 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Quest for Winning Tickets in Low-Rank Adapters
Dec 27, 2025The Lottery Ticket Hypothesis (LTH) suggests that over-parameterized neural networks contain sparse subnetworks ("winning tickets") capable of matching full model performance when trained from scratch. With the growing reliance on fine-tuning large pretrained models, we investigate whether LTH extends to parameter-efficient fine-tuning (PEFT), specifically focusing on Low-Rank Adaptation (LoRA) methods. Our key finding is that LTH holds within LoRAs, revealing sparse subnetworks that can match the performance of dense adapters. In particular, we find that the effectiveness of sparse subnetworks depends more on how much sparsity is applied in each layer than on the exact weights included in the subnetwork. Building on this insight, we propose Partial-LoRA, a method that systematically identifies said subnetworks and trains sparse low-rank adapters aligned with task-relevant subspaces of the pre-trained model. Experiments across 8 vision and 12 language tasks in both single-task and multi-task settings show that Partial-LoRA reduces the number of trainable parameters by up to 87\%, while maintaining or improving accuracy. Our results not only deepen our theoretical understanding of transfer learning and the interplay between pretraining and fine-tuning but also open new avenues for developing more efficient adaptation strategies.
Frame-wise Conditioning Adaptation for Fine-Tuning Diffusion Models in Text-to-Video Prediction
Mar 17, 2025Text-video prediction (TVP) is a downstream video generation task that requires a model to produce subsequent video frames given a series of initial video frames and text describing the required motion. In practice TVP methods focus on a particular category of videos depicting manipulations of objects carried out by human beings or robot arms. Previous methods adapt models pre-trained on text-to-image tasks, and thus tend to generate video that lacks the required continuity. A natural progression would be to leverage more recent pre-trained text-to-video (T2V) models. This approach is rendered more challenging by the fact that the most common fine-tuning technique, low-rank adaptation (LoRA), yields undesirable results. In this work, we propose an adaptation-based strategy we label Frame-wise Conditioning Adaptation (FCA). Within the module, we devise a sub-module that produces frame-wise text embeddings from the input text, which acts as an additional text condition to aid generation. We use FCA to fine-tune the T2V model, which incorporates the initial frame(s) as an extra condition. We compare and discuss the more effective strategy for injecting such embeddings into the T2V model. We conduct extensive ablation studies on our design choices with quantitative and qualitative performance analysis. Our approach establishes a new state-of-the-art for the task of TVP. The project page is at https://github.com/Cuberick-Orion/FCA .
RandLoRA: Full-rank parameter-efficient fine-tuning of large models
Feb 03, 2025Low-Rank Adaptation (LoRA) and its variants have shown impressive results in reducing the number of trainable parameters and memory requirements of large transformer networks while maintaining fine-tuning performance. However, the low-rank nature of the weight update inherently limits the representation power of fine-tuned models, potentially compromising performance on complex tasks. This raises a critical question: when a performance gap between LoRA and standard fine-tuning is observed, is it due to the reduced number of trainable parameters or the rank deficiency? This paper aims to answer this question by introducing RandLoRA, a parameter-efficient method that performs full-rank updates using a learned linear combinations of low-rank, non-trainable random matrices. Our method limits the number of trainable parameters by restricting optimization to diagonal scaling matrices applied to the fixed random matrices. This allows us to effectively overcome the low-rank limitations while maintaining parameter and memory efficiency during training. Through extensive experimentation across vision, language, and vision-language benchmarks, we systematically evaluate the limitations of LoRA and existing random basis methods. Our findings reveal that full-rank updates are beneficial across vision and language tasks individually, and even more so for vision-language tasks, where RandLoRA significantly reduces -- and sometimes eliminates -- the performance gap between standard fine-tuning and LoRA, demonstrating its efficacy.
