 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoRD: Robust Humanoid Control via History-Conditioned Reinforcement Learning and Online Distillation
Feb 05, 2026Humanoid robots can suffer significant performance drops under small changes in dynamics, task specifications, or environment setup. We propose HoRD, a two-stage learning framework for robust humanoid control under domain shift. First, we train a high-performance teacher policy via history-conditioned reinforcement learning, where the policy infers latent dynamics context from recent state--action trajectories to adapt online to diverse randomized dynamics. Second, we perform online distillation to transfer the teacher's robust control capabilities into a transformer-based student policy that operates on sparse root-relative 3D joint keypoint trajectories. By combining history-conditioned adaptation with online distillation, HoRD enables a single policy to adapt zero-shot to unseen domains without per-domain retraining. Extensive experiments show HoRD outperforms strong baselines in robustness and transfer, especially under unseen domains and external perturbations. Code and project page are available at https://tonywang-0517.github.io/hord/.
Rethinking Perplexity: Revealing the Impact of Input Length on Perplexity Evaluation in LLMs
Feb 04, 2026Perplexity is a widely adopted metric for assessing the predictive quality of large language models (LLMs) and often serves as a reference metric for downstream evaluations. However, recent evidence shows that perplexity can be unreliable, especially when irrelevant long inputs are used, raising concerns for both benchmarking and system deployment. While prior efforts have employed selective input filtering and curated datasets, the impact of input length on perplexity has not been systematically studied from a systems perspective and input length has rarely been treated as a first-class system variable affecting both fairness and efficiency. In this work, we close this gap by introducing LengthBenchmark, a system-conscious evaluation framework that explicitly integrates input length, evaluation protocol design, and system-level costs, evaluating representative LLMs under two scoring protocols (direct accumulation and fixed window sliding) across varying context lengths. Unlike prior work that focuses solely on accuracy-oriented metrics, LengthBenchmark additionally measures latency, memory footprint, and evaluation cost, thereby linking predictive metrics to deployment realities. We further incorporate quantized variants not as a main contribution, but as robustness checks, showing that length-induced biases persist across both full-precision and compressed models. This design disentangles the effects of evaluation logic, quantization, and input length, and demonstrates that length bias is a general phenomenon that undermines fair cross-model comparison. Our analysis yields two key observations: (i) sliding window evaluation consistently inflates performance on short inputs, and (ii) both full-precision and quantized models appear to realise gains as the evaluated segment length grows.
SDPO: Importance-Sampled Direct Preference Optimization for Stable Diffusion Training
May 28, 2025
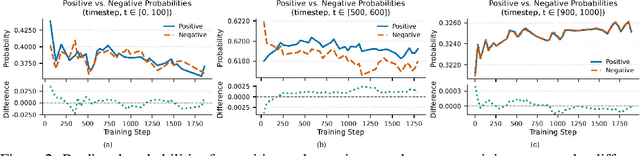
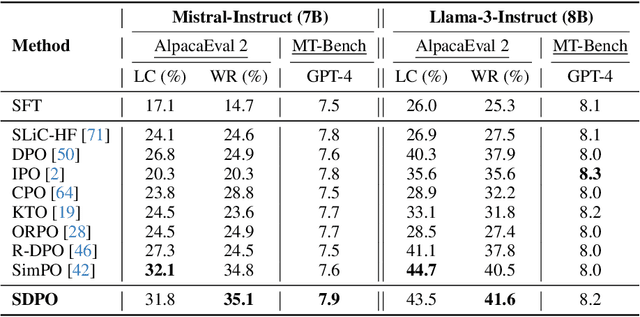
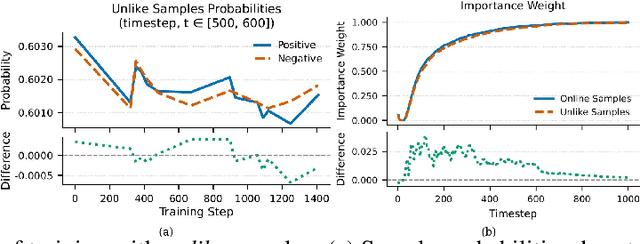
Preference learning has become a central technique for aligning generative models with human expectations. Recently, it has been extended to diffusion models through methods like Direct Preference Optimization (DPO). However, existing approaches such as Diffusion-DPO suffer from two key challenges: timestep-dependent instability, caused by a mismatch between the reverse and forward diffusion processes and by high gradient variance in early noisy timesteps, and off-policy bias arising from the mismatch between optimization and data collection policies. We begin by analyzing the reverse diffusion trajectory and observe that instability primarily occurs at early timesteps with low importance weights. To address these issues, we first propose DPO-C\&M, a practical strategy that improves stability by clipping and masking uninformative timesteps while partially mitigating off-policy bias. Building on this, we introduce SDPO (Importance-Sampled Direct Preference Optimization), a principled framework that incorporates importance sampling into the objective to fully correct for off-policy bias and emphasize informative updates during the diffusion process. Experiments on CogVideoX-2B, CogVideoX-5B, and Wan2.1-1.3B demonstrate that both methods outperform standard Diffusion-DPO, with SDPO achieving superior VBench scores, human preference alignment, and training robustness. These results highlight the importance of timestep-aware, distribution-corrected optimization in diffusion-based preference learning.
