 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Capsules: Human Skeleton Action Recognition
Jan 30, 2023Due to the compact and rich high-level representations offered, skeleton-based human action recognition has recently become a highly active research topic. Previous studies have demonstrated that investigating joint relationships in spatial and temporal dimensions provides effective information critical to action recognition. However, effectively encoding global dependencies of joints during spatio-temporal feature extraction is still challenging. In this paper, we introduce Action Capsule which identifies action-related key joints by considering the latent correlation of joints in a skeleton sequence. We show that, during inference, our end-to-end network pays attention to a set of joints specific to each action, whose encoded spatio-temporal features are aggregated to recognize the action. Additionally, the use of multiple stages of action capsules enhances the ability of the network to classify similar actions. Consequently, our network outperforms the state-of-the-art approaches on the N-UCLA dataset and obtains competitive results on the NTURGBD dataset. This is while our approach has significantly lower computational requirements based on GFLOPs measurements.
Online Probabilistic Model Identification using Adaptive Recursive MCMC
Oct 23, 2022



The Bayesian paradigm provides a rigorous framework for estimating the whole probability distribution over unknown parameters, but due to high computational costs, its online application can be difficult. We propose the Adaptive Recursive Markov Chain Monte Carlo (ARMCMC) method, which calculates the complete probability density function of model parameters while alleviating the drawbacks of traditional online methods. These flaws include being limited to Gaussian noise, being solely applicable to linear in the parameters (LIP) systems, and having persisting excitation requirements (PE). A variable jump distribution based on a temporal forgetting factor (TFF) is proposed in ARMCMC. The TFF can be utilized in many dynamical systems as an effective way to adaptively present the forgetting factor instead of a constant hyperparameter. The particular jump distribution has tailored towards hybrid/multi-modal systems that enables inferences among modes by providing a trade-off between exploitation and exploration. These trade-off are adjusted based on parameter evolution rate. In comparison to traditional MCMC techniques, we show that ARMCMC requires fewer samples to obtain the same accuracy and reliability. We show our method on two challenging benchmarks: parameter estimation in a soft bending actuator and the Hunt-Crossley dynamic model. We also compare our method with recursive least squares and the particle filter, and show that our technique has significantly more accurate point estimates as well as a decrease in tracking error of the value of interest.
A Segment-Wise Gaussian Process-Based Ground Segmentation With Local Smoothness Estimation
Oct 19, 2022
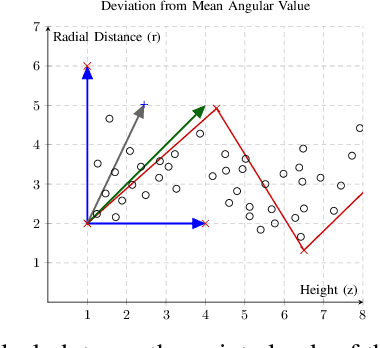
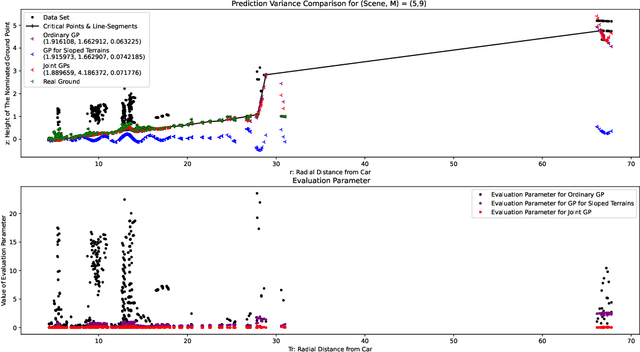
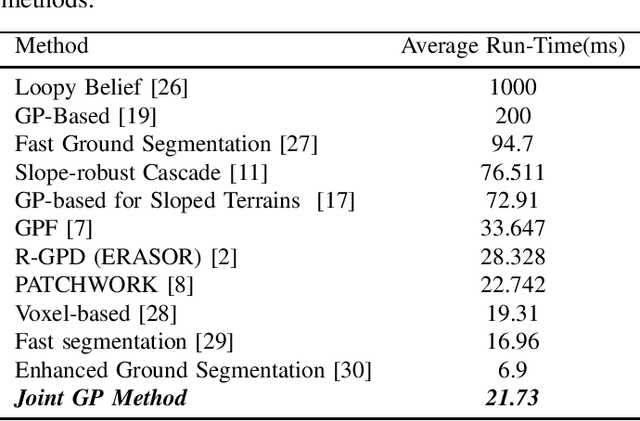
