 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning
Oct 30, 2025Reinforcement finetuning (RFT) is a key technique for aligning Large Language Models (LLMs) with human preferences and enhancing reasoning, yet its effectiveness is highly sensitive to which tasks are explored during training. Uniform task sampling is inefficient, wasting computation on tasks that are either trivial or unsolvable, while existing task selection methods often suffer from high rollout costs, poor adaptivity, or incomplete evidence. We introduce \textbf{BOTS}, a unified framework for \textbf{B}ayesian \textbf{O}nline \textbf{T}ask \textbf{S}election in LLM reinforcement finetuning. Grounded in Bayesian inference, BOTS adaptively maintains posterior estimates of task difficulty as the model evolves. It jointly incorporates \emph{explicit evidence} from direct evaluations of selected tasks and \emph{implicit evidence} inferred from these evaluations for unselected tasks, with Thompson sampling ensuring a principled balance between exploration and exploitation. To make implicit evidence practical, we instantiate it with an ultra-light interpolation-based plug-in that estimates difficulties of unevaluated tasks without extra rollouts, adding negligible overhead. Empirically, across diverse domains and LLM scales, BOTS consistently improves data efficiency and performance over baselines and ablations, providing a practical and extensible solution for dynamic task selection in RFT.
FALCON: An ML Framework for Fully Automated Layout-Constrained Analog Circuit Design
May 28, 2025Designing analog circuits from performance specifications is a complex, multi-stage process encompassing topology selection, parameter inference, and layout feasibility. We introduce FALCON, a unified machine learning framework that enables fully automated, specification-driven analog circuit synthesis through topology selection and layout-constrained optimization. Given a target performance, FALCON first selects an appropriate circuit topology using a performance-driven classifier guided by human design heuristics. Next, it employs a custom, edge-centric graph neural network trained to map circuit topology and parameters to performance, enabling gradient-based parameter inference through the learned forward model. This inference is guided by a differentiable layout cost, derived from analytical equations capturing parasitic and frequency-dependent effects, and constrained by design rules. We train and evaluate FALCON on a large-scale custom dataset of 1M analog mm-wave circuits, generated and simulated using Cadence Spectre across 20 expert-designed topologies. Through this evaluation, FALCON demonstrates >99\% accuracy in topology inference, <10\% relative error in performance prediction, and efficient layout-aware design that completes in under 1 second per instance. Together, these results position FALCON as a practical and extensible foundation model for end-to-end analog circuit design automation.
Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
May 23, 2025Trinity-RFT is a general-purpose, flexible and scalable framework designed for reinforcement fine-tuning (RFT) of large language models. It is built with a decoupled design, consisting of (1) an RFT-core that unifies and generalizes synchronous/asynchronous, on-policy/off-policy, and online/offline modes of RFT, (2) seamless integration for agent-environment interaction with high efficiency and robustness, and (3) systematic data pipelines optimized for RFT. Trinity-RFT can be easily adapted for diverse application scenarios, and serves as a unified platform for exploring advanced reinforcement learning paradigms. This technical report outlines the vision, features, design and implementations of Trinity-RFT, accompanied by extensive examples demonstrating the utility and user-friendliness of the proposed framework.
DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?
May 22, 2025While recent text-to-image (T2I) models show impressive capabilities in synthesizing images from brief descriptions, their performance significantly degrades when confronted with long, detail-intensive prompts required in professional applications. We present DetailMaster, the first comprehensive benchmark specifically designed to evaluate T2I models' systematical abilities to handle extended textual inputs that contain complex compositional requirements. Our benchmark introduces four critical evaluation dimensions: Character Attributes, Structured Character Locations, Multi-Dimensional Scene Attributes, and Explicit Spatial/Interactive Relationships. The benchmark comprises long and detail-rich prompts averaging 284.89 tokens, with high quality validated by expert annotators. Evaluation on 7 general-purpose and 5 long-prompt-optimized T2I models reveals critical performance limitations: state-of-the-art models achieve merely ~50% accuracy in key dimensions like attribute binding and spatial reasoning, while all models showing progressive performance degradation as prompt length increases. Our analysis highlights systemic failures in structural comprehension and detail overload handling, motivating future research into architectures with enhanced compositional reasoning. We open-source the dataset, data curation code, and evaluation tools to advance detail-rich T2I generation and enable broad applications that would otherwise be infeasible due to the lack of a dedicated benchmark.
