 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruth as a Trajectory: What Internal Representations Reveal About Large Language Model Reasoning
Mar 01, 2026Existing explainability methods for Large Language Models (LLMs) typically treat hidden states as static points in activation space, assuming that correct and incorrect inferences can be separated using representations from an individual layer. However, these activations are saturated with polysemantic features, leading to linear probes learning surface-level lexical patterns rather than underlying reasoning structures. We introduce Truth as a Trajectory (TaT), which models the transformer inference as an unfolded trajectory of iterative refinements, shifting analysis from static activations to layer-wise geometric displacement. By analyzing displacement of representations across layers, TaT uncovers geometric invariants that distinguish valid reasoning from spurious behavior. We evaluate TaT across dense and Mixture-of-Experts (MoE) architectures on benchmarks spanning commonsense reasoning, question answering, and toxicity detection. Without access to the activations themselves and using only changes in activations across layers, we show that TaT effectively mitigates reliance on static lexical confounds, outperforming conventional probing, and establishes trajectory analysis as a complementary perspective on LLM explainability.
Decomposing Task Vectors for Refined Model Editing
Dec 27, 2025Large pre-trained models have transformed machine learning, yet adapting these models effectively to exhibit precise, concept-specific behaviors remains a significant challenge. Task vectors, defined as the difference between fine-tuned and pre-trained model parameters, provide a mechanism for steering neural networks toward desired behaviors. This has given rise to large repositories dedicated to task vectors tailored for specific behaviors. The arithmetic operation of these task vectors allows for the seamless combination of desired behaviors without the need for large datasets. However, these vectors often contain overlapping concepts that can interfere with each other during arithmetic operations, leading to unpredictable outcomes. We propose a principled decomposition method that separates each task vector into two components: one capturing shared knowledge across multiple task vectors, and another isolating information unique to each specific task. By identifying invariant subspaces across projections, our approach enables more precise control over concept manipulation without unintended amplification or diminution of other behaviors. We demonstrate the effectiveness of our decomposition method across three domains: improving multi-task merging in image classification by 5% using shared components as additional task vectors, enabling clean style mixing in diffusion models without generation degradation by mixing only the unique components, and achieving 47% toxicity reduction in language models while preserving performance on general knowledge tasks by negating the toxic information isolated to the unique component. Our approach provides a new framework for understanding and controlling task vector arithmetic, addressing fundamental limitations in model editing operations.
The Quest for Winning Tickets in Low-Rank Adapters
Dec 27, 2025The Lottery Ticket Hypothesis (LTH) suggests that over-parameterized neural networks contain sparse subnetworks ("winning tickets") capable of matching full model performance when trained from scratch. With the growing reliance on fine-tuning large pretrained models, we investigate whether LTH extends to parameter-efficient fine-tuning (PEFT), specifically focusing on Low-Rank Adaptation (LoRA) methods. Our key finding is that LTH holds within LoRAs, revealing sparse subnetworks that can match the performance of dense adapters. In particular, we find that the effectiveness of sparse subnetworks depends more on how much sparsity is applied in each layer than on the exact weights included in the subnetwork. Building on this insight, we propose Partial-LoRA, a method that systematically identifies said subnetworks and trains sparse low-rank adapters aligned with task-relevant subspaces of the pre-trained model. Experiments across 8 vision and 12 language tasks in both single-task and multi-task settings show that Partial-LoRA reduces the number of trainable parameters by up to 87\%, while maintaining or improving accuracy. Our results not only deepen our theoretical understanding of transfer learning and the interplay between pretraining and fine-tuning but also open new avenues for developing more efficient adaptation strategies.