Both in terrestrial and extraterrestrial environments, the precise and informative model of the ground and the surface ahead is crucial for navigation and obstacle avoidance. The ground surface is not always flat and it may be sloped, bumpy and rough specially in off-road terrestrial scenes. In bumpy and rough scenes the functional relationship of the surface-related features may vary in different areas of the ground, as the structure of the ground surface may vary suddenly and further the measured point cloud of the ground does not bear smoothness. Thus, the ground-related features must be obtained based on local estimates or even point estimates. To tackle this problem, the segment-wise GP-based ground segmentation method with local smoothness estimation is proposed. This method is an extension to our previous method in which a realistic measurement of the length-scale values were provided for the covariance kernel in each line-segment to give precise estimation of the ground for sloped terrains. In this extension, the value of the length-scale is estimated locally for each data point which makes it much more precise for the rough scenes while being not computationally complex and more robust to under-segmentation, sparsity and under-represent-ability. The segment-wise task is performed to estimate a partial continuous model of the ground for each radial range segment. Simulation results show the effectiveness of the proposed method to give a continuous and precise estimation of the ground surface in rough and bumpy scenes while being fast enough for real-world applications.
A Novel Gaussian Process Based Ground Segmentation Algorithm with Local-Smoothness Estimation
Dec 01, 2021
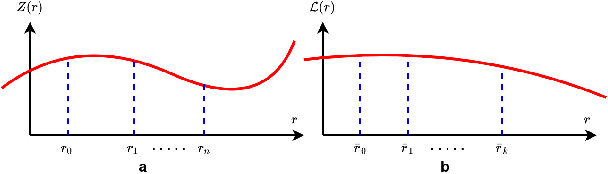
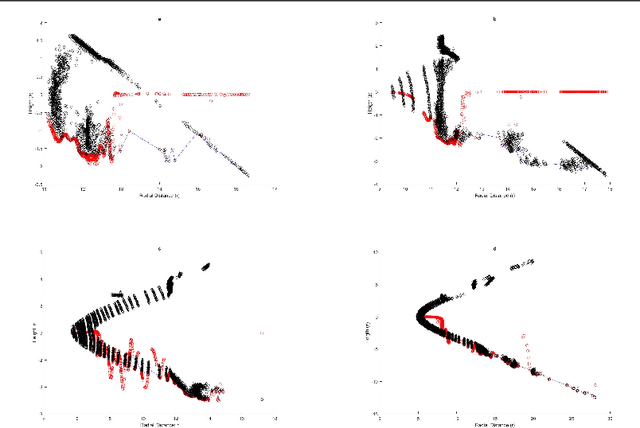
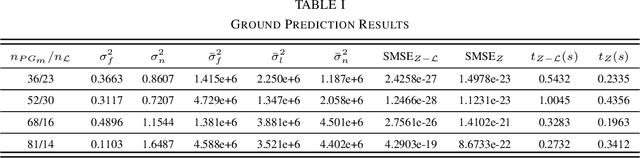
Autonomous Land Vehicles (ALV) shall efficiently recognize the ground in unknown environments. A novel $\mathcal{GP}$-based method is proposed for the ground segmentation task in rough driving scenarios. A non-stationary covariance function is utilized as the kernel for the $\mathcal{GP}$. The ground surface behavior is assumed to only demonstrate local-smoothness. Thus, point estimates of the kernel's length-scales are obtained. Thus, two Gaussian processes are introduced to separately model the observation and local characteristics of the data. While, the \textit{observation process} is used to model the ground, the \textit{latent process} is put on length-scale values to estimate point values of length-scales at each input location. Input locations for this latent process are chosen in a physically-motivated procedure to represent an intuition about ground condition. Furthermore, an intuitive guess of length-scale value is represented by assuming the existence of hypothetical surfaces in the environment that every bunch of data points may be assumed to be resulted from measurements from this surfaces. Bayesian inference is implemented using \textit{maximum a Posteriori} criterion. The log-marginal likelihood function is assumed to be a multi-task objective function, to represent a whole-frame unbiased view of the ground at each frame. Simulation results shows the effectiveness of the proposed method even in an uneven, rough scene which outperforms similar Gaussian process based ground segmentation methods. While adjacent segments do not have similar ground structure in an uneven scene, the proposed method gives an efficient ground estimation based on a whole-frame viewpoint instead of just estimating segment-wise probable ground surfaces.
