 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurkishBERTweet: Fast and Reliable Large Language Model for Social Media Analysis
Nov 29, 2023



Turkish is one of the most popular languages in the world. Wide us of this language on social media platforms such as Twitter, Instagram, or Tiktok and strategic position of the country in the world politics makes it appealing for the social network researchers and industry. To address this need, we introduce TurkishBERTweet, the first large scale pre-trained language model for Turkish social media built using almost 900 million tweets. The model shares the same architecture as base BERT model with smaller input length, making TurkishBERTweet lighter than BERTurk and can have significantly lower inference time. We trained our model using the same approach for RoBERTa model and evaluated on two text classification tasks: Sentiment Classification and Hate Speech Detection. We demonstrate that TurkishBERTweet outperforms the other available alternatives on generalizability and its lower inference time gives significant advantage to process large-scale datasets. We also compared our models with the commercial OpenAI solutions in terms of cost and performance to demonstrate TurkishBERTweet is scalable and cost-effective solution. As part of our research, we released TurkishBERTweet and fine-tuned LoRA adapters for the mentioned tasks under the MIT License to facilitate future research and applications on Turkish social media. Our TurkishBERTweet model is available at: https://github.com/ViralLab/TurkishBERTweet
#Secim2023: First Public Dataset for Studying Turkish General Election
Nov 22, 2022
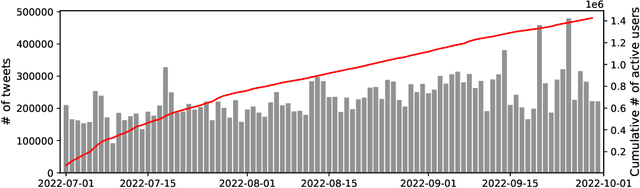
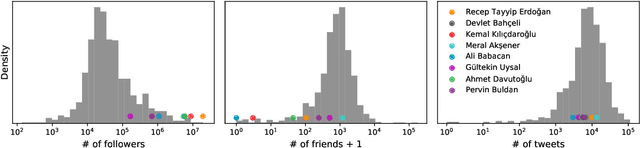
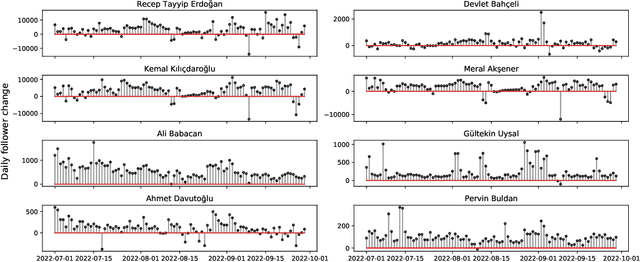
In the context of Turkey's upcoming parliamentary and presidential elections ("se\c{c}im" in Turkish), social media is playing an important role in shaping public debate. The increasing engagement of citizens on social media platforms has led to the growing use of social media by political actors. It is of utmost importance to capture the upcoming Turkish elections, as social media is becoming an essential component of election propaganda, political debates, smear campaigns, and election manipulation by domestic and international actors. We provide a comprehensive dataset for social media researchers to study the upcoming election, develop tools to prevent online manipulation, and gather novel information to inform the public. We are committed to continually improving the data collection and updating it regularly leading up to the election. Using the Secim2023 dataset, researchers can examine the social and communication networks between political actors, track current trends, and investigate emerging threats to election integrity. Our dataset is available at: https://github.com/ViralLab/Secim2023_Dataset
Drowsiness Detection Based On Driver Temporal Behavior Using a New Developed Dataset
Mar 31, 2021