Knowledge Composition using Task Vectors with Learned Anisotropic Scaling
Jul 03, 2024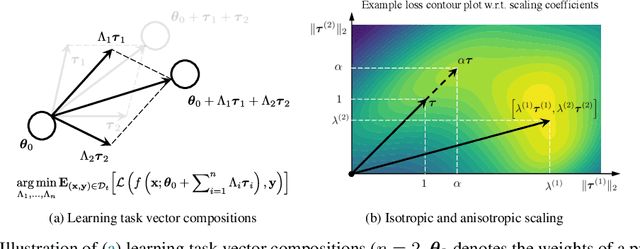
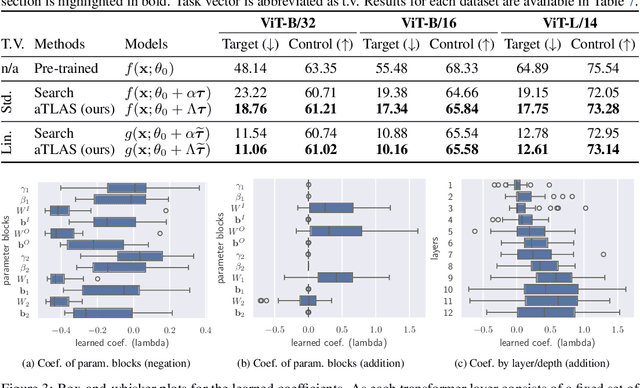
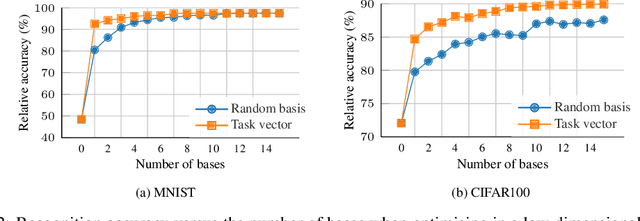
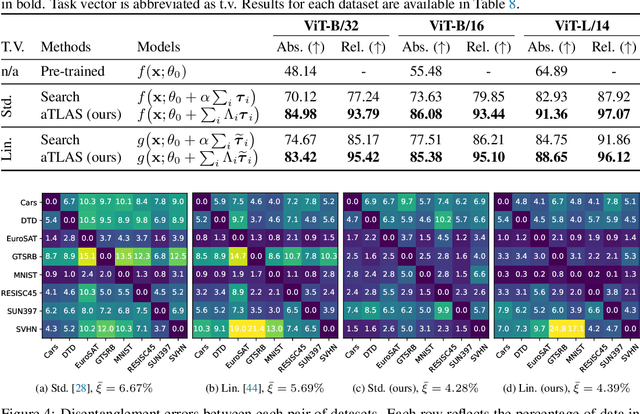
Pre-trained models produce strong generic representations that can be adapted via fine-tuning. The learned weight difference relative to the pre-trained model, known as a task vector, characterises the direction and stride of fine-tuning. The significance of task vectors is such that simple arithmetic operations on them can be used to combine diverse representations from different domains. This paper builds on these properties of task vectors and aims to answer (1) whether components of task vectors, particularly parameter blocks, exhibit similar characteristics, and (2) how such blocks can be used to enhance knowledge composition and transfer. To this end, we introduce aTLAS, an algorithm that linearly combines parameter blocks with different learned coefficients, resulting in anisotropic scaling at the task vector level. We show that such linear combinations explicitly exploit the low intrinsic dimensionality of pre-trained models, with only a few coefficients being the learnable parameters. Furthermore, composition of parameter blocks leverages the already learned representations, thereby reducing the dependency on large amounts of data. We demonstrate the effectiveness of our method in task arithmetic, few-shot recognition and test-time adaptation, with supervised or unsupervised objectives. In particular, we show that (1) learned anisotropic scaling allows task vectors to be more disentangled, causing less interference in composition; (2) task vector composition excels with scarce or no labeled data and is less prone to domain shift, thus leading to better generalisability; (3) mixing the most informative parameter blocks across different task vectors prior to training can reduce the memory footprint and improve the flexibility of knowledge transfer. Moreover, we show the potential of aTLAS as a PEFT method, particularly with less data, and demonstrate that its scalibility.
