 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological mapping for traversability-aware long-range navigation in off-road terrain
Oct 02, 2024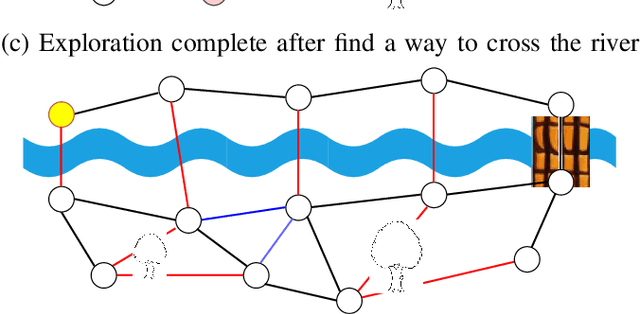

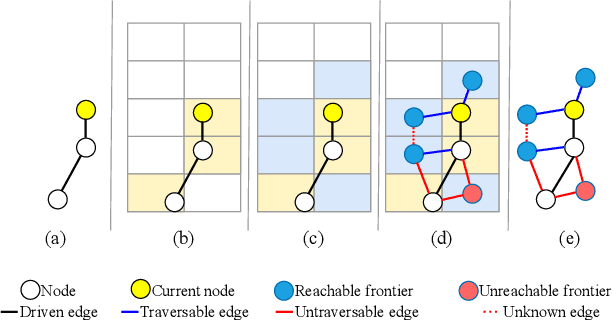
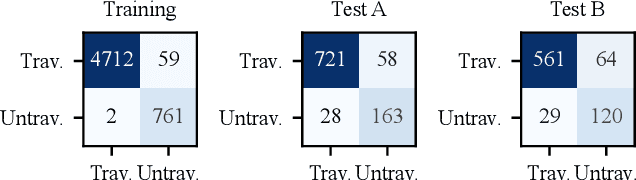
Autonomous robots navigating in off-road terrain like forests open new opportunities for automation. While off-road navigation has been studied, existing work often relies on clearly delineated pathways. We present a method allowing for long-range planning, exploration and low-level control in unknown off-trail forest terrain, using vision and GPS only. We represent outdoor terrain with a topological map, which is a set of panoramic snapshots connected with edges containing traversability information. A novel traversability analysis method is demonstrated, predicting the existence of a safe path towards a target in an image. Navigating between nodes is done using goal-conditioned behavior cloning, leveraging the power of a pretrained vision transformer. An exploration planner is presented, efficiently covering an unknown off-road area with unknown traversability using a frontiers-based approach. The approach is successfully deployed to autonomously explore two 400 meters squared forest sites unseen during training, in difficult conditions for navigation.
Constrained Robotic Navigation on Preferred Terrains Using LLMs and Speech Instruction: Exploiting the Power of Adverbs
Apr 02, 2024This paper explores leveraging large language models for map-free off-road navigation using generative AI, reducing the need for traditional data collection and annotation. We propose a method where a robot receives verbal instructions, converted to text through Whisper, and a large language model (LLM) model extracts landmarks, preferred terrains, and crucial adverbs translated into speed settings for constrained navigation. A language-driven semantic segmentation model generates text-based masks for identifying landmarks and terrain types in images. By translating 2D image points to the vehicle's motion plane using camera parameters, an MPC controller can guides the vehicle towards the desired terrain. This approach enhances adaptation to diverse environments and facilitates the use of high-level instructions for navigating complex and challenging terrains.
A comparison of RL-based and PID controllers for 6-DOF swimming robots: hybrid underwater object tracking
Jan 29, 2024In this paper, we present an exploration and assessment of employing a centralized deep Q-network (DQN) controller as a substitute for the prevalent use of PID controllers in the context of 6DOF swimming robots. Our primary focus centers on illustrating this transition with the specific case of underwater object tracking. DQN offers advantages such as data efficiency and off-policy learning, while remaining simpler to implement than other reinforcement learning methods. Given the absence of a dynamic model for our robot, we propose an RL agent to control this multi-input-multi-output (MIMO) system, where a centralized controller may offer more robust control than distinct PIDs. Our approach involves initially using classical controllers for safe exploration, then gradually shifting to DQN to take full control of the robot. We divide the underwater tracking task into vision and control modules. We use established methods for vision-based tracking and introduce a centralized DQN controller. By transmitting bounding box data from the vision module to the control module, we enable adaptation to various objects and effortless vision system replacement. Furthermore, dealing with low-dimensional data facilitates cost-effective online learning for the controller. Our experiments, conducted within a Unity-based simulator, validate the effectiveness of a centralized RL agent over separated PID controllers, showcasing the applicability of our framework for training the underwater RL agent and improved performance compared to traditional control methods. The code for both real and simulation implementations is at https://github.com/FARAZLOTFI/underwater-object-tracking.