A Gaussian Process-Based Ground Segmentation for Sloped Terrains
Nov 20, 2021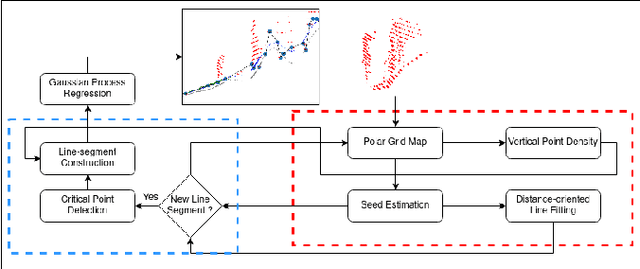
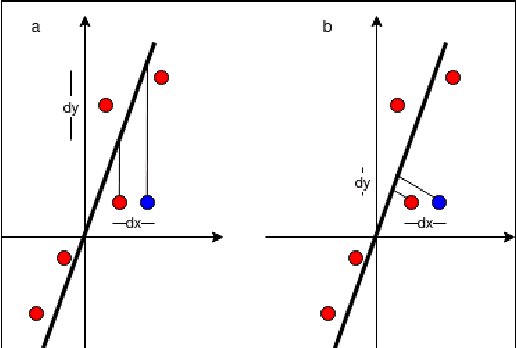
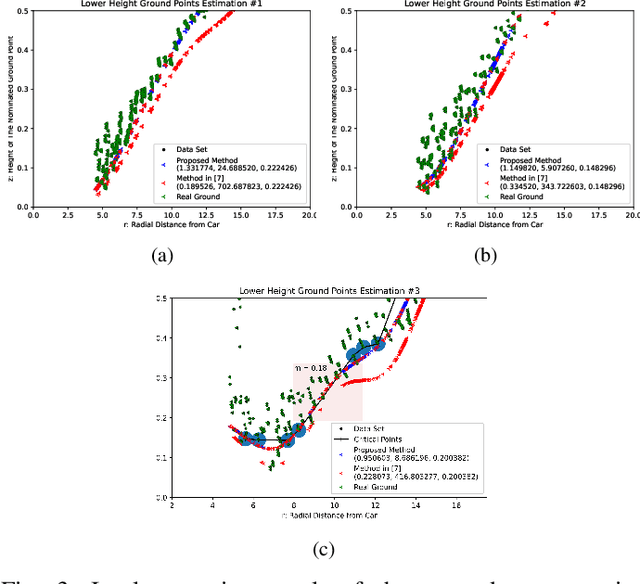
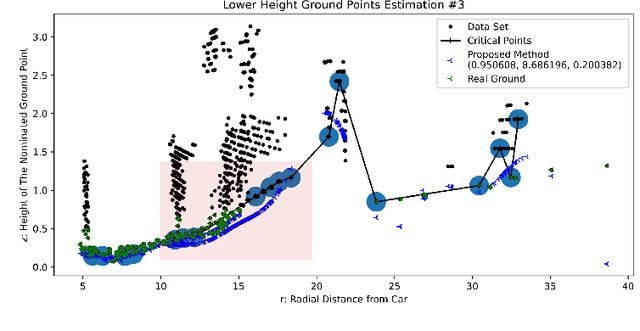
A Gaussian Process GP based ground segmentation method is proposed in this paper which is fully developed in a probabilistic framework. The proposed method tends to obtain a continuous realistic model of the ground. The LiDAR three-dimensional point cloud data is used as the sole source of the input data. The physical realities of the data are taken into account to properly classify sloped ground as well as the flat ones. Furthermore, unlike conventional ground segmentation methods, no height or distance constraints or limitations are required for the algorithm to be applied to take all the regarding physical behavior of the ground into account. Furthermore, a density-like parameter is defined to handle ground-like obstacle points in the ground candidate set. The non-stationary covariance kernel function is used for the Gaussian Process, by which Bayesian inference is applied using the maximum A Posteriori criterion. The log-marginal likelihood function is assumed to be a multi-task objective function, to represent a whole-frame unbiased view of the ground at each frame. Simulation results show the effectiveness of the proposed method even in an uneven, rough scene which outperforms similar Gaussian process-based ground segmentation methods.
