 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Localization Through a Single Multiple-Model Convolutional Neural Network with a Specific Training Approach
Paper and Code
Mar 24, 2021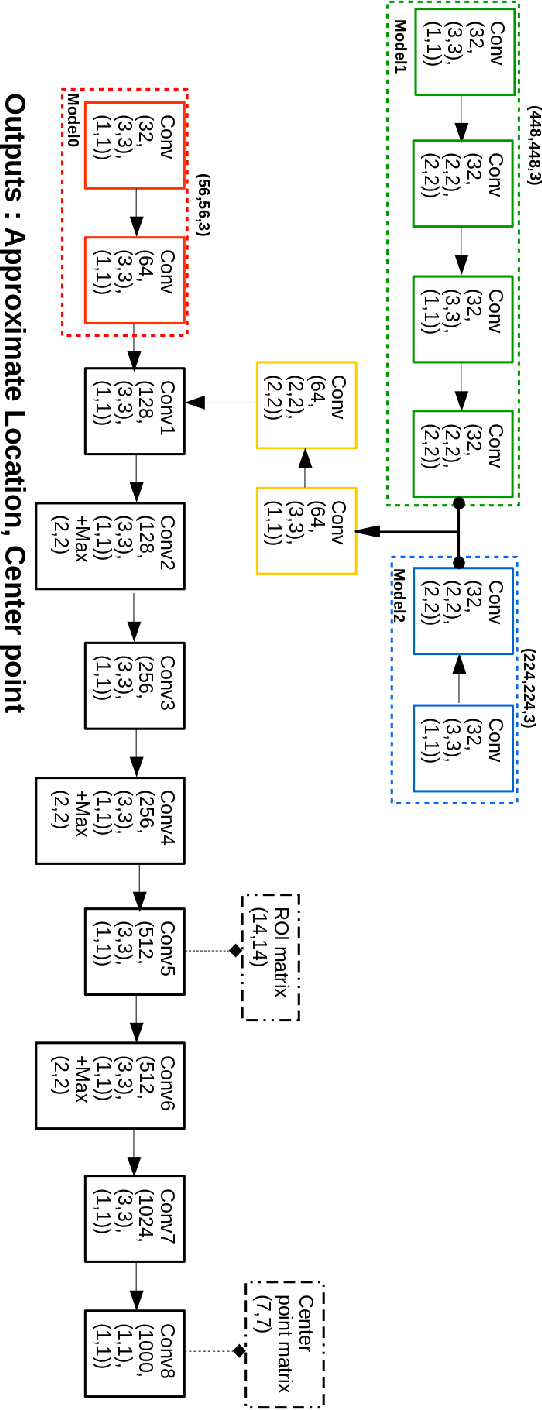


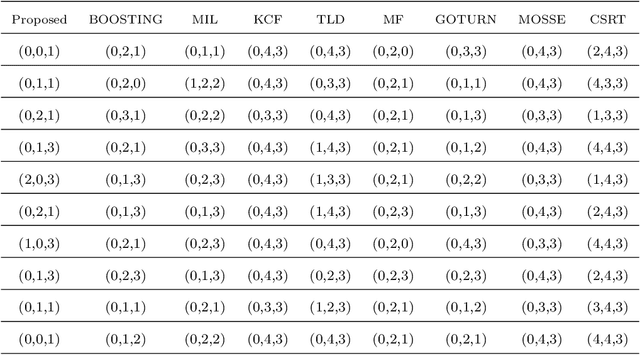
Object localization has a vital role in any object detector, and therefore, has been the focus of attention by many researchers. In this article, a special training approach is proposed for a light convolutional neural network (CNN) to determine the region of interest (ROI) in an image while effectively reducing the number of probable anchor boxes. Almost all CNN-based detectors utilize a fixed input size image, which may yield poor performance when dealing with various object sizes. In this paper, a different CNN structure is proposed taking three different input sizes, to enhance the performance. In order to demonstrate the effectiveness of the proposed method, two common data set are used for training while tracking by localization application is considered to demonstrate its final performance. The promising results indicate the applicability of the presented structure and the training method in practice.