Synergy and Diversity in CLIP: Enhancing Performance Through Adaptive Backbone Ensembling
May 27, 2024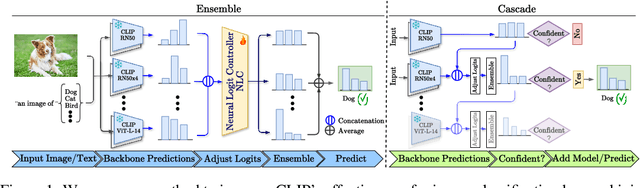
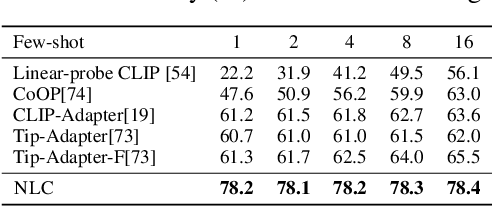
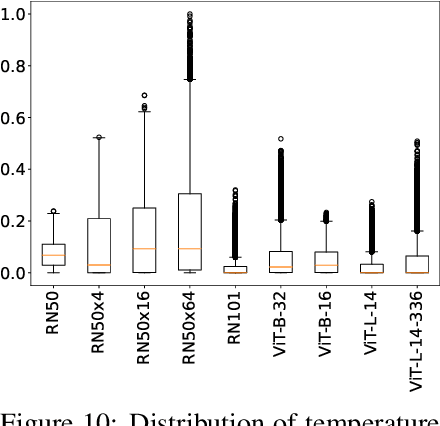
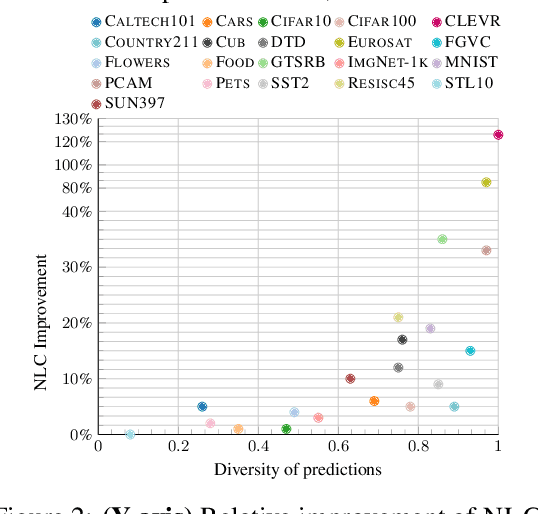
Contrastive Language-Image Pretraining (CLIP) stands out as a prominent method for image representation learning. Various architectures, from vision transformers (ViTs) to convolutional networks (ResNets) have been trained with CLIP to serve as general solutions to diverse vision tasks. This paper explores the differences across various CLIP-trained vision backbones. Despite using the same data and training objective, we find that these architectures have notably different representations, different classification performance across datasets, and different robustness properties to certain types of image perturbations. Our findings indicate a remarkable possible synergy across backbones by leveraging their respective strengths. In principle, classification accuracy could be improved by over 40 percentage with an informed selection of the optimal backbone per test example.Using this insight, we develop a straightforward yet powerful approach to adaptively ensemble multiple backbones. The approach uses as few as one labeled example per class to tune the adaptive combination of backbones. On a large collection of datasets, the method achieves a remarkable increase in accuracy of up to 39.1% over the best single backbone, well beyond traditional ensembles
Unveiling Backbone Effects in CLIP: Exploring Representational Synergies and Variances
Dec 22, 2023Contrastive Language-Image Pretraining (CLIP) stands out as a prominent method for image representation learning. Various neural architectures, spanning Transformer-based models like Vision Transformers (ViTs) to Convolutional Networks (ConvNets) like ResNets, are trained with CLIP and serve as universal backbones across diverse vision tasks. Despite utilizing the same data and training objectives, the effectiveness of representations learned by these architectures raises a critical question. Our investigation explores the differences in CLIP performance among these backbone architectures, revealing significant disparities in their classifications. Notably, normalizing these representations results in substantial performance variations. Our findings showcase a remarkable possible synergy between backbone predictions that could reach an improvement of over 20% through informed selection of the appropriate backbone. Moreover, we propose a simple, yet effective approach to combine predictions from multiple backbones, leading to a notable performance boost of up to 6.34\%. We will release the code for reproducing the results.