Dynamic Models of Spherical Parallel Robots for Model-Based Control Schemes
Oct 01, 2021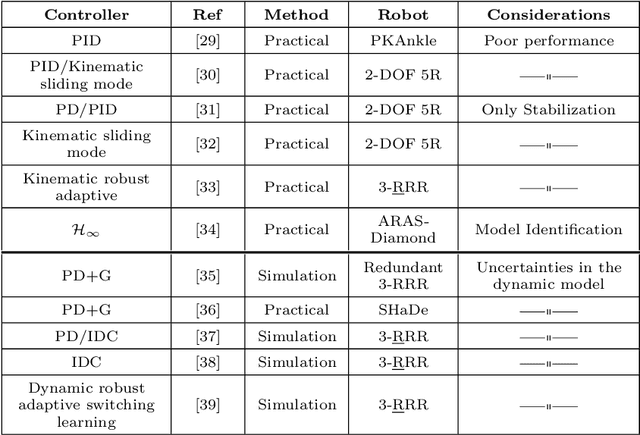
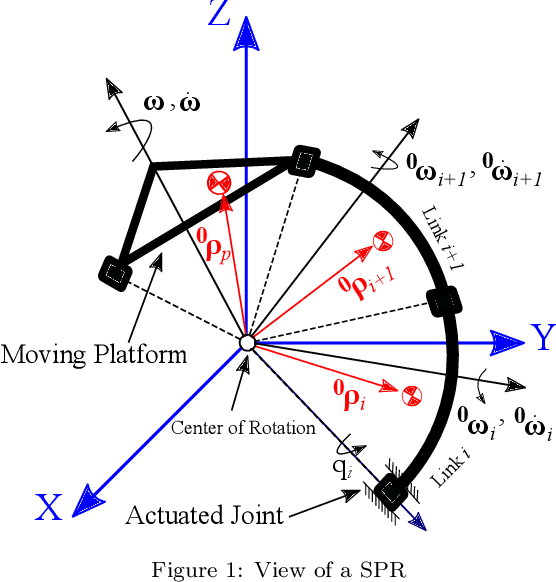
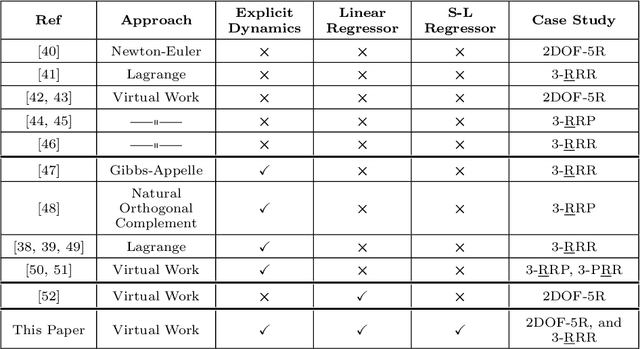
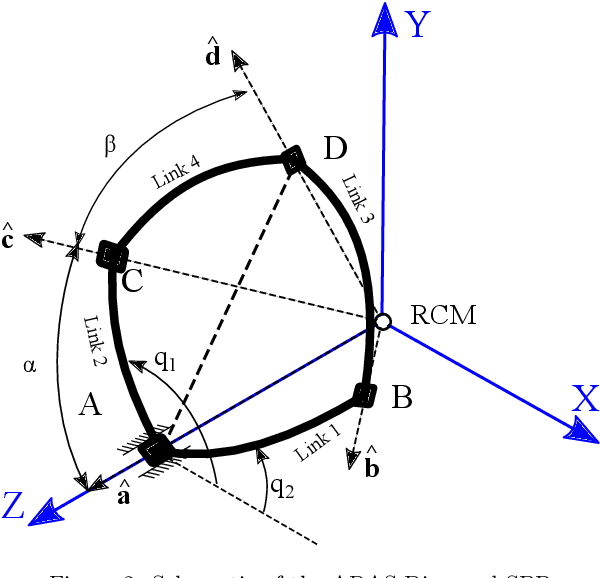
In this paper, derivation of different forms of dynamic formulation of spherical parallel robots (SPRs) is investigated. These formulations include the explicit dynamic forms, linear regressor, and Slotine-Li (SL) regressor, which are required for the design and implementation of the vast majority of model-based controllers and dynamic parameters identification schemes. To this end, the implicit dynamic of SPRs is first formulated using the principle of virtual work in task-space, and then by using an extension, their explicit dynamic formulation is derived. The dynamic equation is then analytically reformulated into linear and S-L regression form with respect to the inertial parameters, and by using the Gauss-Jordan procedure, it is reduced to a unique and closed-form structure. Finally, to illustrate the effectiveness of the proposed method, two different SPRs, namely, the ARAS-Diamond, and the 3-RRR, are examined as the case studies. The obtained results are verified by using the MSC-ADAMS software, and are shared to interested audience for public access.
