 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Self-Attention for Visual Odometry
Paper and Code
Nov 17, 2020
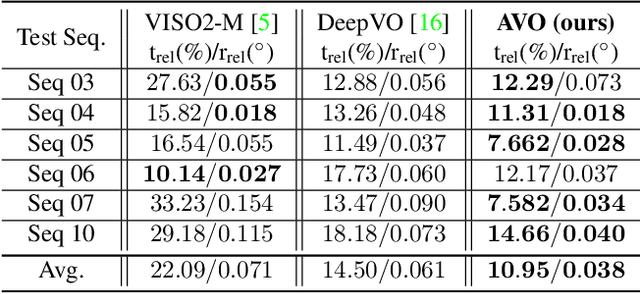
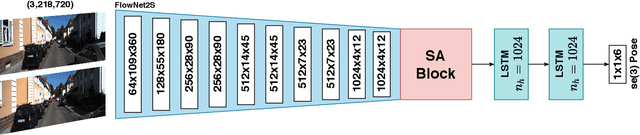
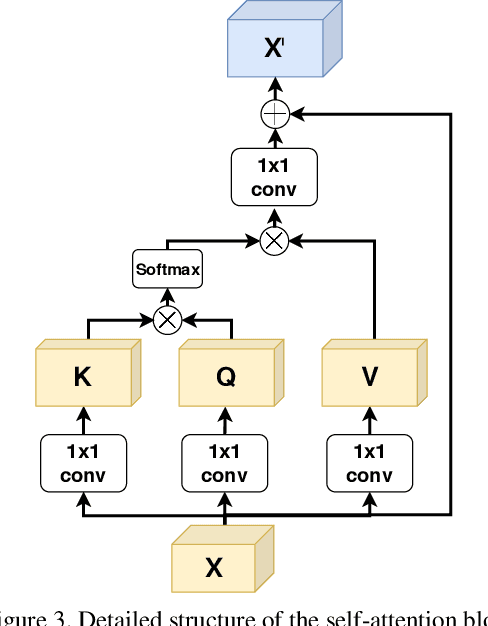
Visual odometry networks commonly use pretrained optical flow networks in order to derive the ego-motion between consecutive frames. The features extracted by these networks represent the motion of all the pixels between frames. However, due to the existence of dynamic objects and texture-less surfaces in the scene, the motion information for every image region might not be reliable for inferring odometry due to the ineffectiveness of dynamic objects in derivation of the incremental changes in position. Recent works in this area lack attention mechanisms in their structures to facilitate dynamic reweighing of the feature maps for extracting more refined egomotion information. In this paper, we explore the effectiveness of self-attention in visual odometry. We report qualitative and quantitative results against the SOTA methods. Furthermore, saliency-based studies alongside specially designed experiments are utilized to investigate the effect of self-attention on VO. Our experiments show that using self-attention allows for the extraction of better features while achieving a better odometry performance compared to networks that lack such structures.