LocFormer: Enabling Transformers to Perform Temporal Moment Localization on Long Untrimmed Videos With a Feature Sampling Approach
Dec 19, 2021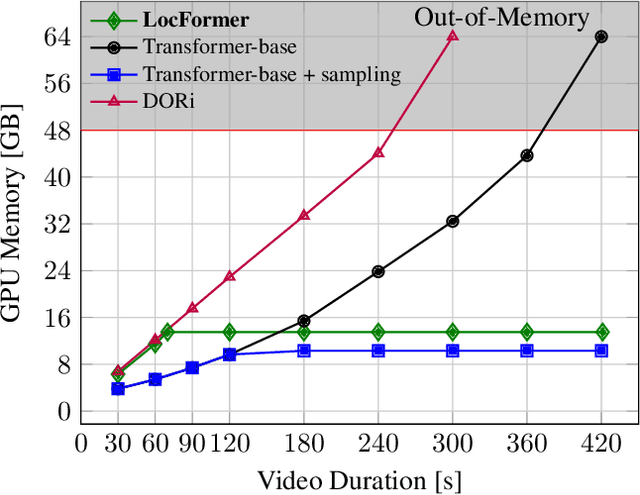
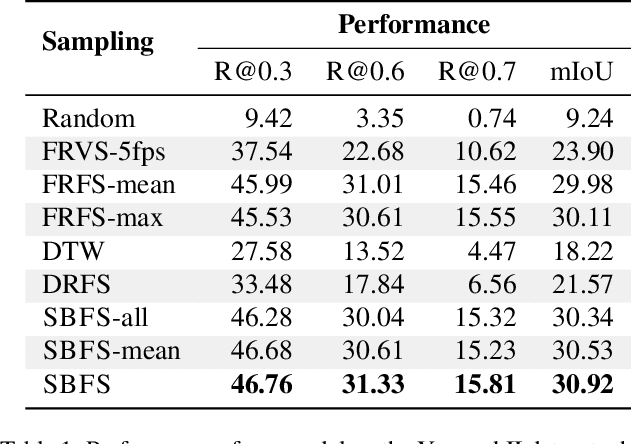
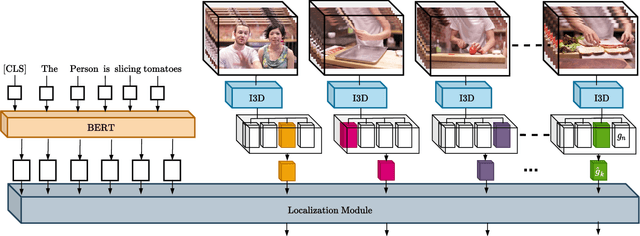
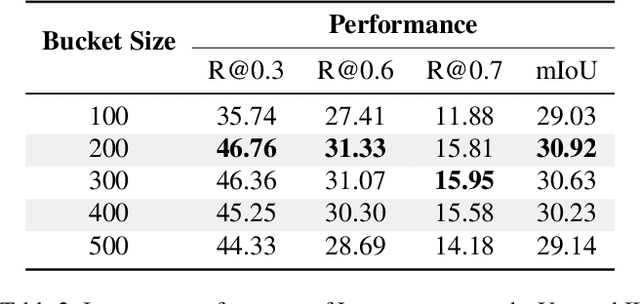
We propose LocFormer, a Transformer-based model for video grounding which operates at a constant memory footprint regardless of the video length, i.e. number of frames. LocFormer is designed for tasks where it is necessary to process the entire long video and at its core lie two main contributions. First, our model incorporates a new sampling technique that splits the input feature sequence into a fixed number of sections and selects a single feature per section using a stochastic approach, which allows us to obtain a feature sample set that is representative of the video content for the task at hand while keeping the memory footprint constant. Second, we propose a modular design that separates functionality, enabling us to learn an inductive bias via supervising the self-attention heads, while also effectively leveraging pre-trained text and video encoders. We test our proposals on relevant benchmark datasets for video grounding, showing that not only LocFormer can achieve excellent results including state-of-the-art performance on YouCookII, but also that our sampling technique is more effective than competing counterparts and that it consistently improves the performance of prior work, by up to 3.13\% in the mean temporal IoU, ultimately leading to a new state-of-the-art performance on Charades-STA.
