 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Quality of GAN Generated Images for Person Re-Identification
Paper and Code
Aug 23, 2021
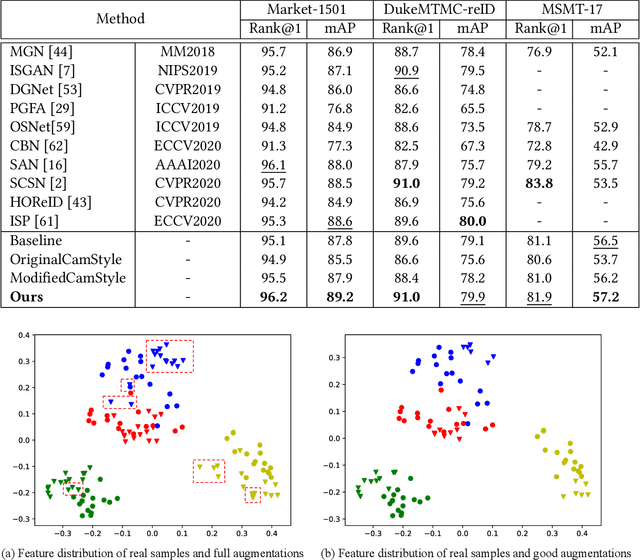


Recently, GAN based method has demonstrated strong effectiveness in generating augmentation data for person re-identification (ReID), on account of its ability to bridge the gap between domains and enrich the data variety in feature space. However, most of the ReID works pick all the GAN generated data as additional training samples or evaluate the quality of GAN generation at the entire data set level, ignoring the image-level essential feature of data in ReID task. In this paper, we analyze the in-depth characteristics of ReID sample and solve the problem of "What makes a GAN-generated image good for ReID". Specifically, we propose to examine each data sample with id-consistency and diversity constraints by mapping image onto different spaces. With a metric-based sampling method, we demonstrate that not every GAN-generated data is beneficial for augmentation. Models trained with data filtered by our quality evaluation outperform those trained with the full augmentation set by a large margin. Extensive experiments show the effectiveness of our method on both supervised ReID task and unsupervised domain adaptation ReID task.