 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
Aug 07, 2025
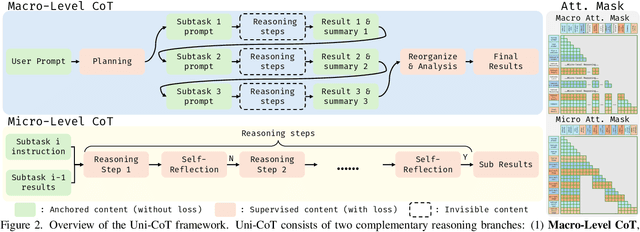

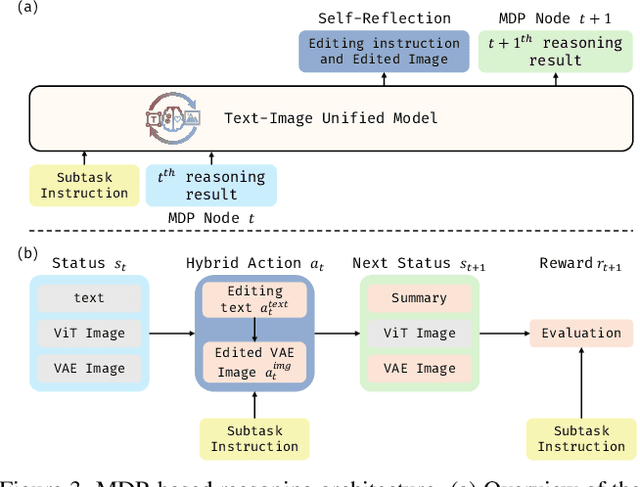
Chain-of-Thought (CoT) reasoning has been widely adopted to enhance Large Language Models (LLMs) by decomposing complex tasks into simpler, sequential subtasks. However, extending CoT to vision-language reasoning tasks remains challenging, as it often requires interpreting transitions of visual states to support reasoning. Existing methods often struggle with this due to limited capacity of modeling visual state transitions or incoherent visual trajectories caused by fragmented architectures. To overcome these limitations, we propose Uni-CoT, a Unified Chain-of-Thought framework that enables coherent and grounded multimodal reasoning within a single unified model. The key idea is to leverage a model capable of both image understanding and generation to reason over visual content and model evolving visual states. However, empowering a unified model to achieve that is non-trivial, given the high computational cost and the burden of training. To address this, Uni-CoT introduces a novel two-level reasoning paradigm: A Macro-Level CoT for high-level task planning and A Micro-Level CoT for subtask execution. This design significantly reduces the computational overhead. Furthermore, we introduce a structured training paradigm that combines interleaved image-text supervision for macro-level CoT with multi-task objectives for micro-level CoT. Together, these innovations allow Uni-CoT to perform scalable and coherent multi-modal reasoning. Furthermore, thanks to our design, all experiments can be efficiently completed using only 8 A100 GPUs with 80GB VRAM each. Experimental results on reasoning-driven image generation benchmark (WISE) and editing benchmarks (RISE and KRIS) indicates that Uni-CoT demonstrates SOTA performance and strong generalization, establishing Uni-CoT as a promising solution for multi-modal reasoning. Project Page and Code: https://sais-fuxi.github.io/projects/uni-cot/
Omni-Video: Democratizing Unified Video Understanding and Generation
Jul 09, 2025Notable breakthroughs in unified understanding and generation modeling have led to remarkable advancements in image understanding, reasoning, production and editing, yet current foundational models predominantly focus on processing images, creating a gap in the development of unified models for video understanding and generation. This report presents Omni-Video, an efficient and effective unified framework for video understanding, generation, as well as instruction-based editing. Our key insight is to teach existing multimodal large language models (MLLMs) to produce continuous visual clues that are used as the input of diffusion decoders, which produce high-quality videos conditioned on these visual clues. To fully unlock the potential of our system for unified video modeling, we integrate several technical improvements: 1) a lightweight architectural design that respectively attaches a vision head on the top of MLLMs and a adapter before the input of diffusion decoders, the former produce visual tokens for the latter, which adapts these visual tokens to the conditional space of diffusion decoders; and 2) an efficient multi-stage training scheme that facilitates a fast connection between MLLMs and diffusion decoders with limited data and computational resources. We empirically demonstrate that our model exhibits satisfactory generalization abilities across video generation, editing and understanding tasks.