Image Retrieval on Real-life Images with Pre-trained Vision-and-Language Models
Aug 09, 2021

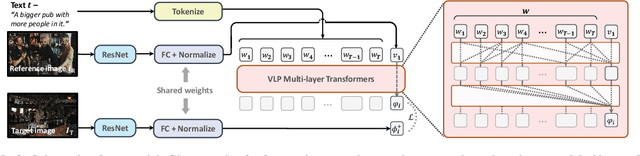
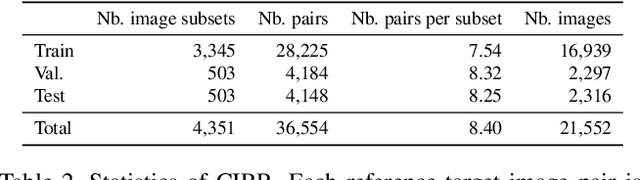
We extend the task of composed image retrieval, where an input query consists of an image and short textual description of how to modify the image. Existing methods have only been applied to non-complex images within narrow domains, such as fashion products, thereby limiting the scope of study on in-depth visual reasoning in rich image and language contexts. To address this issue, we collect the Compose Image Retrieval on Real-life images (CIRR) dataset, which consists of over 36,000 pairs of crowd-sourced, open-domain images with human-generated modifying text. To extend current methods to the open-domain, we propose CIRPLANT, a transformer based model that leverages rich pre-trained vision-and-language (V&L) knowledge for modifying visual features conditioned on natural language. Retrieval is then done by nearest neighbor lookup on the modified features. We demonstrate that with a relatively simple architecture, CIRPLANT outperforms existing methods on open-domain images, while matching state-of-the-art accuracy on the existing narrow datasets, such as fashion. Together with the release of CIRR, we believe this work will inspire further research on composed image retrieval.
A Recurrent Vision-and-Language BERT for Navigation
Nov 26, 2020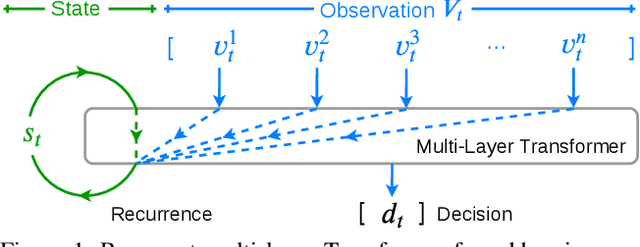
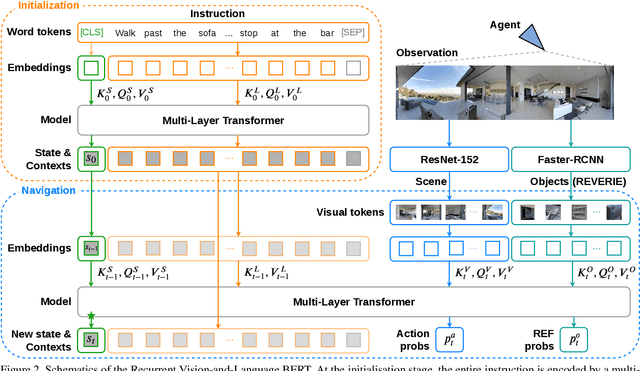
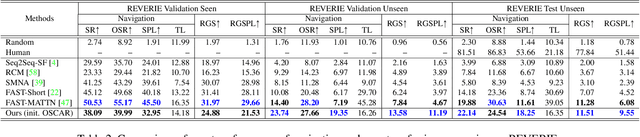
Accuracy of many visiolinguistic tasks has benefited significantly from the application of vision-and-language (V&L) BERT. However, its application for the task of vision-and-language navigation (VLN) remains limited. One reason for this is the difficulty adapting the BERT architecture to the partially observable Markov decision process present in VLN, requiring history-dependent attention and decision making. In this paper we propose a recurrent BERT model that is time-aware for use in VLN. Specifically, we equip the BERT model with a recurrent function that maintains cross-modal state information for the agent. Through extensive experiments on R2R and REVERIE we demonstrate that our model can replace more complex encoder-decoder models to achieve state-of-the-art results. Moreover, our approach can be generalised to other transformer-based architectures, supports pre-training, and is capable of multi-task learning suggesting the potential to merge a wide range of BERT-like models for other vision and language tasks.