Uncertainty-aware hybrid paradigm of nonlinear MPC and model-based RL for offroad navigation: Exploration of transformers in the predictive model
Oct 01, 2023



In this paper, we investigate a hybrid scheme that combines nonlinear model predictive control (MPC) and model-based reinforcement learning (RL) for navigation planning of an autonomous model car across offroad, unstructured terrains without relying on predefined maps. Our innovative approach takes inspiration from BADGR, an LSTM-based network that primarily concentrates on environment modeling, but distinguishes itself by substituting LSTM modules with transformers to greatly elevate the performance our model. Addressing uncertainty within the system, we train an ensemble of predictive models and estimate the mutual information between model weights and outputs, facilitating dynamic horizon planning through the introduction of variable speeds. Further enhancing our methodology, we incorporate a nonlinear MPC controller that accounts for the intricacies of the vehicle's model and states. The model-based RL facet produces steering angles and quantifies inherent uncertainty. At the same time, the nonlinear MPC suggests optimal throttle settings, striking a balance between goal attainment speed and managing model uncertainty influenced by velocity. In the conducted studies, our approach excels over the existing baseline by consistently achieving higher metric values in predicting future events and seamlessly integrating the vehicle's kinematic model for enhanced decision-making. The code and the evaluation data are available at https://github.com/FARAZLOTFI/offroad_autonomous_navigation/).
Drowsiness Detection Based On Driver Temporal Behavior Using a New Developed Dataset
Mar 31, 2021

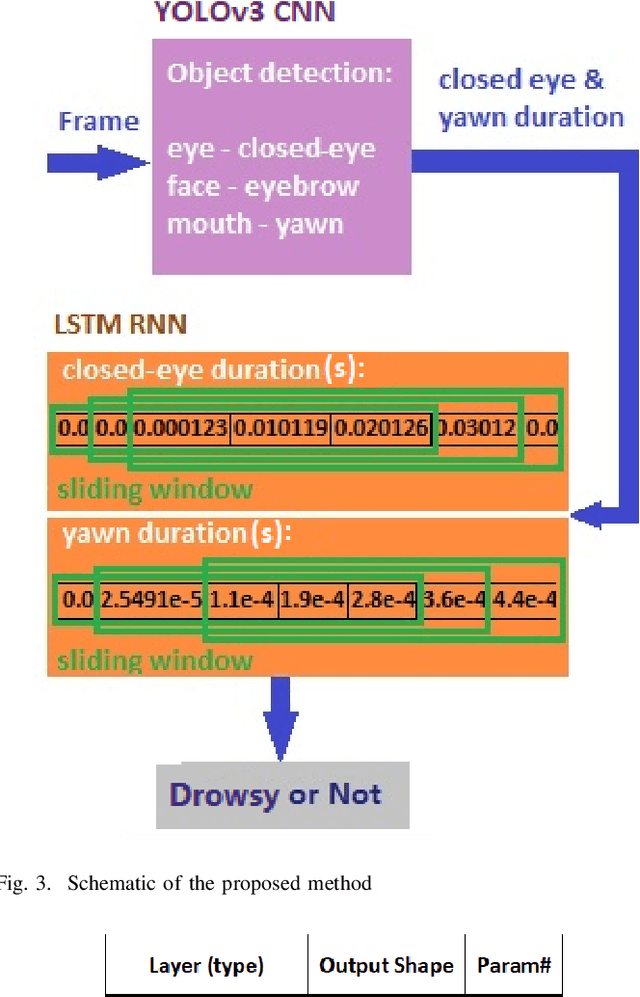
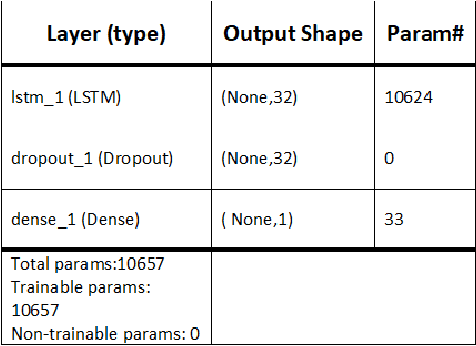
Driver drowsiness detection has been the subject of many researches in the past few decades and various methods have been developed to detect it. In this study, as an image-based approach with adequate accuracy, along with the expedite process, we applied YOLOv3 (You Look Only Once-version3) CNN (Convolutional Neural Network) for extracting facial features automatically. Then, LSTM (Long-Short Term Memory) neural network is employed to learn driver temporal behaviors including yawning and blinking time period as well as sequence classification. To train YOLOv3, we utilized our collected dataset alongside the transfer