 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding ChatGPT to Generate Salient Domain Summaries
Jun 03, 2024



ChatGPT is instruct-tuned to generate general and human-expected content to align with human preference through Reinforcement Learning from Human Feedback (RLHF), meanwhile resulting in generated responses not salient enough. Therefore, in this case, ChatGPT may fail to satisfy domain requirements in zero-shot settings, leading to poor ROUGE scores. Inspired by the In-Context Learning (ICL) and retelling ability of ChatGPT, this paper proposes PADS, a \textbf{P}ipeline for \textbf{A}ssisting ChatGPT in \textbf{D}omain \textbf{S}ummarization. PADS consists of a retriever to retrieve similar examples from corpora and a rank model to rerank the multiple candidate summaries generated by ChatGPT. Specifically, given an inference document, we first retrieve an in-context demonstration via the retriever. Then, we require ChatGPT to generate $k$ candidate summaries for the inference document at a time under the guidance of the retrieved demonstration. Finally, the rank model independently scores the $k$ candidate summaries according to their quality and selects the optimal one. We extensively explore dense and sparse retrieval methods to select effective demonstrations for reference and efficiently train the rank model to reflect the quality of candidate summaries for each given summarized document. Additionally, PADS contains merely 400M trainable parameters originating from the rank model and we merely collect 2.5k data to train it. We evaluate PADS on five datasets from different domains, and the result indicates that each module in PADS is committed to effectively guiding ChatGPT to generate salient summaries fitting different domain requirements. Specifically, in the popular summarization dataset Gigaword, PADS achieves over +8 gain on ROUGE-L, compared with the naive ChatGPT in the zero-shot setting. \footnote{Our code are available at \url{https://github.com/jungao1106/PADS}}
Revising Image-Text Retrieval via Multi-Modal Entailment
Sep 01, 2022