Hierarchical and Step-Layer-Wise Tuning of Attention Specialty for Multi-Instance Synthesis in Diffusion Transformers
Apr 14, 2025Text-to-image (T2I) generation models often struggle with multi-instance synthesis (MIS), where they must accurately depict multiple distinct instances in a single image based on complex prompts detailing individual features. Traditional MIS control methods for UNet architectures like SD v1.5/SDXL fail to adapt to DiT-based models like FLUX and SD v3.5, which rely on integrated attention between image and text tokens rather than text-image cross-attention. To enhance MIS in DiT, we first analyze the mixed attention mechanism in DiT. Our token-wise and layer-wise analysis of attention maps reveals a hierarchical response structure: instance tokens dominate early layers, background tokens in middle layers, and attribute tokens in later layers. Building on this observation, we propose a training-free approach for enhancing MIS in DiT-based models with hierarchical and step-layer-wise attention specialty tuning (AST). AST amplifies key regions while suppressing irrelevant areas in distinct attention maps across layers and steps, guided by the hierarchical structure. This optimizes multimodal interactions by hierarchically decoupling the complex prompts with instance-based sketches. We evaluate our approach using upgraded sketch-based layouts for the T2I-CompBench and customized complex scenes. Both quantitative and qualitative results confirm our method enhances complex layout generation, ensuring precise instance placement and attribute representation in MIS.
Frame-wise Conditioning Adaptation for Fine-Tuning Diffusion Models in Text-to-Video Prediction
Mar 17, 2025Text-video prediction (TVP) is a downstream video generation task that requires a model to produce subsequent video frames given a series of initial video frames and text describing the required motion. In practice TVP methods focus on a particular category of videos depicting manipulations of objects carried out by human beings or robot arms. Previous methods adapt models pre-trained on text-to-image tasks, and thus tend to generate video that lacks the required continuity. A natural progression would be to leverage more recent pre-trained text-to-video (T2V) models. This approach is rendered more challenging by the fact that the most common fine-tuning technique, low-rank adaptation (LoRA), yields undesirable results. In this work, we propose an adaptation-based strategy we label Frame-wise Conditioning Adaptation (FCA). Within the module, we devise a sub-module that produces frame-wise text embeddings from the input text, which acts as an additional text condition to aid generation. We use FCA to fine-tune the T2V model, which incorporates the initial frame(s) as an extra condition. We compare and discuss the more effective strategy for injecting such embeddings into the T2V model. We conduct extensive ablation studies on our design choices with quantitative and qualitative performance analysis. Our approach establishes a new state-of-the-art for the task of TVP. The project page is at https://github.com/Cuberick-Orion/FCA .
SARA: Structural and Adversarial Representation Alignment for Training-efficient Diffusion Models
Mar 11, 2025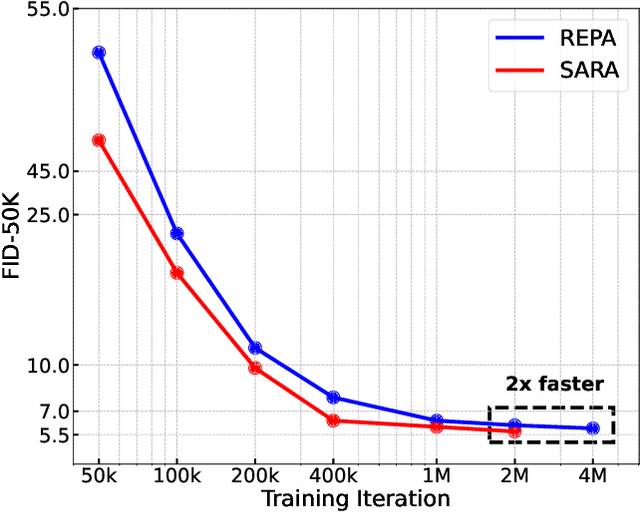
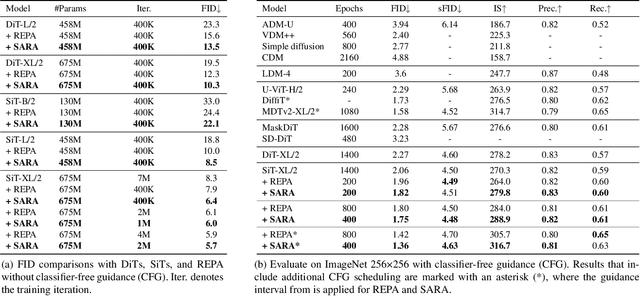


Modern diffusion models encounter a fundamental trade-off between training efficiency and generation quality. While existing representation alignment methods, such as REPA, accelerate convergence through patch-wise alignment, they often fail to capture structural relationships within visual representations and ensure global distribution consistency between pretrained encoders and denoising networks. To address these limitations, we introduce SARA, a hierarchical alignment framework that enforces multi-level representation constraints: (1) patch-wise alignment to preserve local semantic details, (2) autocorrelation matrix alignment to maintain structural consistency within representations, and (3) adversarial distribution alignment to mitigate global representation discrepancies. Unlike previous approaches, SARA explicitly models both intra-representation correlations via self-similarity matrices and inter-distribution coherence via adversarial alignment, enabling comprehensive alignment across local and global scales. Experiments on ImageNet-256 show that SARA achieves an FID of 1.36 while converging twice as fast as REPA, surpassing recent state-of-the-art image generation methods. This work establishes a systematic paradigm for optimizing diffusion training through hierarchical representation alignment.