Synergy and Diversity in CLIP: Enhancing Performance Through Adaptive Backbone Ensembling
May 27, 2024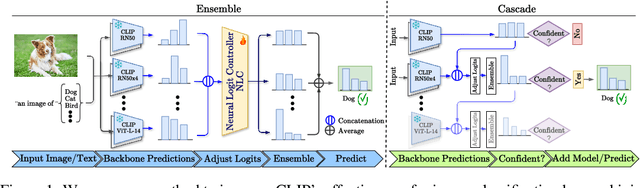
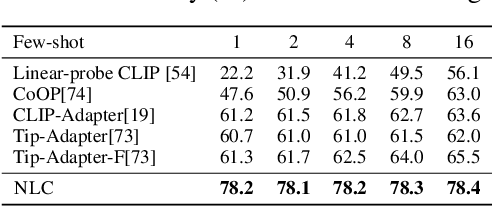
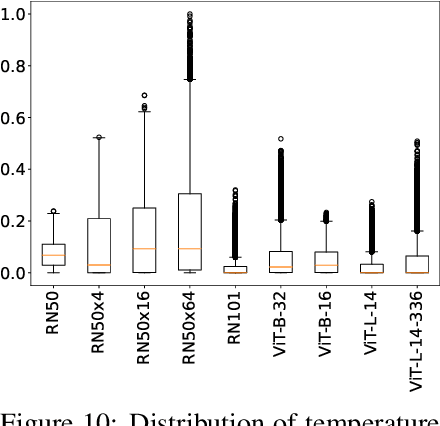
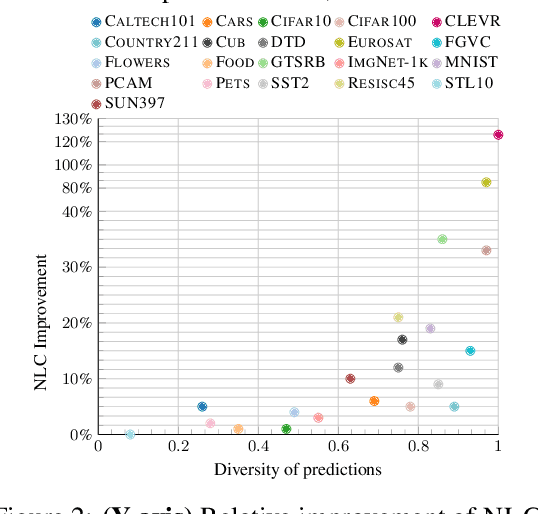
Contrastive Language-Image Pretraining (CLIP) stands out as a prominent method for image representation learning. Various architectures, from vision transformers (ViTs) to convolutional networks (ResNets) have been trained with CLIP to serve as general solutions to diverse vision tasks. This paper explores the differences across various CLIP-trained vision backbones. Despite using the same data and training objective, we find that these architectures have notably different representations, different classification performance across datasets, and different robustness properties to certain types of image perturbations. Our findings indicate a remarkable possible synergy across backbones by leveraging their respective strengths. In principle, classification accuracy could be improved by over 40 percentage with an informed selection of the optimal backbone per test example.Using this insight, we develop a straightforward yet powerful approach to adaptively ensemble multiple backbones. The approach uses as few as one labeled example per class to tune the adaptive combination of backbones. On a large collection of datasets, the method achieves a remarkable increase in accuracy of up to 39.1% over the best single backbone, well beyond traditional ensembles
Unveiling Backbone Effects in CLIP: Exploring Representational Synergies and Variances
Dec 22, 2023Contrastive Language-Image Pretraining (CLIP) stands out as a prominent method for image representation learning. Various neural architectures, spanning Transformer-based models like Vision Transformers (ViTs) to Convolutional Networks (ConvNets) like ResNets, are trained with CLIP and serve as universal backbones across diverse vision tasks. Despite utilizing the same data and training objectives, the effectiveness of representations learned by these architectures raises a critical question. Our investigation explores the differences in CLIP performance among these backbone architectures, revealing significant disparities in their classifications. Notably, normalizing these representations results in substantial performance variations. Our findings showcase a remarkable possible synergy between backbone predictions that could reach an improvement of over 20% through informed selection of the appropriate backbone. Moreover, we propose a simple, yet effective approach to combine predictions from multiple backbones, leading to a notable performance boost of up to 6.34\%. We will release the code for reproducing the results.
Zero-shot Retrieval: Augmenting Pre-trained Models with Search Engines
Nov 29, 2023Large pre-trained models can dramatically reduce the amount of task-specific data required to solve a problem, but they often fail to capture domain-specific nuances out of the box. The Web likely contains the information necessary to excel on any specific application, but identifying the right data a priori is challenging. This paper shows how to leverage recent advances in NLP and multi-modal learning to augment a pre-trained model with search engine retrieval. We propose to retrieve useful data from the Web at test time based on test cases that the model is uncertain about. Different from existing retrieval-augmented approaches, we then update the model to address this underlying uncertainty. We demonstrate substantial improvements in zero-shot performance, e.g. a remarkable increase of 15 percentage points in accuracy on the Stanford Cars and Flowers datasets. We also present extensive experiments that explore the impact of noisy retrieval and different learning strategies.