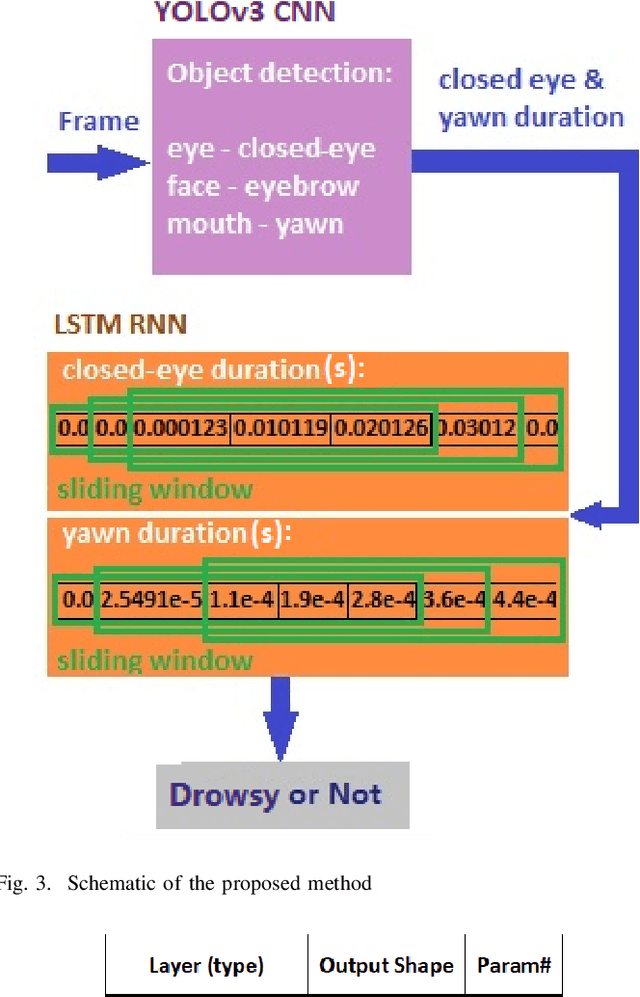
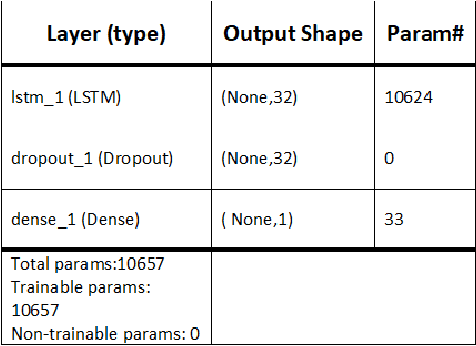
Driver drowsiness detection has been the subject of many researches in the past few decades and various methods have been developed to detect it. In this study, as an image-based approach with adequate accuracy, along with the expedite process, we applied YOLOv3 (You Look Only Once-version3) CNN (Convolutional Neural Network) for extracting facial features automatically. Then, LSTM (Long-Short Term Memory) neural network is employed to learn driver temporal behaviors including yawning and blinking time period as well as sequence classification. To train YOLOv3, we utilized our collected dataset alongside the transfer learning method. Moreover, the dataset for the LSTM training process is produced by the mentioned CNN and is formatted as a two-dimensional sequence comprised of eye blinking and yawning time durations. The developed dataset considers both disturbances such as illumination and drivers' head posture. To have real-time experiments a multi-thread framework is developed to run both CNN and LSTM in parallel. Finally, results indicate the hybrid of CNN and LSTM ability in drowsiness detection and the effectiveness of the proposed method.
ComStreamClust: A communicative text clustering approach to topic detection in streaming data
Oct 11, 2020

Topic detection is the task of determining and tracking hot topics in social media. Twitter is arguably the most popular platform for people to share their ideas with others about different issues. One such prevalent issue is the COVID-19 pandemic. Detecting and tracking topics on these kinds of issues would help governments and healthcare companies deal with this phenomenon. In this paper, we propose a novel communicative clustering approach, so-called ComStreamClust for clustering sub-topics inside a broader topic, e.g. COVID-19. The proposed approach was evaluated on two datasets: the COVID-19 and the FA CUP. The results obtained from ComStreamClust approve the effectiveness of the proposed approach when compared to existing methods such as LDA.