 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA ghost mechanism: An analytical model of abrupt learning
Jan 04, 2025\emph{Abrupt learning} is commonly observed in neural networks, where long plateaus in network performance are followed by rapid convergence to a desirable solution. Yet, despite its common occurrence, the complex interplay of task, network architecture, and learning rule has made it difficult to understand the underlying mechanisms. Here, we introduce a minimal dynamical system trained on a delayed-activation task and demonstrate analytically how even a one-dimensional system can exhibit abrupt learning through ghost points rather than bifurcations. Through our toy model, we show that the emergence of a ghost point destabilizes learning dynamics. We identify a critical learning rate that prevents learning through two distinct loss landscape features: a no-learning zone and an oscillatory minimum. Testing these predictions in recurrent neural networks (RNNs), we confirm that ghost points precede abrupt learning and accompany the destabilization of learning. We demonstrate two complementary remedies: lowering the model output confidence prevents the network from getting stuck in no-learning zones, while increasing trainable ranks beyond task requirements (\textit{i.e.}, adding sloppy parameters) provides more stable learning trajectories. Our model reveals a bifurcation-free mechanism for abrupt learning and illustrates the importance of both deliberate uncertainty and redundancy in stabilizing learning dynamics.
DAMO-YOLO : A Report on Real-Time Object Detection Design
Dec 15, 2022



In this report, we present a fast and accurate object detection method dubbed DAMO-YOLO, which achieves higher performance than the state-of-the-art YOLO series. DAMO-YOLO is extended from YOLO with some new technologies, including Neural Architecture Search (NAS), efficient Reparameterized Generalized-FPN (RepGFPN), a lightweight head with AlignedOTA label assignment, and distillation enhancement. In particular, we use MAE-NAS, a method guided by the principle of maximum entropy, to search our detection backbone under the constraints of low latency and high performance, producing ResNet-like / CSP-like structures with spatial pyramid pooling and focus modules. In the design of necks and heads, we follow the rule of "large neck, small head". We import Generalized-FPN with accelerated queen-fusion to build the detector neck and upgrade its CSPNet with efficient layer aggregation networks (ELAN) and reparameterization. Then we investigate how detector head size affects detection performance and find that a heavy neck with only one task projection layer would yield better results. In addition, AlignedOTA is proposed to solve the misalignment problem in label assignment. And a distillation schema is introduced to improve performance to a higher level. Based on these new techs, we build a suite of models at various scales to meet the needs of different scenarios, i.e., DAMO-YOLO-Tiny/Small/Medium. They can achieve 43.0/46.8/50.0 mAPs on COCO with the latency of 2.78/3.83/5.62 ms on T4 GPUs respectively. The code is available at https://github.com/tinyvision/damo-yolo.
GiraffeDet: A Heavy-Neck Paradigm for Object Detection
Feb 09, 2022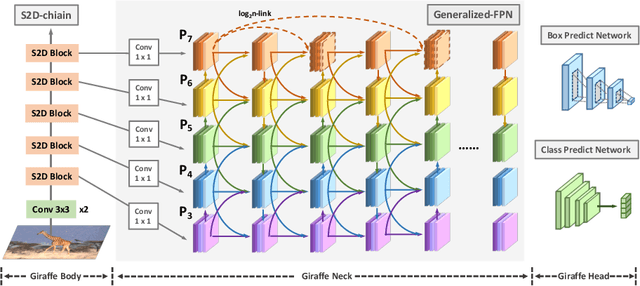
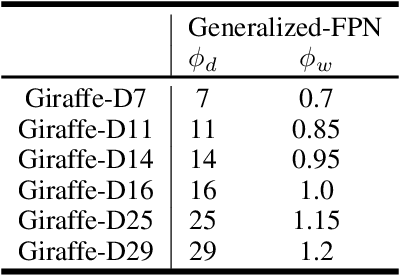
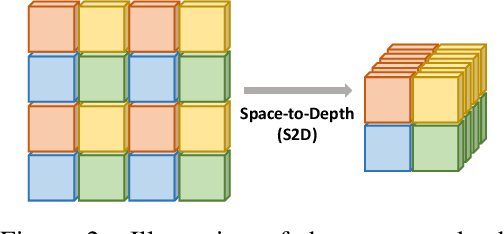
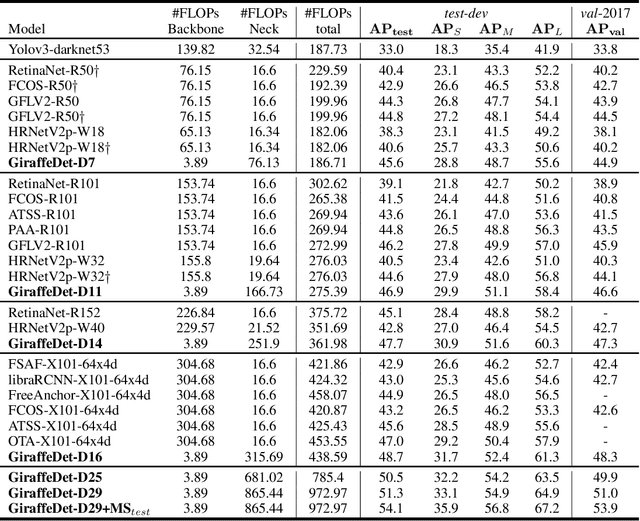
In conventional object detection frameworks, a backbone body inherited from image recognition models extracts deep latent features and then a neck module fuses these latent features to capture information at different scales. As the resolution in object detection is much larger than in image recognition, the computational cost of the backbone often dominates the total inference cost. This heavy-backbone design paradigm is mostly due to the historical legacy when transferring image recognition models to object detection rather than an end-to-end optimized design for object detection. In this work, we show that such paradigm indeed leads to sub-optimal object detection models. To this end, we propose a novel heavy-neck paradigm, GiraffeDet, a giraffe-like network for efficient object detection. The GiraffeDet uses an extremely lightweight backbone and a very deep and large neck module which encourages dense information exchange among different spatial scales as well as different levels of latent semantics simultaneously. This design paradigm allows detectors to process the high-level semantic information and low-level spatial information at the same priority even in the early stage of the network, making it more effective in detection tasks. Numerical evaluations on multiple popular object detection benchmarks show that GiraffeDet consistently outperforms previous SOTA models across a wide spectrum of resource constraints.
Exploring the Quality of GAN Generated Images for Person Re-Identification
Aug 23, 2021
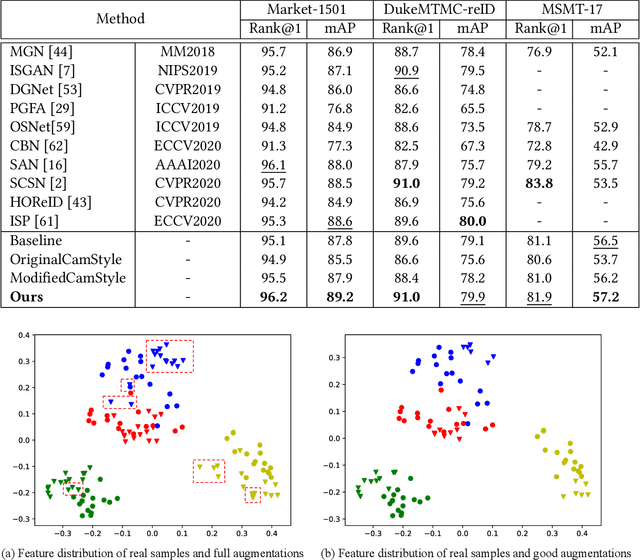


