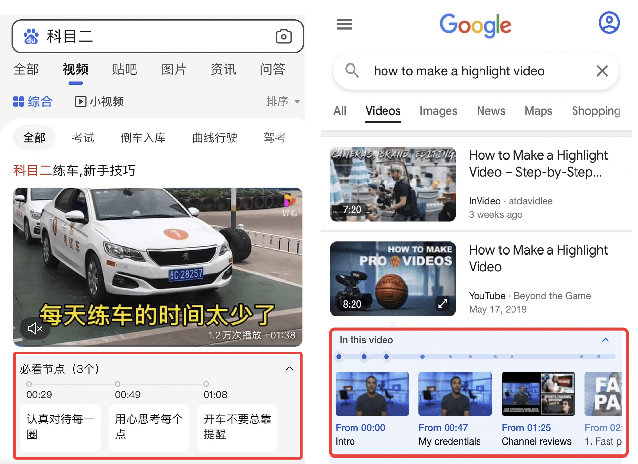
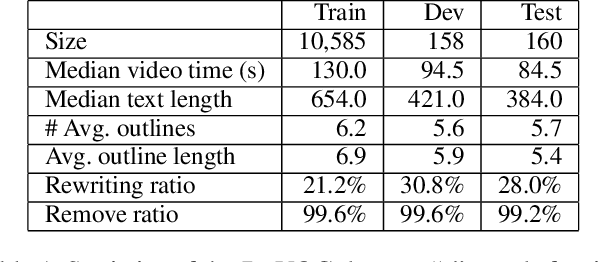

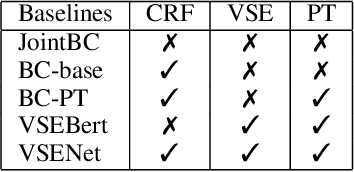
With the tremendously increasing number of videos, there is a great demand for techniques that help people quickly navigate to the video segments they are interested in. However, current works on video understanding mainly focus on video content summarization, while little effort has been made to explore the structure of a video. Inspired by textual outline generation, we introduce a novel video understanding task, namely video outline generation (VOG). This task is defined to contain two sub-tasks: (1) first segmenting the video according to the content structure and then (2) generating a heading for each segment. To learn and evaluate VOG, we annotate a 10k+ dataset, called DuVOG. Specifically, we use OCR tools to recognize subtitles of videos. Then annotators are asked to divide subtitles into chapters and title each chapter. In videos, highlighted text tends to be the headline since it is more likely to attract attention. Therefore we propose a Visual Subtitle feature Enhanced video outline generation model (VSENet) which takes as input the textual subtitles together with their visual font sizes and positions. We consider the VOG task as a sequence tagging problem that extracts spans where the headings are located and then rewrites them to form the final outlines. Furthermore, based on the similarity between video outlines and textual outlines, we use a large number of articles with chapter headings to pretrain our model. Experiments on DuVOG show that our model largely outperforms other baseline methods, achieving 77.1 of F1-score for the video segmentation level and 85.0 of ROUGE-L_F0.5 for the headline generation level.