learning method. Moreover, the dataset for the LSTM training process is produced by the mentioned CNN and is formatted as a two-dimensional sequence comprised of eye blinking and yawning time durations. The developed dataset considers both disturbances such as illumination and drivers' head posture. To have real-time experiments a multi-thread framework is developed to run both CNN and LSTM in parallel. Finally, results indicate the hybrid of CNN and LSTM ability in drowsiness detection and the effectiveness of the proposed method.
Single Object Tracking through a Fast and Effective Single-Multiple Model Convolutional Neural Network
Mar 28, 2021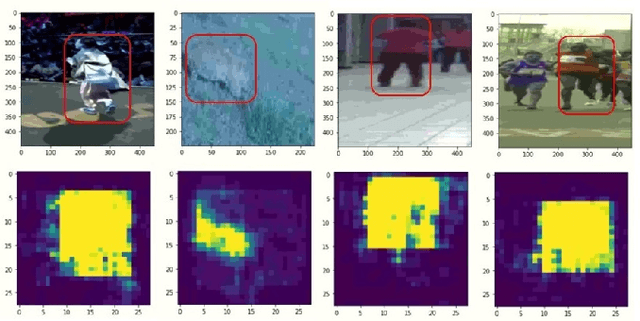
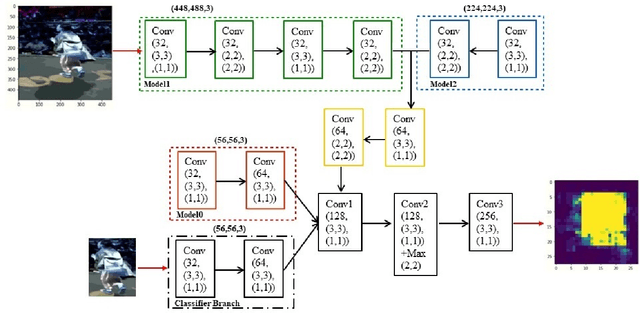


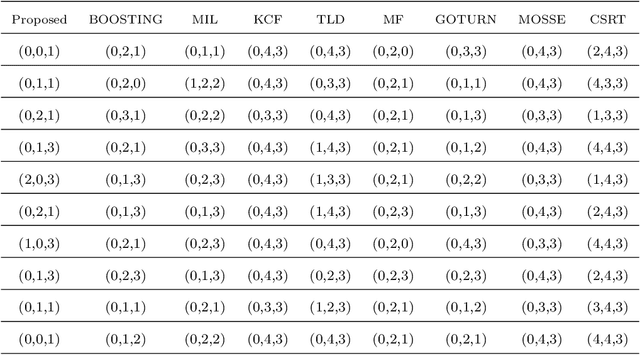
Object tracking becomes critical especially when similar objects are present in the same area. Recent state-of-the-art (SOTA) approaches are proposed based on taking a matching network with a heavy structure to distinguish the target from other objects in the area which indeed drastically downgrades the performance of the tracker in terms of speed. Besides, several candidates are considered and processed to localize the intended object in a region of interest for each frame which is time-consuming. In this article, a special architecture is proposed based on which in contrast to the previous approaches, it is possible to identify the object location in a single shot while taking its template into account to distinguish it from the similar objects in the same area. In brief, first of all, a window containing the object with twice the target size is considered. This window is then fed into a fully convolutional neural network (CNN) to extract a region of interest (RoI) in a form of a matrix for each of the frames. In the beginning, a template of the target is also taken as the input to the CNN. Considering this RoI matrix, the next movement of the tracker is determined based on a simple and fast method. Moreover, this matrix helps to estimate the object size which is crucial when it changes over time. Despite the absence of a matching network, the presented tracker performs comparatively with the SOTA in challenging situations while having a super speed compared to them (up to $120 FPS$ on 1080ti). To investigate this claim, a comparison study is carried out on the GOT-10k dataset. Results reveal the outstanding performance of the proposed method in fulfilling the task.