Img-Diff: Contrastive Data Synthesis for Multimodal Large Language Models
Aug 09, 2024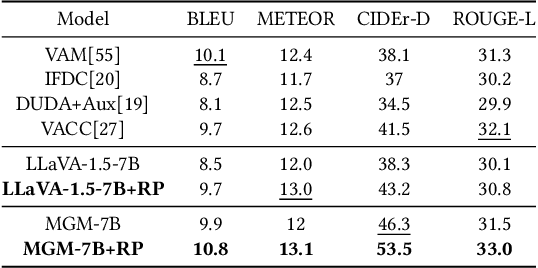
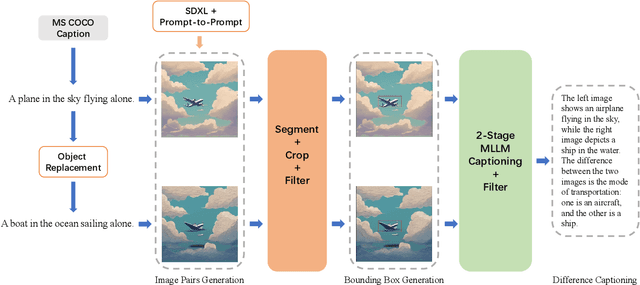
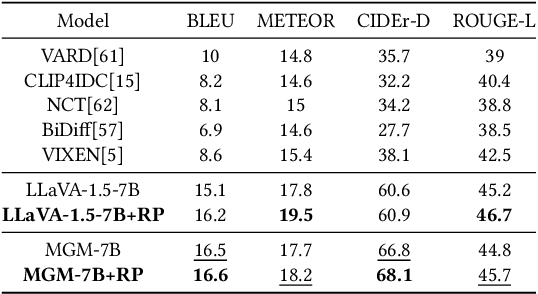
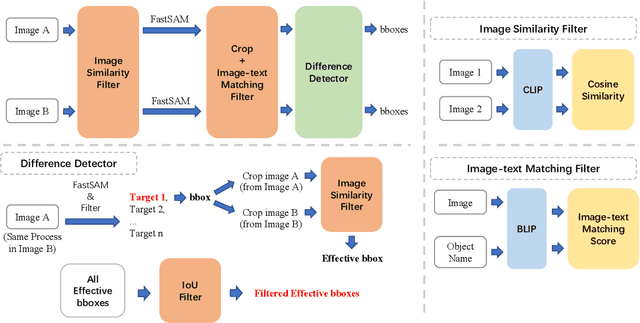
High-performance Multimodal Large Language Models (MLLMs) rely heavily on data quality. This study introduces a novel dataset named Img-Diff, designed to enhance fine-grained image recognition in MLLMs by leveraging insights from contrastive learning and image difference captioning. By analyzing object differences between similar images, we challenge models to identify both matching and distinct components. We utilize the Stable-Diffusion-XL model and advanced image editing techniques to create pairs of similar images that highlight object replacements. Our methodology includes a Difference Area Generator for object differences identifying, followed by a Difference Captions Generator for detailed difference descriptions. The result is a relatively small but high-quality dataset of "object replacement" samples. We use the the proposed dataset to finetune state-of-the-art (SOTA) MLLMs such as MGM-7B, yielding comprehensive improvements of performance scores over SOTA models that trained with larger-scale datasets, in numerous image difference and Visual Question Answering tasks. For instance, our trained models notably surpass the SOTA models GPT-4V and Gemini on the MMVP benchmark. Besides, we investigate alternative methods for generating image difference data through "object removal" and conduct a thorough evaluation to confirm the dataset's diversity, quality, and robustness, presenting several insights on the synthesis of such a contrastive dataset. To encourage further research and advance the field of multimodal data synthesis and enhancement of MLLMs' fundamental capabilities for image understanding, we release our codes and dataset at https://github.com/modelscope/data-juicer/tree/ImgDiff.
Data-Juicer Sandbox: A Comprehensive Suite for Multimodal Data-Model Co-development
Jul 16, 2024



The emergence of large-scale multi-modal generative models has drastically advanced artificial intelligence, introducing unprecedented levels of performance and functionality. However, optimizing these models remains challenging due to historically isolated paths of model-centric and data-centric developments, leading to suboptimal outcomes and inefficient resource utilization. In response, we present a novel sandbox suite tailored for integrated data-model co-development. This sandbox provides a comprehensive experimental platform, enabling rapid iteration and insight-driven refinement of both data and models. Our proposed "Probe-Analyze-Refine" workflow, validated through applications on state-of-the-art LLaVA-like and DiT based models, yields significant performance boosts, such as topping the VBench leaderboard. We also uncover fruitful insights gleaned from exhaustive benchmarks, shedding light on the critical interplay between data quality, diversity, and model behavior. With the hope of fostering deeper understanding and future progress in multi-modal data and generative modeling, our codes, datasets, and models are maintained and accessible at https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox.md.
The Synergy between Data and Multi-Modal Large Language Models: A Survey from Co-Development Perspective
Jul 11, 2024



The rapid development of large language models (LLMs) has been witnessed in recent years. Based on the powerful LLMs, multi-modal LLMs (MLLMs) extend the modality from text to a broader spectrum of domains, attracting widespread attention due to the broader range of application scenarios. As LLMs and MLLMs rely on vast amounts of model parameters and data to achieve emergent capabilities, the importance of data is receiving increasingly widespread attention and recognition. Tracing and analyzing recent data-oriented works for MLLMs, we find that the development of models and data is not two separate paths but rather interconnected. On the one hand, vaster and higher-quality data contribute to better performance of MLLMs, on the other hand, MLLMs can facilitate the development of data. The co-development of multi-modal data and MLLMs requires a clear view of 1) at which development stage of MLLMs can specific data-centric approaches be employed to enhance which capabilities, and 2) by utilizing which capabilities and acting as which roles can models contribute to multi-modal data. To promote the data-model co-development for MLLM community, we systematically review existing works related to MLLMs from the data-model co-development perspective. A regularly maintained project associated with this survey is accessible at https://github.com/modelscope/data-juicer/blob/main/docs/awesome_llm_data.md.