Independent Modular Networks
Jun 02, 2023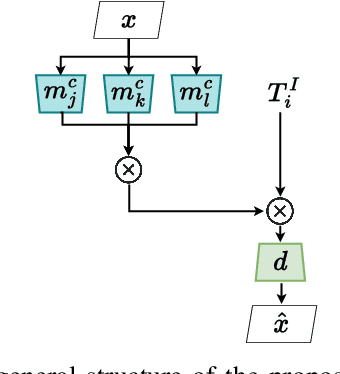
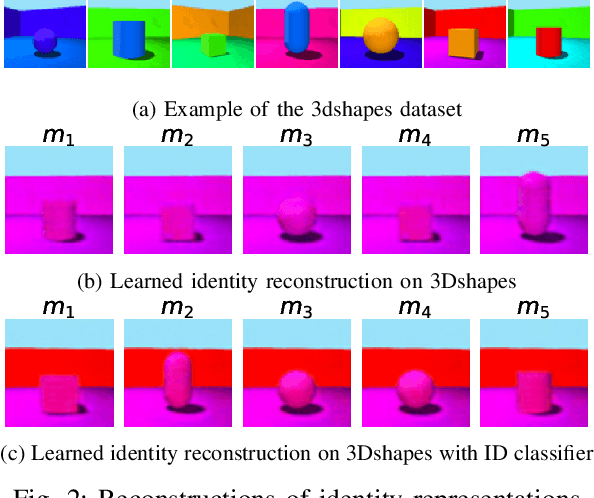
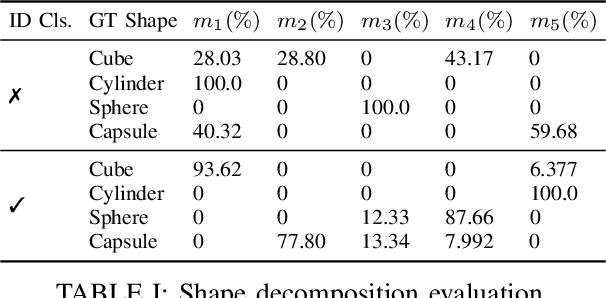
Monolithic neural networks that make use of a single set of weights to learn useful representations for downstream tasks explicitly dismiss the compositional nature of data generation processes. This characteristic exists in data where every instance can be regarded as the combination of an identity concept, such as the shape of an object, combined with modifying concepts, such as orientation, color, and size. The dismissal of compositionality is especially detrimental in robotics, where state estimation relies heavily on the compositional nature of physical mechanisms (e.g., rotations and transformations) to model interactions. To accommodate this data characteristic, modular networks have been proposed. However, a lack of structure in each module's role, and modular network-specific issues such as module collapse have restricted their usability. We propose a modular network architecture that accommodates the mentioned decompositional concept by proposing a unique structure that splits the modules into predetermined roles. Additionally, we provide regularizations that improve the resiliency of the modular network to the problem of module collapse while improving the decomposition accuracy of the model.
Action Capsules: Human Skeleton Action Recognition
Jan 30, 2023Due to the compact and rich high-level representations offered, skeleton-based human action recognition has recently become a highly active research topic. Previous studies have demonstrated that investigating joint relationships in spatial and temporal dimensions provides effective information critical to action recognition. However, effectively encoding global dependencies of joints during spatio-temporal feature extraction is still challenging. In this paper, we introduce Action Capsule which identifies action-related key joints by considering the latent correlation of joints in a skeleton sequence. We show that, during inference, our end-to-end network pays attention to a set of joints specific to each action, whose encoded spatio-temporal features are aggregated to recognize the action. Additionally, the use of multiple stages of action capsules enhances the ability of the network to classify similar actions. Consequently, our network outperforms the state-of-the-art approaches on the N-UCLA dataset and obtains competitive results on the NTURGBD dataset. This is while our approach has significantly lower computational requirements based on GFLOPs measurements.