Raccoon: Multi-stage Diffusion Training with Coarse-to-Fine Curating Videos
Feb 28, 2025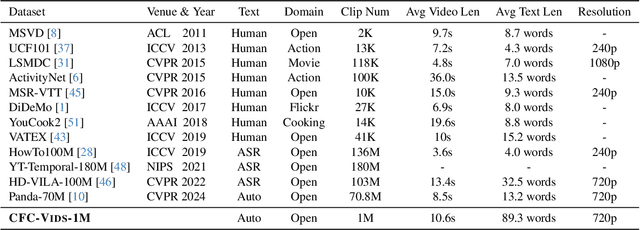


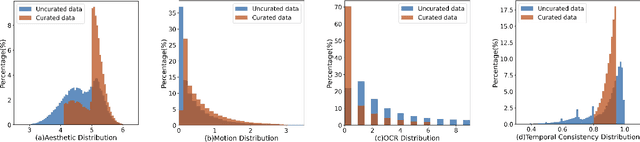
Text-to-video generation has demonstrated promising progress with the advent of diffusion models, yet existing approaches are limited by dataset quality and computational resources. To address these limitations, this paper presents a comprehensive approach that advances both data curation and model design. We introduce CFC-VIDS-1M, a high-quality video dataset constructed through a systematic coarse-to-fine curation pipeline. The pipeline first evaluates video quality across multiple dimensions, followed by a fine-grained stage that leverages vision-language models to enhance text-video alignment and semantic richness. Building upon the curated dataset's emphasis on visual quality and temporal coherence, we develop RACCOON, a transformer-based architecture with decoupled spatial-temporal attention mechanisms. The model is trained through a progressive four-stage strategy designed to efficiently handle the complexities of video generation. Extensive experiments demonstrate that our integrated approach of high-quality data curation and efficient training strategy generates visually appealing and temporally coherent videos while maintaining computational efficiency. We will release our dataset, code, and models.
LiFT: Leveraging Human Feedback for Text-to-Video Model Alignment
Dec 06, 2024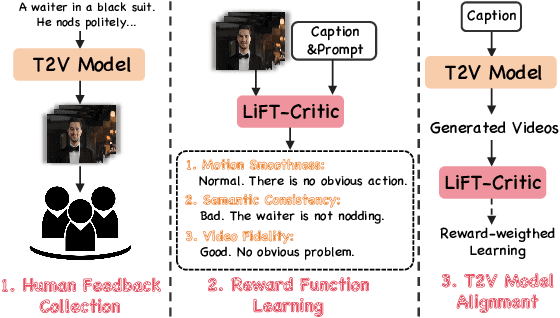
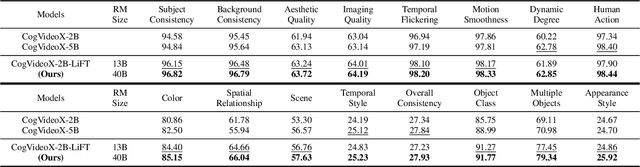
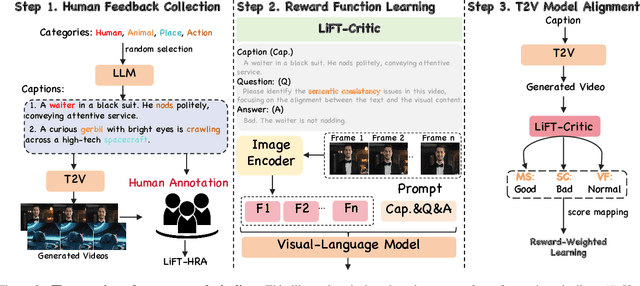
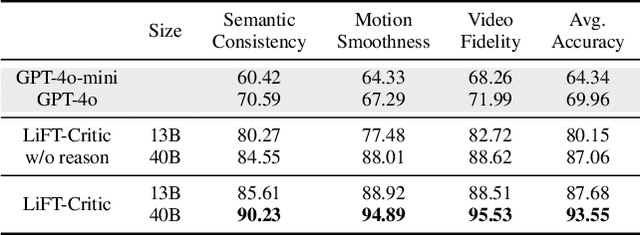
Recent advancements in text-to-video (T2V) generative models have shown impressive capabilities. However, these models are still inadequate in aligning synthesized videos with human preferences (e.g., accurately reflecting text descriptions), which is particularly difficult to address, as human preferences are inherently subjective and challenging to formalize as objective functions. Therefore, this paper proposes LiFT, a novel fine-tuning method leveraging human feedback for T2V model alignment. Specifically, we first construct a Human Rating Annotation dataset, LiFT-HRA, consisting of approximately 10k human annotations, each including a score and its corresponding rationale. Based on this, we train a reward model LiFT-Critic to learn reward function effectively, which serves as a proxy for human judgment, measuring the alignment between