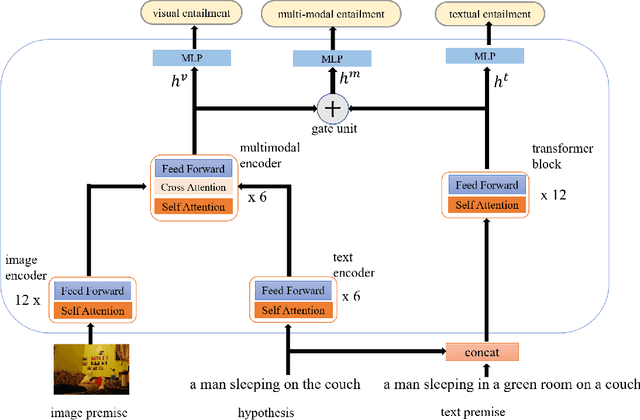
An outstanding image-text retrieval model depends on high-quality labeled data. While the builders of existing image-text retrieval datasets strive to ensure that the caption matches the linked image, they cannot prevent a caption from fitting other images. We observe that such a many-to-many matching phenomenon is quite common in the widely-used retrieval datasets, where one caption can describe up to 178 images. These large matching-lost data not only confuse the model in training but also weaken the evaluation accuracy. Inspired by visual and textual entailment tasks, we propose a multi-modal entailment classifier to determine whether a sentence is entailed by an image plus its linked captions. Subsequently, we revise the image-text retrieval datasets by adding these entailed captions as additional weak labels of an image and develop a universal variable learning rate strategy to teach a retrieval model to distinguish the entailed captions from other negative samples. In experiments, we manually annotate an entailment-corrected image-text retrieval dataset for evaluation. The results demonstrate that the proposed entailment classifier achieves about 78% accuracy and consistently improves the performance of image-text retrieval baselines.
KGEA: A Knowledge Graph Enhanced Article Quality Identification Dataset
Jun 15, 2022
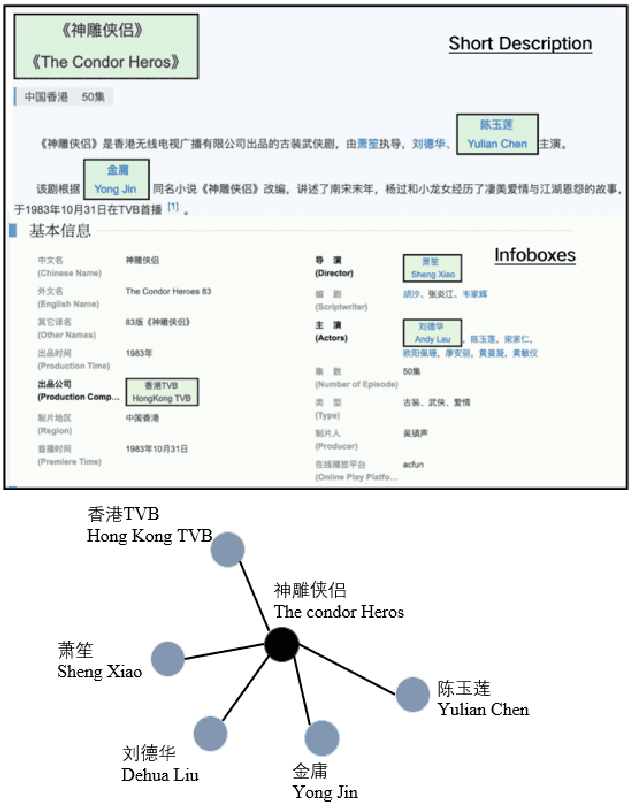
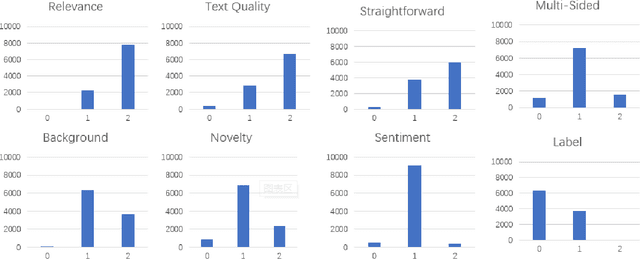
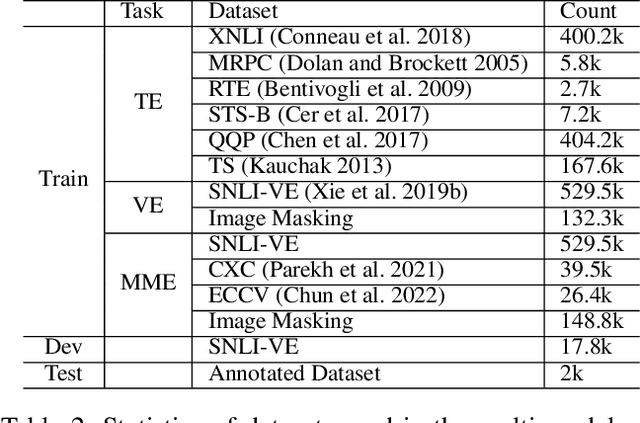
With so many articles of varying quality being produced at every moment, it is a very urgent task to screen this data for quality articles and commit them out to social media. It is worth noting that high quality articles have many characteristics, such as relevance, text quality, straightforward, multi-sided, background, novelty and sentiment. Thus, it would be inadequate to purely use the content of an article to identify its quality. Therefore, we plan to use the external knowledge interaction to refine the performance and propose a knowledge graph enhanced article quality identification dataset (KGEA) based on Baidu Encyclopedia. We quantified the articles through 7 dimensions and use co-occurrence of the entities between the articles and the Baidu encyclopedia to construct the knowledge graph for every article. We also compared some text classification baselines and found that external knowledge can guide the articles to a more competitive classification with the graph neural networks.
General and Domain Adaptive Chinese Spelling Check with Error Consistent Pretraining
Mar 21, 2022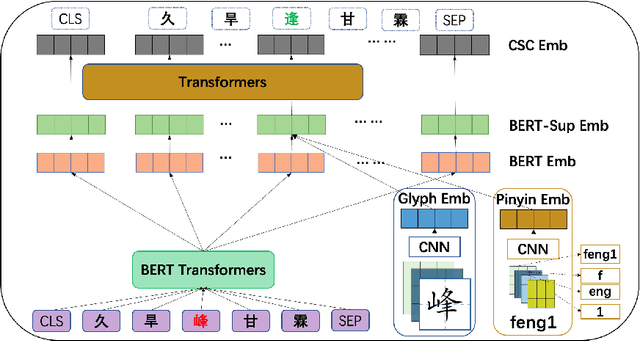
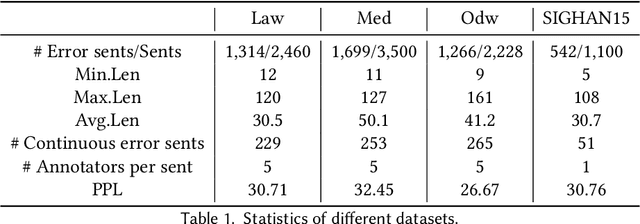
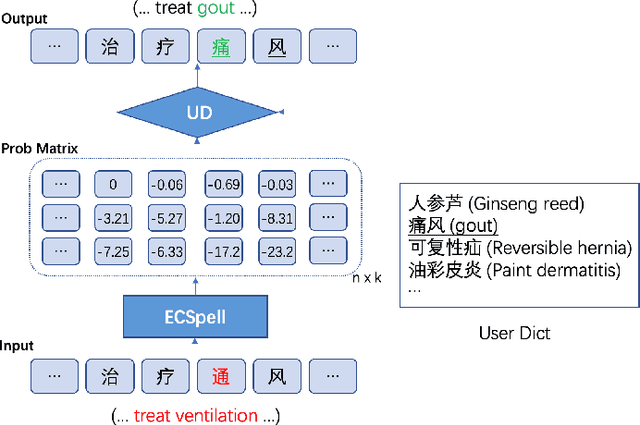

The lack of label data is one of the significant bottlenecks for Chinese Spelling Check (CSC). Existing researches use the method of automatic generation by exploiting unlabeled data to expand the supervised corpus. However, there is a big gap between the real input scenario and automatic generated corpus. Thus, we develop a competitive general speller ECSpell which adopts the Error Consistent masking strategy to create data for pretraining. This error consistency masking strategy is used to specify the error types of automatically generated sentences which is consistent with real scene. The experimental result indicates our model outperforms previous state-of-the-art models on the general benchmark. Moreover, spellers often work within a particular domain in real life. Due to lots of uncommon domain terms, experiments on our built domain specific datasets show that general models perform terribly. Inspired by the common practice of input methods, we propose to add an alterable user dictionary to handle the zero-shot domain adaption problem. Specifically, we attach a User Dictionary guided inference module (UD) to a general token classification based speller. Our experiments demonstrate that ECSpell$^{UD}$, namely ECSpell combined with UD, surpasses all the other baselines largely, even approaching the performance on the general benchmark.