A Consistency-Based Loss for Deep Odometry Through Uncertainty Propagation
Jul 01, 2021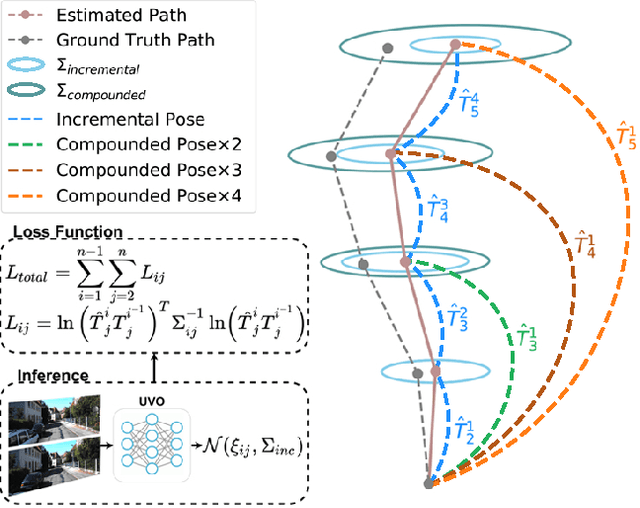
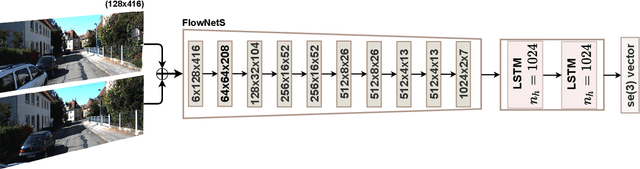
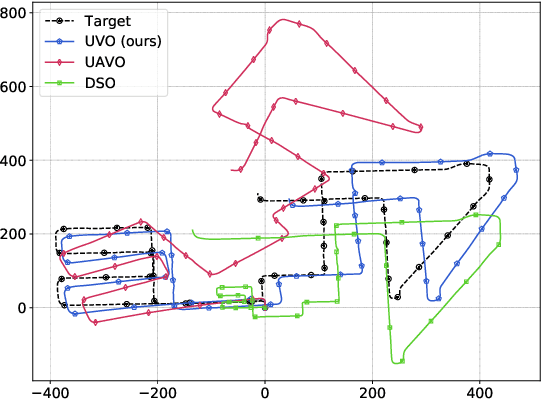
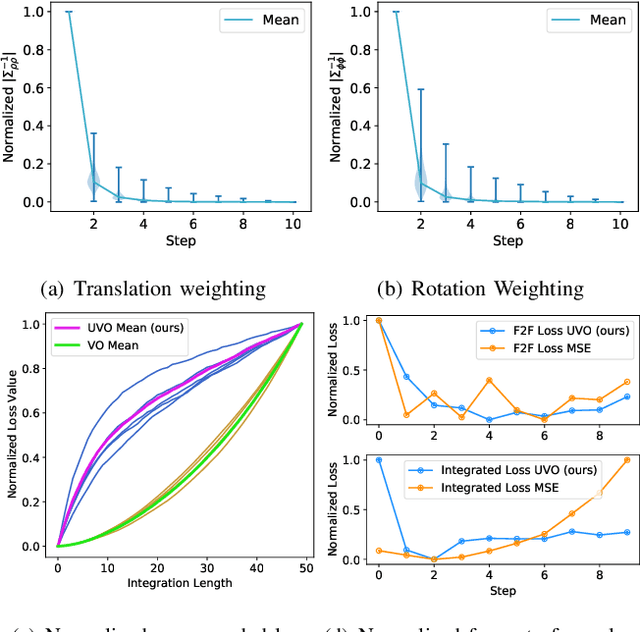
The incremental poses computed through odometry can be integrated over time to calculate the pose of a device with respect to an initial location. The resulting global pose may be used to formulate a second, consistency based, loss term in a deep odometry setting. In such cases where multiple losses are imposed on a network, the uncertainty over each output can be derived to weigh the different loss terms in a maximum likelihood setting. However, when imposing a constraint on the integrated transformation, due to how only odometry is estimated at each iteration of the algorithm, there is no information about the uncertainty associated with the global pose to weigh the global loss term. In this paper, we associate uncertainties with the output poses of a deep odometry network and propagate the uncertainties through each iteration. Our goal is to use the estimated covariance matrix at each incremental step to weigh the loss at the corresponding step while weighting the global loss term using the compounded uncertainty. This formulation provides an adaptive method to weigh the incremental and integrated loss terms against each other, noting the increase in uncertainty as new estimates arrive. We provide quantitative and qualitative analysis of pose estimates and show that our method surpasses the accuracy of the state-of-the-art Visual Odometry approaches. Then, uncertainty estimates are evaluated and comparisons against fixed baselines are provided. Finally, the uncertainty values are used in a realistic example to show the effectiveness of uncertainty quantification for localization.
