 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailMaster: Can Your Text-to-Image Model Handle Long Prompts?
May 22, 2025While recent text-to-image (T2I) models show impressive capabilities in synthesizing images from brief descriptions, their performance significantly degrades when confronted with long, detail-intensive prompts required in professional applications. We present DetailMaster, the first comprehensive benchmark specifically designed to evaluate T2I models' systematical abilities to handle extended textual inputs that contain complex compositional requirements. Our benchmark introduces four critical evaluation dimensions: Character Attributes, Structured Character Locations, Multi-Dimensional Scene Attributes, and Explicit Spatial/Interactive Relationships. The benchmark comprises long and detail-rich prompts averaging 284.89 tokens, with high quality validated by expert annotators. Evaluation on 7 general-purpose and 5 long-prompt-optimized T2I models reveals critical performance limitations: state-of-the-art models achieve merely ~50% accuracy in key dimensions like attribute binding and spatial reasoning, while all models showing progressive performance degradation as prompt length increases. Our analysis highlights systemic failures in structural comprehension and detail overload handling, motivating future research into architectures with enhanced compositional reasoning. We open-source the dataset, data curation code, and evaluation tools to advance detail-rich T2I generation and enable broad applications that would otherwise be infeasible due to the lack of a dedicated benchmark.
HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
Dec 23, 2024



In the domain of Multimodal Large Language Models (MLLMs), achieving human-centric video understanding remains a formidable challenge. Existing benchmarks primarily emphasize object and action recognition, often neglecting the intricate nuances of human emotions, behaviors, and speech visual alignment within video content. We present HumanVBench, an innovative benchmark meticulously crafted to bridge these gaps in the evaluation of video MLLMs. HumanVBench comprises 17 carefully designed tasks that explore two primary dimensions: inner emotion and outer manifestations, spanning static and dynamic, basic and complex, as well as single-modal and cross-modal aspects. With two advanced automated pipelines for video annotation and distractor-included QA generation, HumanVBench utilizes diverse state-of-the-art (SOTA) techniques to streamline benchmark data synthesis and quality assessment, minimizing human annotation dependency tailored to human-centric multimodal attributes. A comprehensive evaluation across 16 SOTA video MLLMs reveals notable limitations in current performance, especially in cross-modal and temporal alignment, underscoring the necessity for further refinement toward achieving more human-like understanding. HumanVBench is open-sourced to facilitate future advancements and real-world applications in video MLLMs.
Img-Diff: Contrastive Data Synthesis for Multimodal Large Language Models
Aug 09, 2024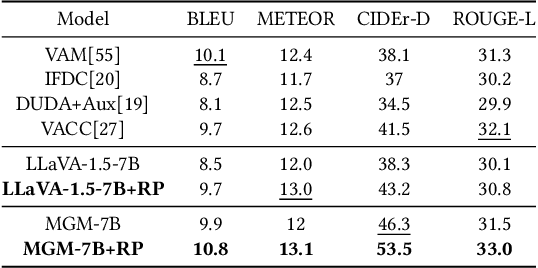