A Consistency-Based Loss for Deep Odometry Through Uncertainty Propagation
Jul 01, 2021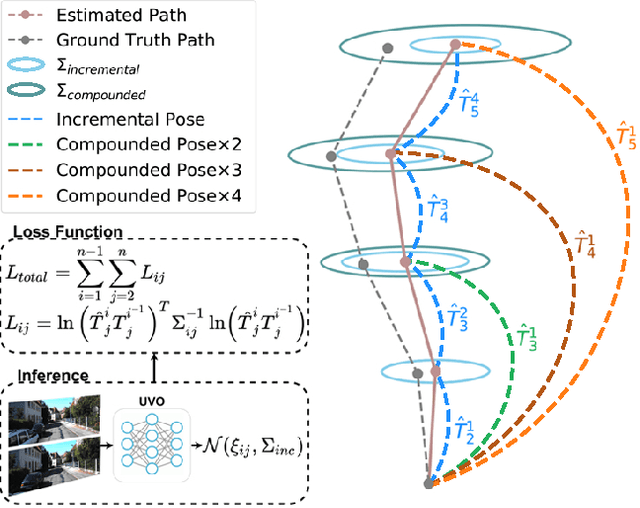
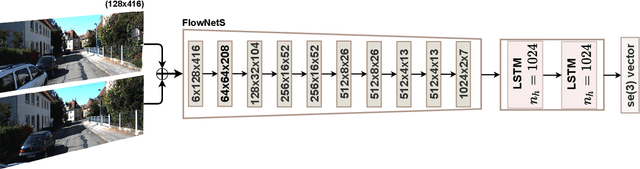
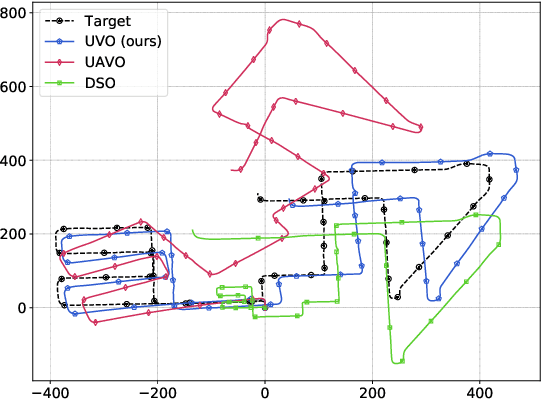
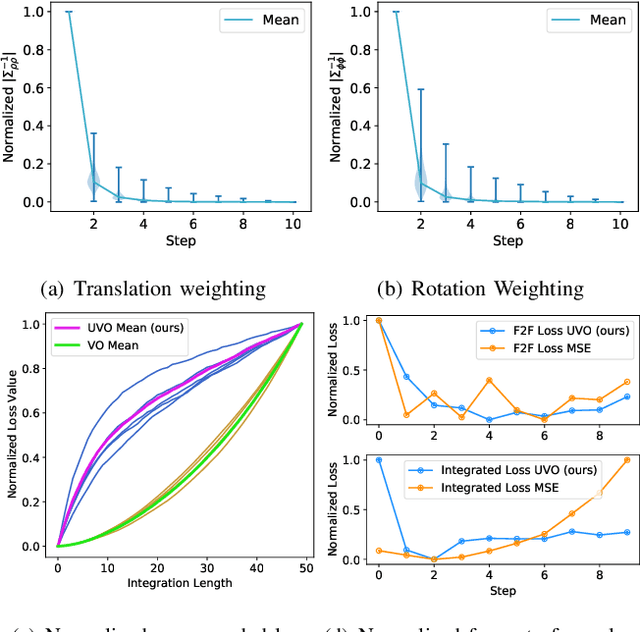
The incremental poses computed through odometry can be integrated over time to calculate the pose of a device with respect to an initial location. The resulting global pose may be used to formulate a second, consistency based, loss term in a deep odometry setting. In such cases where multiple losses are imposed on a network, the uncertainty over each output can be derived to weigh the different loss terms in a maximum likelihood setting. However, when imposing a constraint on the integrated transformation, due to how only odometry is estimated at each iteration of the algorithm, there is no information about the uncertainty associated with the global pose to weigh the global loss term. In this paper, we associate uncertainties with the output poses of a deep odometry network and propagate the uncertainties through each iteration. Our goal is to use the estimated covariance matrix at each incremental step to weigh the loss at the corresponding step while weighting the global loss term using the compounded uncertainty. This formulation provides an adaptive method to weigh the incremental and integrated loss terms against each other, noting the increase in uncertainty as new estimates arrive. We provide quantitative and qualitative analysis of pose estimates and show that our method surpasses the accuracy of the state-of-the-art Visual Odometry approaches. Then, uncertainty estimates are evaluated and comparisons against fixed baselines are provided. Finally, the uncertainty values are used in a realistic example to show the effectiveness of uncertainty quantification for localization.