Single Object Tracking through a Fast and Effective Single-Multiple Model Convolutional Neural Network
Mar 28, 2021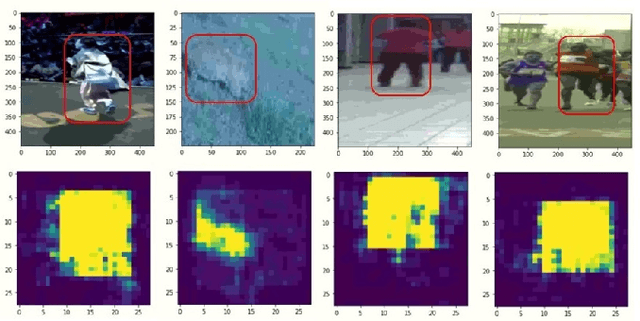
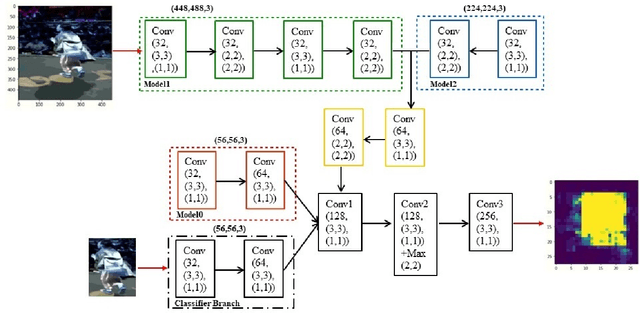


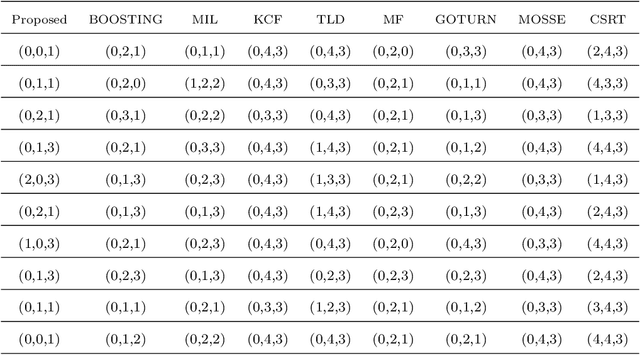
Object tracking becomes critical especially when similar objects are present in the same area. Recent state-of-the-art (SOTA) approaches are proposed based on taking a matching network with a heavy structure to distinguish the target from other objects in the area which indeed drastically downgrades the performance of the tracker in terms of speed. Besides, several candidates are considered and processed to localize the intended object in a region of interest for each frame which is time-consuming. In this article, a special architecture is proposed based on which in contrast to the previous approaches, it is possible to identify the object location in a single shot while taking its template into account to distinguish it from the similar objects in the same area. In brief, first of all, a window containing the object with twice the target size is considered. This window is then fed into a fully convolutional neural network (CNN) to extract a region of interest (RoI) in a form of a matrix for each of the frames. In the beginning, a template of the target is also taken as the input to the CNN. Considering this RoI matrix, the next movement of the tracker is determined based on a simple and fast method. Moreover, this matrix helps to estimate the object size which is crucial when it changes over time. Despite the absence of a matching network, the presented tracker performs comparatively with the SOTA in challenging situations while having a super speed compared to them (up to $120 FPS$ on 1080ti). To investigate this claim, a comparison study is carried out on the GOT-10k dataset. Results reveal the outstanding performance of the proposed method in fulfilling the task.