A Framework for 3D Tracking of Frontal Dynamic Objects in Autonomous Cars
Mar 24, 2021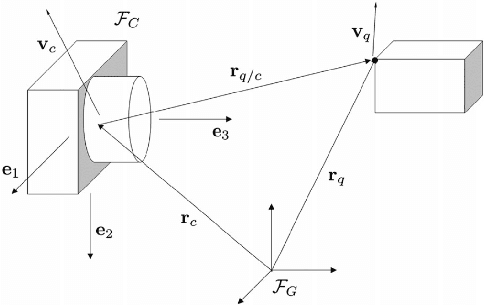

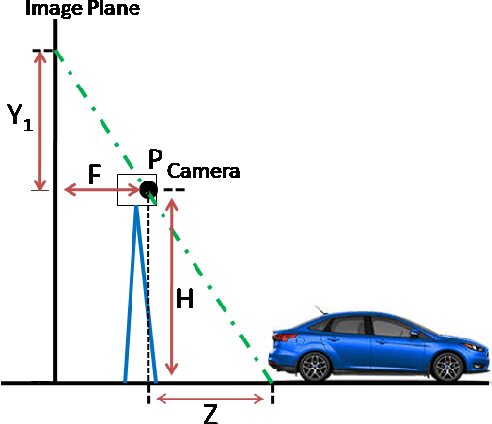
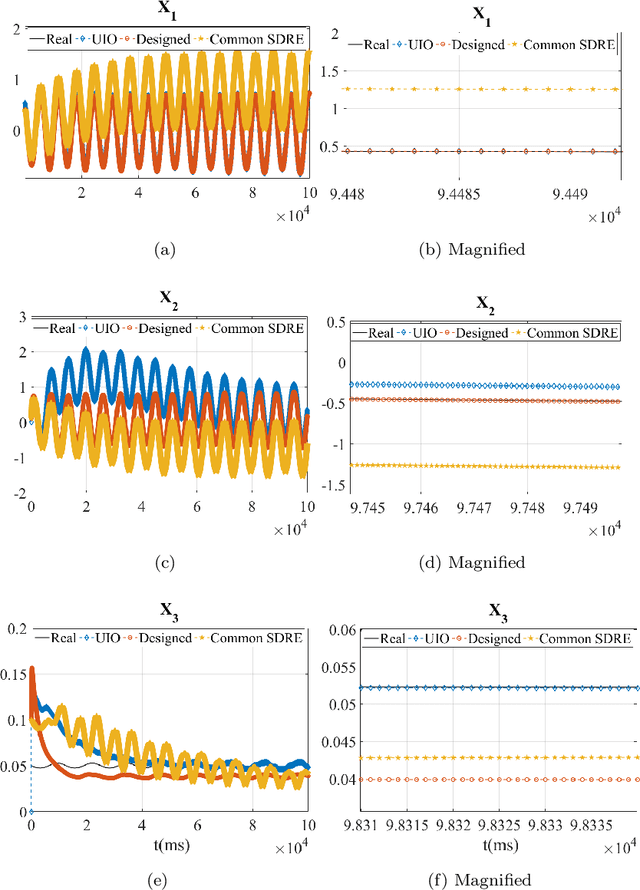
Both recognition and 3D tracking of frontal dynamic objects are crucial problems in an autonomous vehicle, while depth estimation as an essential issue becomes a challenging problem using a monocular camera. Since both camera and objects are moving, the issue can be formed as a structure from motion (SFM) problem. In this paper, to elicit features from an image, the YOLOv3 approach is utilized beside an OpenCV tracker. Subsequently, to obtain the lateral and longitudinal distances, a nonlinear SFM model is considered alongside a state-dependent Riccati equation (SDRE) filter and a newly developed observation model. Additionally, a switching method in the form of switching estimation error covariance is proposed to enhance the robust performance of the SDRE filter. The stability analysis of the presented filter is conducted on a class of discrete nonlinear systems. Furthermore, the ultimate bound of estimation error caused by model uncertainties is analytically obtained to investigate the switching significance. Simulations are reported to validate the performance of the switched SDRE filter. Finally, real-time experiments are performed through a multi-thread framework implemented on a Jetson TX2 board, while radar data is used for the evaluation.
