 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Subtitle Feature Enhanced Video Outline Generation
Sep 01, 2022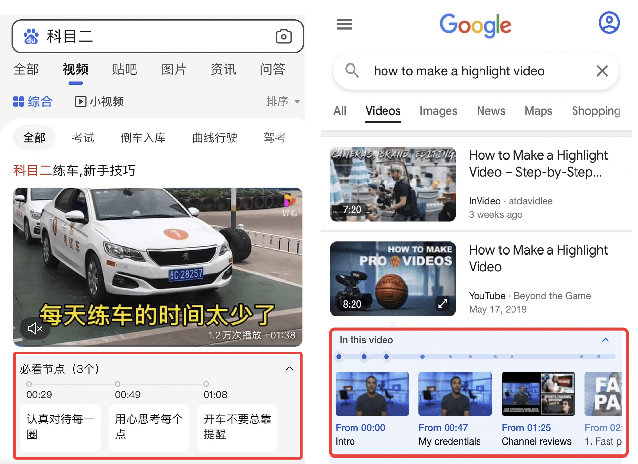
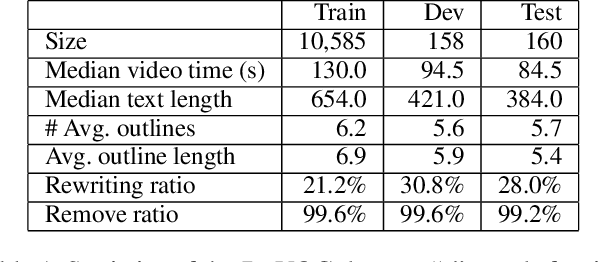

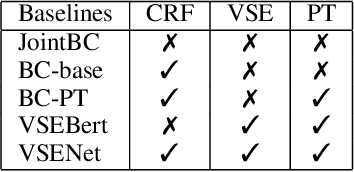
With the tremendously increasing number of videos, there is a great demand for techniques that help people quickly navigate to the video segments they are interested in. However, current works on video understanding mainly focus on video content summarization, while little effort has been made to explore the structure of a video. Inspired by textual outline generation, we introduce a novel video understanding task, namely video outline generation (VOG). This task is defined to contain two sub-tasks: (1) first segmenting the video according to the content structure and then (2) generating a heading for each segment. To learn and evaluate VOG, we annotate a 10k+ dataset, called DuVOG. Specifically, we use OCR tools to recognize subtitles of videos. Then annotators are asked to divide subtitles into chapters and title each chapter. In videos, highlighted text tends to be the headline since it is more likely to attract attention. Therefore we propose a Visual Subtitle feature Enhanced video outline generation model (VSENet) which takes as input the textual subtitles together with their visual font sizes and positions. We consider the VOG task as a sequence tagging problem that extracts spans where the headings are located and then rewrites them to form the final outlines. Furthermore, based on the similarity between video outlines and textual outlines, we use a large number of articles with chapter headings to pretrain our model. Experiments on DuVOG show that our model largely outperforms other baseline methods, achieving 77.1 of F1-score for the video segmentation level and 85.0 of ROUGE-L_F0.5 for the headline generation level.
KGEA: A Knowledge Graph Enhanced Article Quality Identification Dataset
Jun 15, 2022
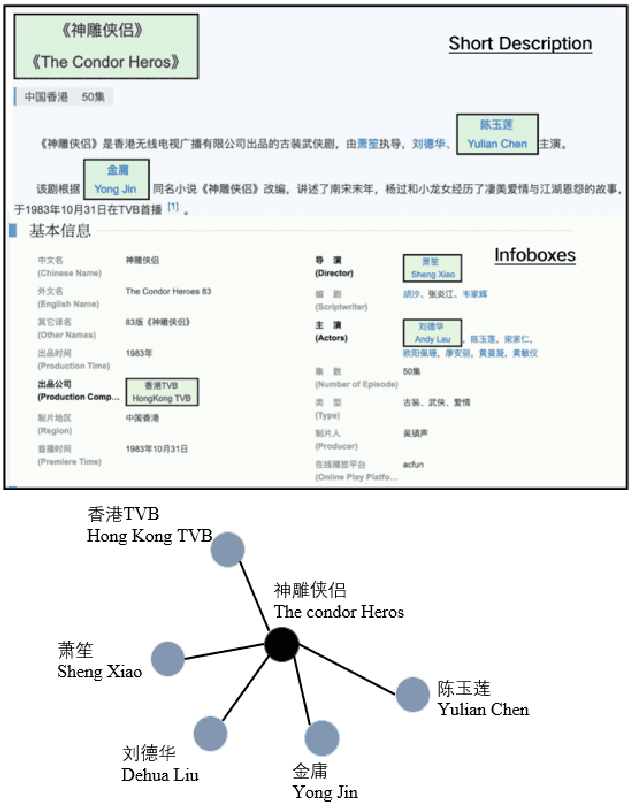
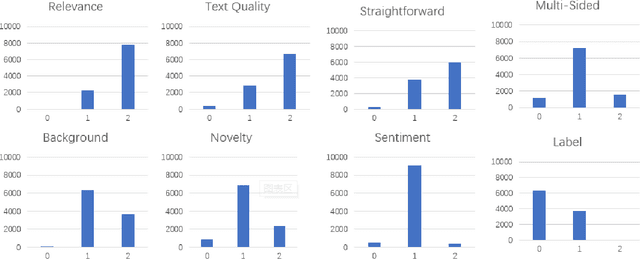
With so many articles of varying quality being produced at every moment, it is a very urgent task to screen this data for quality articles and commit them out to social media. It is worth noting that high quality articles have many characteristics, such as relevance, text quality, straightforward, multi-sided, background, novelty and sentiment. Thus, it would be inadequate to purely use the content of an article to identify its quality. Therefore, we plan to use the external knowledge interaction to refine the performance and propose a knowledge graph enhanced article quality identification dataset (KGEA) based on Baidu Encyclopedia. We quantified the articles through 7 dimensions and use co-occurrence of the entities between the articles and the Baidu encyclopedia to construct the knowledge graph for every article. We also compared some text classification baselines and found that external knowledge can guide the articles to a more competitive classification with the graph neural networks.