Language and Visual Entity Relationship Graph for Agent Navigation
Oct 19, 2020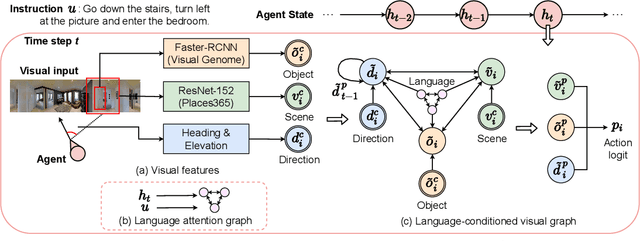
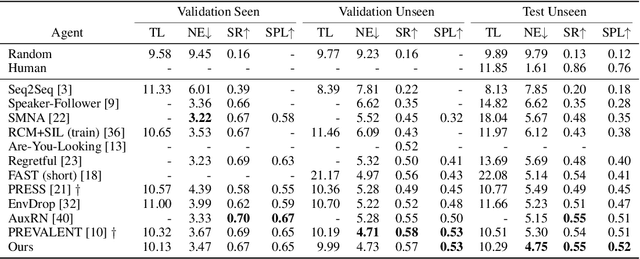
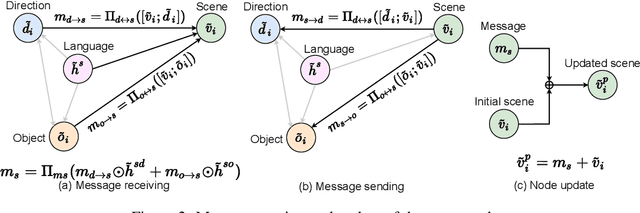
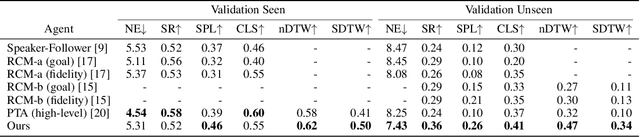
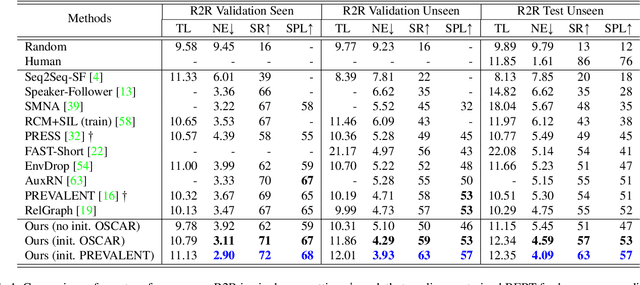
Vision-and-Language Navigation (VLN) requires an agent to navigate in a real-world environment following natural language instructions. From both the textual and visual perspectives, we find that the relationships among the scene, its objects,and directional clues are essential for the agent to interpret complex instructions and correctly perceive the environment. To capture and utilize the relationships, we propose a novel Language and Visual Entity Relationship Graph for modelling the inter-modal relationships between text and vision, and the intra-modal relationships among visual entities. We propose a message passing algorithm for propagating information between language elements and visual entities in the graph, which we then combine to determine the next action to take. Experiments show that by taking advantage of the relationships we are able to improve over state-of-the-art. On the Room-to-Room (R2R) benchmark, our method achieves the new best performance on the test unseen split with success rate weighted by path length (SPL) of 52%. On the Room-for-Room (R4R) dataset, our method significantly improves the previous best from 13% to 34% on the success weighted by normalized dynamic time warping (SDTW). Code is available at: https://github.com/YicongHong/Entity-Graph-VLN.