A Framework for 3D Tracking of Frontal Dynamic Objects in Autonomous Cars
Mar 24, 2021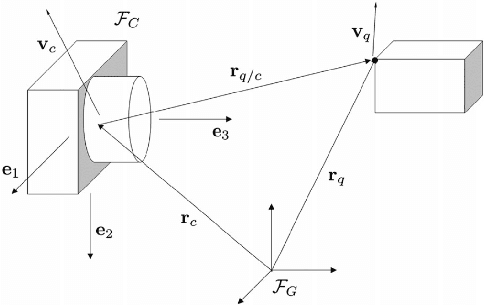

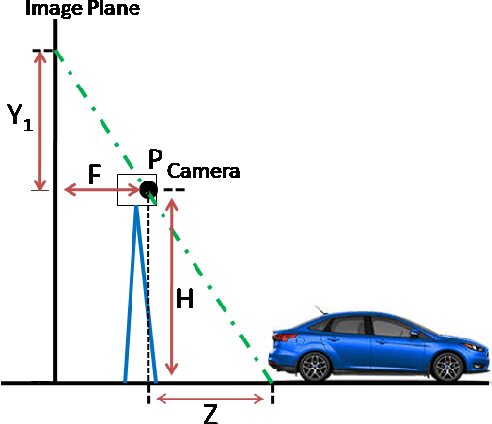
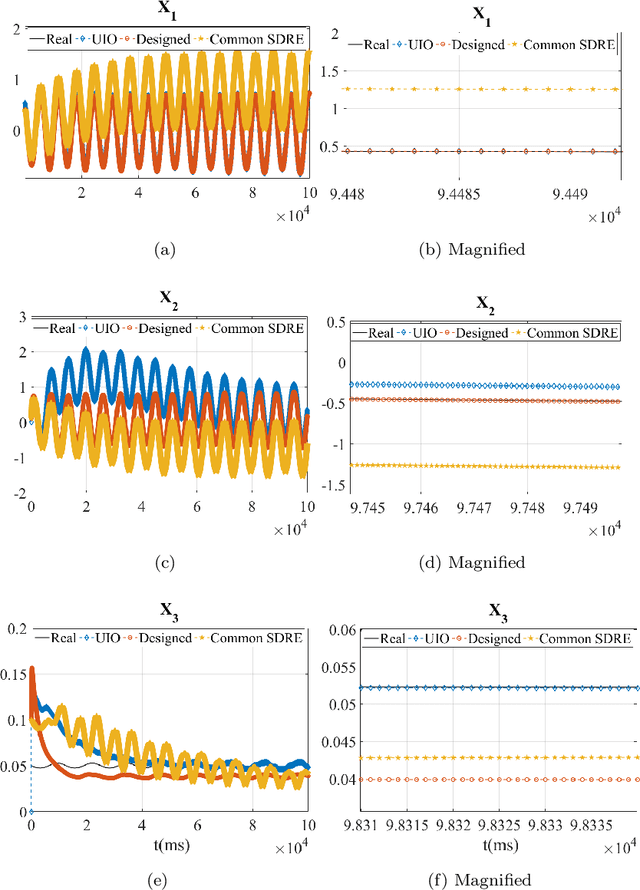
Both recognition and 3D tracking of frontal dynamic objects are crucial problems in an autonomous vehicle, while depth estimation as an essential issue becomes a challenging problem using a monocular camera. Since both camera and objects are moving, the issue can be formed as a structure from motion (SFM) problem. In this paper, to elicit features from an image, the YOLOv3 approach is utilized beside an OpenCV tracker. Subsequently, to obtain the lateral and longitudinal distances, a nonlinear SFM model is considered alongside a state-dependent Riccati equation (SDRE) filter and a newly developed observation model. Additionally, a switching method in the form of switching estimation error covariance is proposed to enhance the robust performance of the SDRE filter. The stability analysis of the presented filter is conducted on a class of discrete nonlinear systems. Furthermore, the ultimate bound of estimation error caused by model uncertainties is analytically obtained to investigate the switching significance. Simulations are reported to validate the performance of the switched SDRE filter. Finally, real-time experiments are performed through a multi-thread framework implemented on a Jetson TX2 board, while radar data is used for the evaluation.