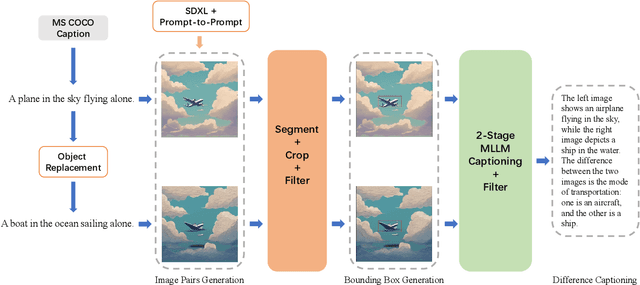
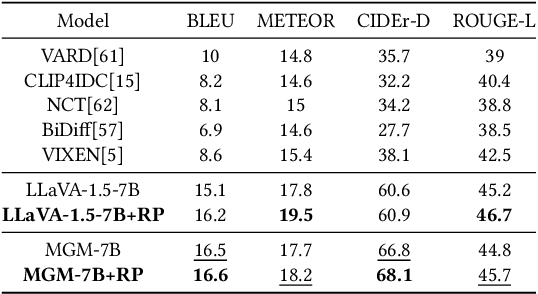
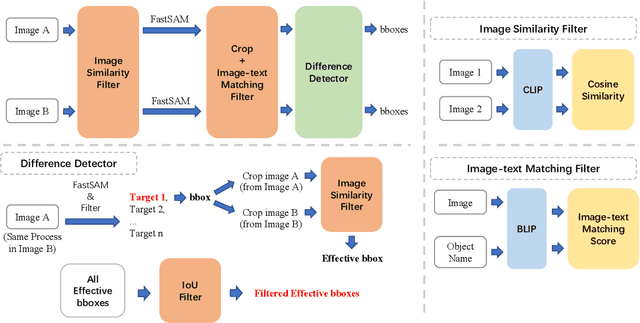
High-performance Multimodal Large Language Models (MLLMs) rely heavily on data quality. This study introduces a novel dataset named Img-Diff, designed to enhance fine-grained image recognition in MLLMs by leveraging insights from contrastive learning and image difference captioning. By analyzing object differences between similar images, we challenge models to identify both matching and distinct components. We utilize the Stable-Diffusion-XL model and advanced image editing techniques to create pairs of similar images that highlight object replacements. Our methodology includes a Difference Area Generator for object differences identifying, followed by a Difference Captions Generator for detailed difference descriptions. The result is a relatively small but high-quality dataset of "object replacement" samples. We use the the proposed dataset to finetune state-of-the-art (SOTA) MLLMs such as MGM-7B, yielding comprehensive improvements of performance scores over SOTA models that trained with larger-scale datasets, in numerous image difference and Visual Question Answering tasks. For instance, our trained models notably surpass the SOTA models GPT-4V and Gemini on the MMVP benchmark. Besides, we investigate alternative methods for generating image difference data through "object removal" and conduct a thorough evaluation to confirm the dataset's diversity, quality, and robustness, presenting several insights on the synthesis of such a contrastive dataset. To encourage further research and advance the field of multimodal data synthesis and enhancement of MLLMs' fundamental capabilities for image understanding, we release our codes and dataset at https://github.com/modelscope/data-juicer/tree/ImgDiff.
Enhancing Multimodal Large Language Models with Vision Detection Models: An Empirical Study
Jan 31, 2024
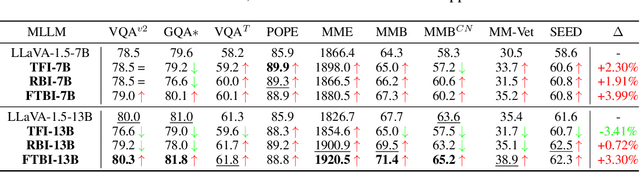


Despite the impressive capabilities of Multimodal Large Language Models (MLLMs) in integrating text and image modalities, challenges remain in accurately interpreting detailed visual elements. This paper presents an empirical study on enhancing MLLMs with state-of-the-art (SOTA) object detection and Optical Character Recognition models to improve fine-grained image understanding and reduce hallucination in responses. Our research investigates the embedding-based infusion of detection information, the impact of such infusion on the MLLMs' original abilities, and the interchangeability of detection models. We conduct systematic experiments with models such as LLaVA-1.5, DINO, and PaddleOCRv2, revealing that our approach not only refines MLLMs' performance in specific visual tasks but also maintains their original strengths. The resulting enhanced MLLMs outperform SOTA models on 9 out of 10 benchmarks, achieving an improvement of up to 12.99% on the normalized average score, marking a notable advancement in multimodal understanding. We release our codes to facilitate further exploration into the fine-grained multimodal dialogue capabilities of MLLMs.