Object Localization Through a Single Multiple-Model Convolutional Neural Network with a Specific Training Approach
Mar 24, 2021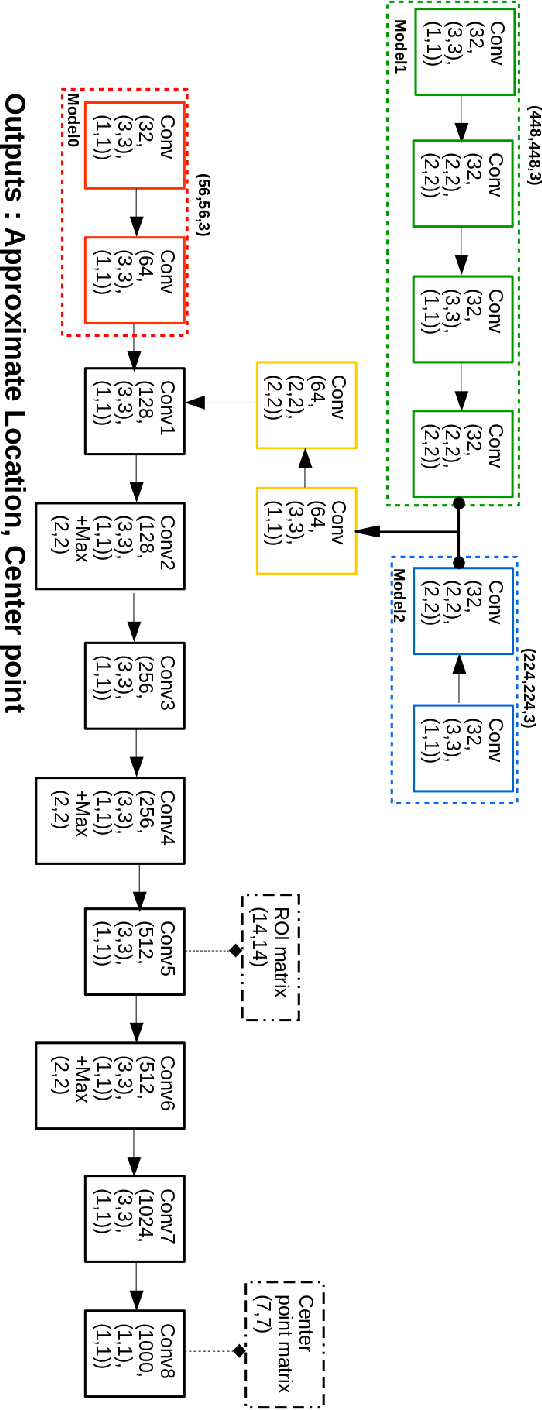


Object localization has a vital role in any object detector, and therefore, has been the focus of attention by many researchers. In this article, a special training approach is proposed for a light convolutional neural network (CNN) to determine the region of interest (ROI) in an image while effectively reducing the number of probable anchor boxes. Almost all CNN-based detectors utilize a fixed input size image, which may yield poor performance when dealing with various object sizes. In this paper, a different CNN structure is proposed taking three different input sizes, to enhance the performance. In order to demonstrate the effectiveness of the proposed method, two common data set are used for training while tracking by localization application is considered to demonstrate its final performance. The promising results indicate the applicability of the presented structure and the training method in practice.