Recently, GAN based method has demonstrated strong effectiveness in generating augmentation data for person re-identification (ReID), on account of its ability to bridge the gap between domains and enrich the data variety in feature space. However, most of the ReID works pick all the GAN generated data as additional training samples or evaluate the quality of GAN generation at the entire data set level, ignoring the image-level essential feature of data in ReID task. In this paper, we analyze the in-depth characteristics of ReID sample and solve the problem of "What makes a GAN-generated image good for ReID". Specifically, we propose to examine each data sample with id-consistency and diversity constraints by mapping image onto different spaces. With a metric-based sampling method, we demonstrate that not every GAN-generated data is beneficial for augmentation. Models trained with data filtered by our quality evaluation outperform those trained with the full augmentation set by a large margin. Extensive experiments show the effectiveness of our method on both supervised ReID task and unsupervised domain adaptation ReID task.
An Empirical Study of Vehicle Re-Identification on the AI City Challenge
May 20, 2021
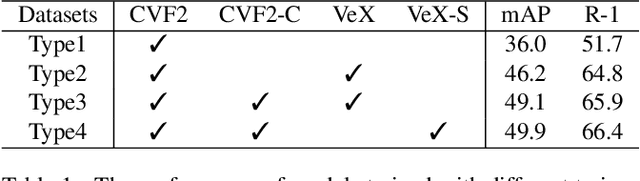
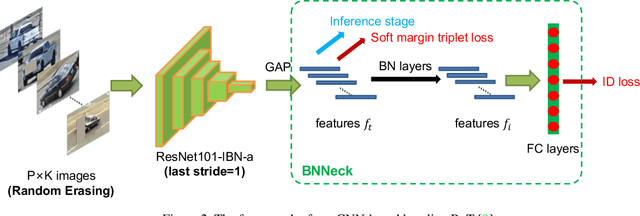

This paper introduces our solution for the Track2 in AI City Challenge 2021 (AICITY21). The Track2 is a vehicle re-identification (ReID) task with both the real-world data and synthetic data. We mainly focus on four points, i.e. training data, unsupervised domain-adaptive (UDA) training, post-processing, model ensembling in this challenge. (1) Both cropping training data and using synthetic data can help the model learn more discriminative features. (2) Since there is a new scenario in the test set that dose not appear in the training set, UDA methods perform well in the challenge. (3) Post-processing techniques including re-ranking, image-to-track retrieval, inter-camera fusion, etc, significantly improve final performance. (4) We ensemble CNN-based models and transformer-based models which provide different representation diversity. With aforementioned techniques, our method finally achieves 0.7445 mAP score, yielding the first place in the competition. Codes are available at https://github.com/michuanhaohao/AICITY2021_Track2_DMT.
1st Place Solution to VisDA-2020: Bias Elimination for Domain Adaptive Pedestrian Re-identification
Dec 25, 2020



This paper presents our proposed methods for domain adaptive pedestrian re-identification (Re-ID) task in Visual Domain Adaptation Challenge (VisDA-2020). Considering the large gap between the source domain and target domain, we focused on solving two biases that influenced the performance on domain adaptive pedestrian Re-ID and proposed a two-stage training procedure. At the first stage, a baseline model is trained with images transferred from source domain to target domain and from single camera to multiple camera styles. Then we introduced a domain adaptation framework to train the model on source data and target data simultaneously. Different pseudo label generation strategies are adopted to continuously improve the discriminative ability of the model. Finally, with multiple models ensembled and additional post processing approaches adopted, our methods achieve 76.56% mAP and 84.25% rank-1 on the test set. Codes are available at https://github.com/vimar-gu/Bias-Eliminate-DA-ReID