Enhancing Multimodal Large Language Models with Vision Detection Models: An Empirical Study
Jan 31, 2024
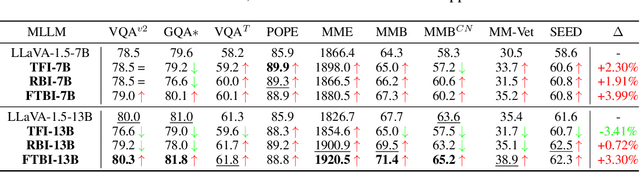


Despite the impressive capabilities of Multimodal Large Language Models (MLLMs) in integrating text and image modalities, challenges remain in accurately interpreting detailed visual elements. This paper presents an empirical study on enhancing MLLMs with state-of-the-art (SOTA) object detection and Optical Character Recognition models to improve fine-grained image understanding and reduce hallucination in responses. Our research investigates the embedding-based infusion of detection information, the impact of such infusion on the MLLMs' original abilities, and the interchangeability of detection models. We conduct systematic experiments with models such as LLaVA-1.5, DINO, and PaddleOCRv2, revealing that our approach not only refines MLLMs' performance in specific visual tasks but also maintains their original strengths. The resulting enhanced MLLMs outperform SOTA models on 9 out of 10 benchmarks, achieving an improvement of up to 12.99% on the normalized average score, marking a notable advancement in multimodal understanding. We release our codes to facilitate further exploration into the fine-grained multimodal dialogue capabilities of MLLMs.
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023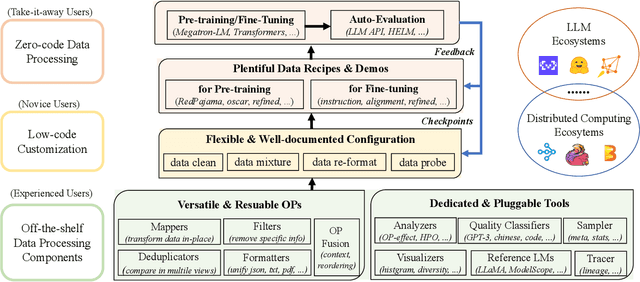
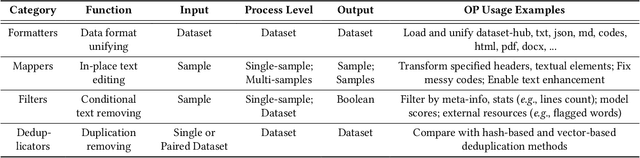
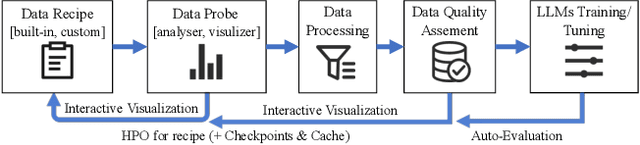
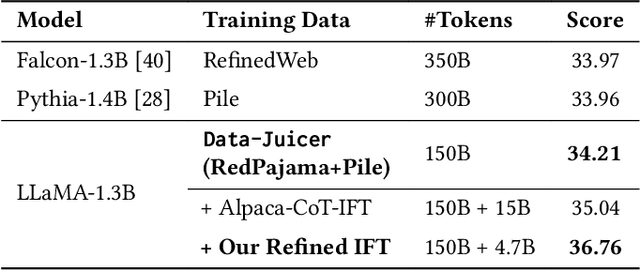
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.
DeepMAD: Mathematical Architecture Design for Deep Convolutional Neural Network
Mar 05, 2023



The rapid advances in Vision Transformer (ViT) refresh the state-of-the-art performances in various vision tasks, overshadowing the conventional CNN-based models. This ignites a few recent striking-back research in the CNN world showing that pure CNN models can achieve as good performance as ViT models when carefully tuned. While encouraging, designing such high-performance CNN models is challenging, requiring non-trivial prior knowledge of network design. To this end, a novel framework termed Mathematical Architecture Design for Deep CNN (DeepMAD) is proposed to design high-performance CNN models in a principled way. In DeepMAD, a CNN network is modeled as an information processing system whose expressiveness and effectiveness can be analytically formulated by their structural parameters. Then a constrained mathematical programming (MP) problem is proposed to optimize these structural parameters. The MP problem can be easily solved by off-the-shelf MP solvers on CPUs with a small memory footprint. In addition, DeepMAD is a pure mathematical framework: no GPU or training data is required during network design. The superiority of DeepMAD is validated on multiple large-scale computer vision benchmark datasets. Notably on ImageNet-1k, only using conventional convolutional layers, DeepMAD achieves 0.7% and 1.5% higher top-1 accuracy than ConvNeXt and Swin on Tiny level, and 0.8% and 0.9% higher on Small level.