Object Localization Through a Single Multiple-Model Convolutional Neural Network with a Specific Training Approach
Mar 24, 2021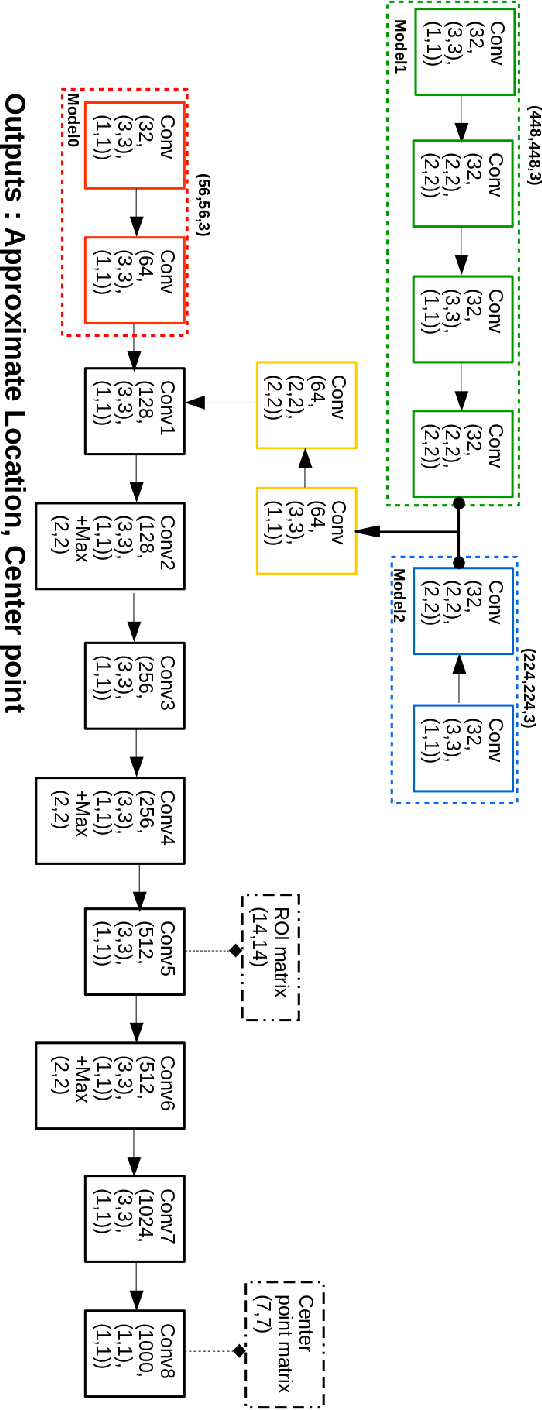


Object localization has a vital role in any object detector, and therefore, has been the focus of attention by many researchers. In this article, a special training approach is proposed for a light convolutional neural network (CNN) to determine the region of interest (ROI) in an image while effectively reducing the number of probable anchor boxes. Almost all CNN-based detectors utilize a fixed input size image, which may yield poor performance when dealing with various object sizes. In this paper, a different CNN structure is proposed taking three different input sizes, to enhance the performance. In order to demonstrate the effectiveness of the proposed method, two common data set are used for training while tracking by localization application is considered to demonstrate its final performance. The promising results indicate the applicability of the presented structure and the training method in practice.