given videos and human expectations. Lastly, we leverage the learned reward function to align the T2V model by maximizing the reward-weighted likelihood. As a case study, we apply our pipeline to CogVideoX-2B, showing that the fine-tuned model outperforms the CogVideoX-5B across all 16 metrics, highlighting the potential of human feedback in improving the alignment and quality of synthesized videos.
Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
Mar 08, 2024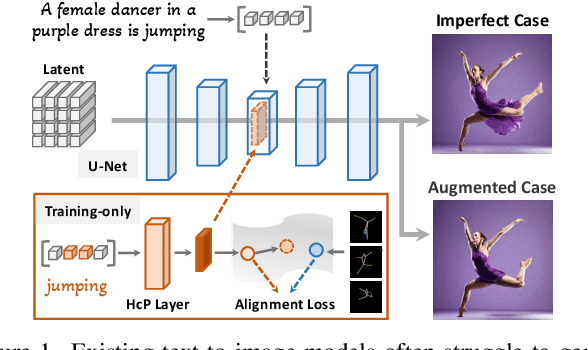
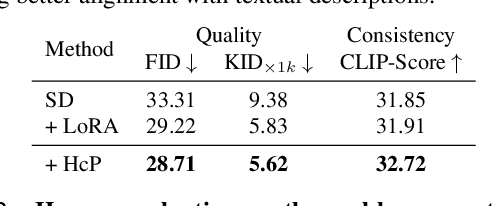
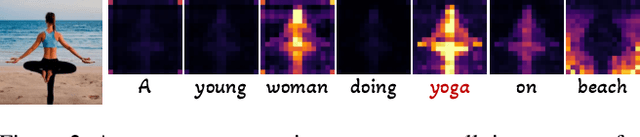
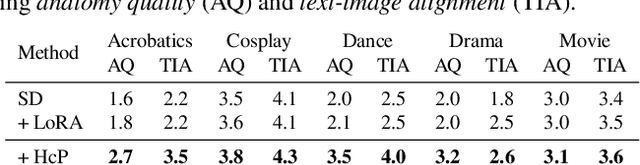
Vanilla text-to-image diffusion models struggle with generating accurate human images, commonly resulting in imperfect anatomies such as unnatural postures or disproportionate limbs.Existing methods address this issue mostly by fine-tuning the model with extra images or adding additional controls -- human-centric priors such as pose or depth maps -- during the image generation phase. This paper explores the integration of these human-centric priors directly into the model fine-tuning stage, essentially eliminating the need for extra conditions at the inference stage. We realize this idea by proposing a human-centric alignment loss to strengthen human-related information from the textual prompts within the cross-attention maps. To ensure semantic detail richness and human structural accuracy during fine-tuning, we introduce scale-aware and step-wise constraints within the diffusion process, according to an in-depth analysis of the cross-attention layer. Extensive experiments show that our method largely improves over state-of-the-art text-to-image models to synthesize high-quality human images based on user-written prompts. Project page: \url{https://hcplayercvpr2024.github.io}.
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition
Mar 05, 20233D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely. Highly efficient and expressive 3D CNN architectures, \ie entropy-based 3D CNNs (E3D family), can then be efficiently searched by maximizing the STEntr-Score under a given computational budget, via an evolutionary algorithm without training the network parameters. Extensive experiments on Something-Something V1\&V2 and Kinetics400 demonstrate that the E3D family achieves state-of-the-art performance with higher computational efficiency. Code is available at https://github.com/alibaba/lightweight-neural-architecture-search.