Deep Inertial Odometry with Accurate IMU Preintegration
Jan 18, 2021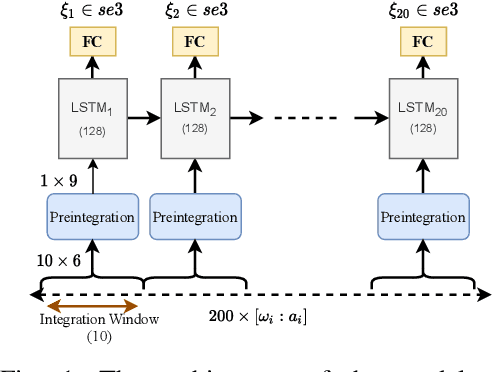
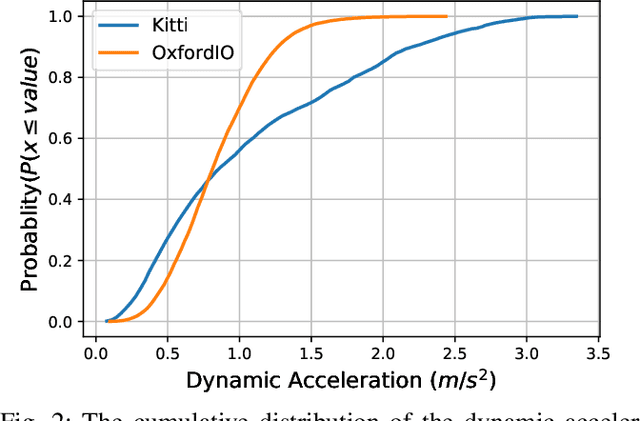
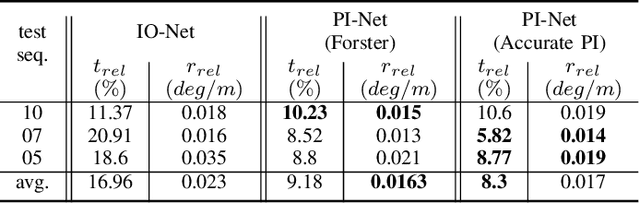
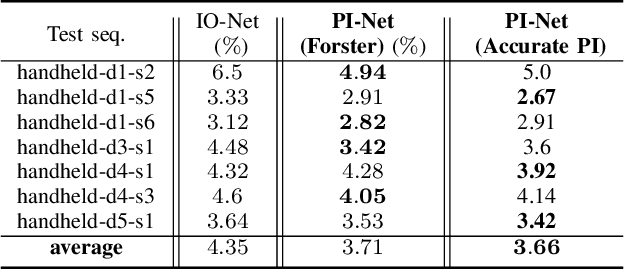
Inertial Measurement Units (IMUs) are interceptive modalities that provide ego-motion measurements independent of the environmental factors. They are widely adopted in various autonomous systems. Motivated by the limitations in processing the noisy measurements from these sensors using their mathematical models, researchers have recently proposed various deep learning architectures to estimate inertial odometry in an end-to-end manner. Nevertheless, the high-frequency and redundant measurements from IMUs lead to long raw sequences to be processed. In this study, we aim to investigate the efficacy of accurate preintegration as a more realistic solution to the IMU motion model for deep inertial odometry (DIO) and the resultant DIO is a fusion of model-driven and data-driven approaches. The accurate IMU preintegration has the potential to outperform numerical approximation of the continuous IMU model used in the existing DIOs. Experimental results validate the proposed DIO.