Cockatiel: Ensembling Synthetic and Human Preferenced Training for Detailed Video Caption
Mar 12, 2025Video Detailed Captioning (VDC) is a crucial task for vision-language bridging, enabling fine-grained descriptions of complex video content. In this paper, we first comprehensively benchmark current state-of-the-art approaches and systematically identified two critical limitations: biased capability towards specific captioning aspect and misalignment with human preferences. To address these deficiencies, we propose Cockatiel, a novel three-stage training pipeline that ensembles synthetic and human-aligned training for improving VDC performance. In the first stage, we derive a scorer from a meticulously annotated dataset to select synthetic captions high-performing on certain fine-grained video-caption alignment and human-preferred while disregarding others. Then, we train Cockatiel-13B, using this curated dataset to infuse it with assembled model strengths and human preferences. Finally, we further distill Cockatiel-8B from Cockatiel-13B for the ease of usage. Extensive quantitative and qualitative experiments reflect the effectiveness of our method, as we not only set new state-of-the-art performance on VDCSCORE in a dimension-balanced way but also surpass leading alternatives on human preference by a large margin as depicted by the human evaluation results.
Raccoon: Multi-stage Diffusion Training with Coarse-to-Fine Curating Videos
Feb 28, 2025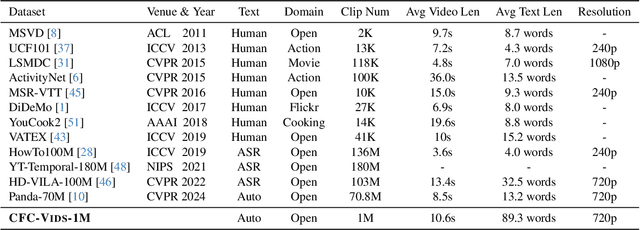


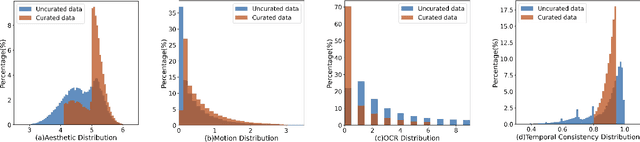
Text-to-video generation has demonstrated promising progress with the advent of diffusion models, yet existing approaches are limited by dataset quality and computational resources. To address these limitations, this paper presents a comprehensive approach that advances both data curation and model design. We introduce CFC-VIDS-1M, a high-quality video dataset constructed through a systematic coarse-to-fine curation pipeline. The pipeline first evaluates video quality across multiple dimensions, followed by a fine-grained stage that leverages vision-language models to enhance text-video alignment and semantic richness. Building upon the curated dataset's emphasis on visual quality and temporal coherence, we develop RACCOON, a transformer-based architecture with decoupled spatial-temporal attention mechanisms. The model is trained through a progressive four-stage strategy designed to efficiently handle the complexities of video generation. Extensive experiments demonstrate that our integrated approach of high-quality data curation and efficient training strategy generates visually appealing and temporally coherent videos while maintaining computational efficiency. We will release our dataset, code, and models.
VidGen-1M: A Large-Scale Dataset for Text-to-video Generation
Aug 05, 2024



The quality of video-text pairs fundamentally determines the upper bound of text-to-video models. Currently, the datasets used for training these models suffer from significant shortcomings, including low temporal consistency, poor-quality captions, substandard video quality, and imbalanced data distribution. The prevailing video curation process, which depends on image models for tagging and manual rule-based curation, leads to a high computational load and leaves behind unclean data. As a result, there is a lack of appropriate training datasets for text-to-video models. To address this problem, we present VidGen-1M, a superior training dataset for text-to-video models. Produced through a coarse-to-fine curation strategy, this dataset guarantees high-quality videos and detailed captions with excellent temporal consistency. When used to train the video generation model, this dataset has led to experimental results that surpass those obtained with other models.
