 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaccoon: Multi-stage Diffusion Training with Coarse-to-Fine Curating Videos
Paper and Code
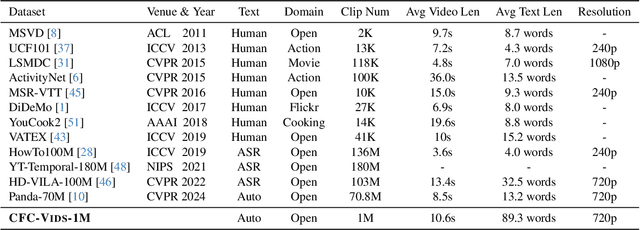


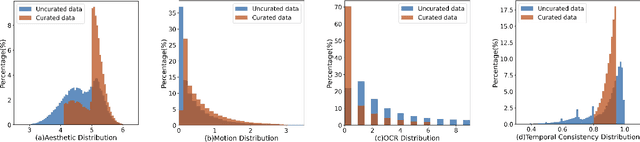
Text-to-video generation has demonstrated promising progress with the advent of diffusion models, yet existing approaches are limited by dataset quality and computational resources. To address these limitations, this paper presents a comprehensive approach that advances both data curation and model design. We introduce CFC-VIDS-1M, a high-quality video dataset constructed through a systematic coarse-to-fine curation pipeline. The pipeline first evaluates video quality across multiple dimensions, followed by a fine-grained stage that leverages vision-language models to enhance text-video alignment and semantic richness. Building upon the curated dataset's emphasis on visual quality and temporal coherence, we develop RACCOON, a transformer-based architecture with decoupled spatial-temporal attention mechanisms. The model is trained through a progressive four-stage strategy designed to efficiently handle the complexities of video generation. Extensive experiments demonstrate that our integrated approach of high-quality data curation and efficient training strategy generates visually appealing and temporally coherent videos while maintaining computational efficiency. We will release our dataset, code, and models.