EVALALIGN: Supervised Fine-Tuning Multimodal LLMs with Human-Aligned Data for Evaluating Text-to-Image Models
Jun 27, 2024
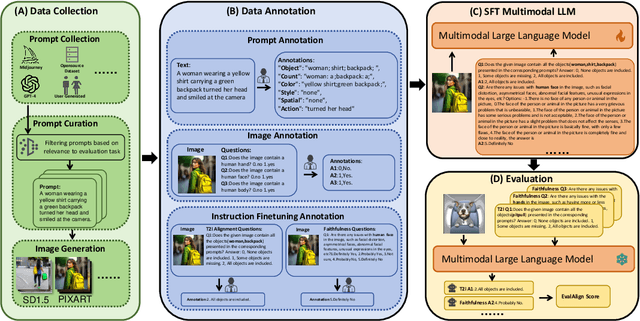
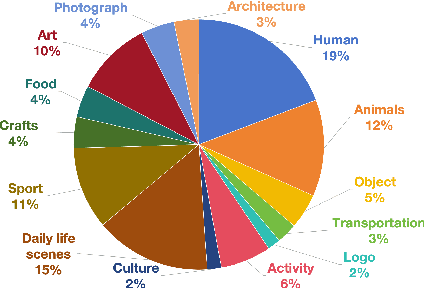
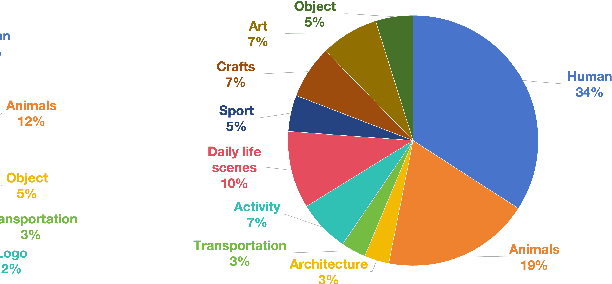
The recent advancements in text-to-image generative models have been remarkable. Yet, the field suffers from a lack of evaluation metrics that accurately reflect the performance of these models, particularly lacking fine-grained metrics that can guide the optimization of the models. In this paper, we propose EvalAlign, a metric characterized by its accuracy, stability, and fine granularity. Our approach leverages the capabilities of Multimodal Large Language Models (MLLMs) pre-trained on extensive datasets. We develop evaluation protocols that focus on two key dimensions: image faithfulness and text-image alignment. Each protocol comprises a set of detailed, fine-grained instructions linked to specific scoring options, enabling precise manual scoring of the generated images. We Supervised Fine-Tune (SFT) the MLLM to align closely with human evaluative judgments, resulting in a robust evaluation model. Our comprehensive tests across 24 text-to-image generation models demonstrate that EvalAlign not only provides superior metric stability but also aligns more closely with human preferences than existing metrics, confirming its effectiveness and utility in model assessment.
EvalAlign: Evaluating Text-to-Image Models through Precision Alignment of Multimodal Large Models with Supervised Fine-Tuning to Human Annotations
Jun 24, 2024The recent advancements in text-to-image generative models have been remarkable. Yet, the field suffers from a lack of evaluation metrics that accurately reflect the performance of these models, particularly lacking fine-grained metrics that can guide the optimization of the models. In this paper, we propose EvalAlign, a metric characterized by its accuracy, stability, and fine granularity. Our approach leverages the capabilities of Multimodal Large Language Models (MLLMs) pre-trained on extensive datasets. We develop evaluation protocols that focus on two key dimensions: image faithfulness and text-image alignment. Each protocol comprises a set of detailed, fine-grained instructions linked to specific scoring options, enabling precise manual scoring of the generated images. We Supervised Fine-Tune (SFT) the MLLM to align closely with human evaluative judgments, resulting in a robust evaluation model. Our comprehensive tests across 24 text-to-image generation models demonstrate that EvalAlign not only provides superior metric stability but also aligns more closely with human preferences than existing metrics, confirming its effectiveness and utility in model assessment.
Guiding ChatGPT to Generate Salient Domain Summaries
Jun 03, 2024



ChatGPT is instruct-tuned to generate general and human-expected content to align with human preference through Reinforcement Learning from Human Feedback (RLHF), meanwhile resulting in generated responses not salient enough. Therefore, in this case, ChatGPT may fail to satisfy domain requirements in zero-shot settings, leading to poor ROUGE scores. Inspired by the In-Context Learning (ICL) and retelling ability of ChatGPT, this paper proposes PADS, a \textbf{P}ipeline for \textbf{A}ssisting ChatGPT in \textbf{D}omain \textbf{S}ummarization. PADS consists of a retriever to retrieve similar examples from corpora and a rank model to rerank the multiple candidate summaries generated by ChatGPT. Specifically, given an inference document, we first retrieve an in-context demonstration via the retriever. Then, we require ChatGPT to generate $k$ candidate summaries for the inference document at a time under the guidance of the retrieved demonstration. Finally, the rank model independently scores the $k$ candidate summaries according to their quality and selects the optimal one. We extensively explore dense and sparse retrieval methods to select effective demonstrations for reference and efficiently train the rank model to reflect the quality of candidate summaries for each given summarized document. Additionally, PADS contains merely 400M trainable parameters originating from the rank model and we merely collect 2.5k data to train it. We evaluate PADS on five datasets from different domains, and the result indicates that each module in PADS is committed to effectively guiding ChatGPT to generate salient summaries fitting different domain requirements. Specifically, in the popular summarization dataset Gigaword, PADS achieves over +8 gain on ROUGE-L, compared with the naive ChatGPT in the zero-shot setting. \footnote{Our code are available at \url{https://github.com/jungao1106/PADS}}