 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurkishBERTweet: Fast and Reliable Large Language Model for Social Media Analysis
Nov 29, 2023



Turkish is one of the most popular languages in the world. Wide us of this language on social media platforms such as Twitter, Instagram, or Tiktok and strategic position of the country in the world politics makes it appealing for the social network researchers and industry. To address this need, we introduce TurkishBERTweet, the first large scale pre-trained language model for Turkish social media built using almost 900 million tweets. The model shares the same architecture as base BERT model with smaller input length, making TurkishBERTweet lighter than BERTurk and can have significantly lower inference time. We trained our model using the same approach for RoBERTa model and evaluated on two text classification tasks: Sentiment Classification and Hate Speech Detection. We demonstrate that TurkishBERTweet outperforms the other available alternatives on generalizability and its lower inference time gives significant advantage to process large-scale datasets. We also compared our models with the commercial OpenAI solutions in terms of cost and performance to demonstrate TurkishBERTweet is scalable and cost-effective solution. As part of our research, we released TurkishBERTweet and fine-tuned LoRA adapters for the mentioned tasks under the MIT License to facilitate future research and applications on Turkish social media. Our TurkishBERTweet model is available at: https://github.com/ViralLab/TurkishBERTweet
Hidden Citations Obscure True Impact in Science
Oct 24, 2023References, the mechanism scientists rely on to signal previous knowledge, lately have turned into widely used and misused measures of scientific impact. Yet, when a discovery becomes common knowledge, citations suffer from obliteration by incorporation. This leads to the concept of hidden citation, representing a clear textual credit to a discovery without a reference to the publication embodying it. Here, we rely on unsupervised interpretable machine learning applied to the full text of each paper to systematically identify hidden citations. We find that for influential discoveries hidden citations outnumber citation counts, emerging regardless of publishing venue and discipline. We show that the prevalence of hidden citations is not driven by citation counts, but rather by the degree of the discourse on the topic within the text of the manuscripts, indicating that the more discussed is a discovery, the less visible it is to standard bibliometric analysis. Hidden citations indicate that bibliometric measures offer a limited perspective on quantifying the true impact of a discovery, raising the need to extract knowledge from the full text of the scientific corpus.
#Secim2023: First Public Dataset for Studying Turkish General Election
Nov 22, 2022
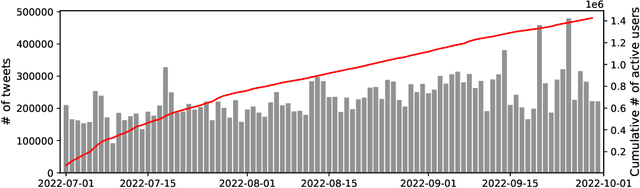
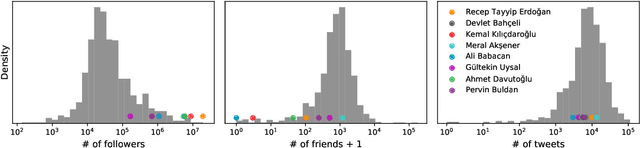
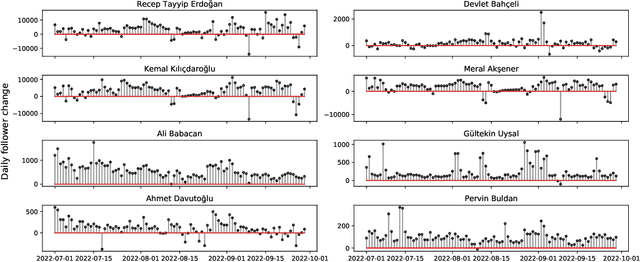
In the context of Turkey's upcoming parliamentary and presidential elections ("se\c{c}im" in Turkish), social media is playing an important role in shaping public debate. The increasing engagement of citizens on social media platforms has led to the growing use of social media by political actors. It is of utmost importance to capture the upcoming Turkish elections, as social media is becoming an essential component of election propaganda, political debates, smear campaigns, and election manipulation by domestic and international actors. We provide a comprehensive dataset for social media researchers to study the upcoming election, develop tools to prevent online manipulation, and gather novel information to inform the public. We are committed to continually improving the data collection and updating it regularly leading up to the election. Using the Secim2023 dataset, researchers can examine the social and communication networks between political actors, track current trends, and investigate emerging threats to election integrity. Our dataset is available at: https://github.com/ViralLab/Secim2023_Dataset
Academic Support Network Reflects Doctoral Experience and Productivity
Mar 07, 2022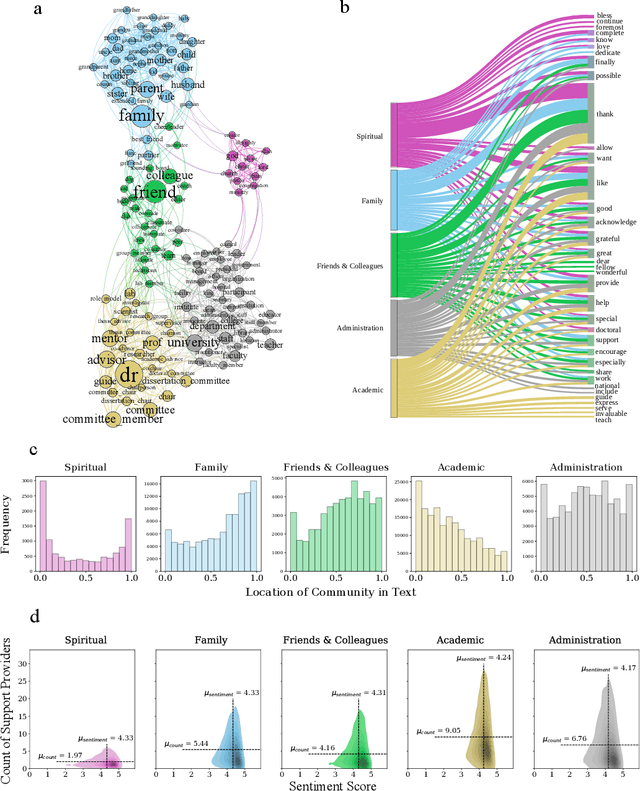
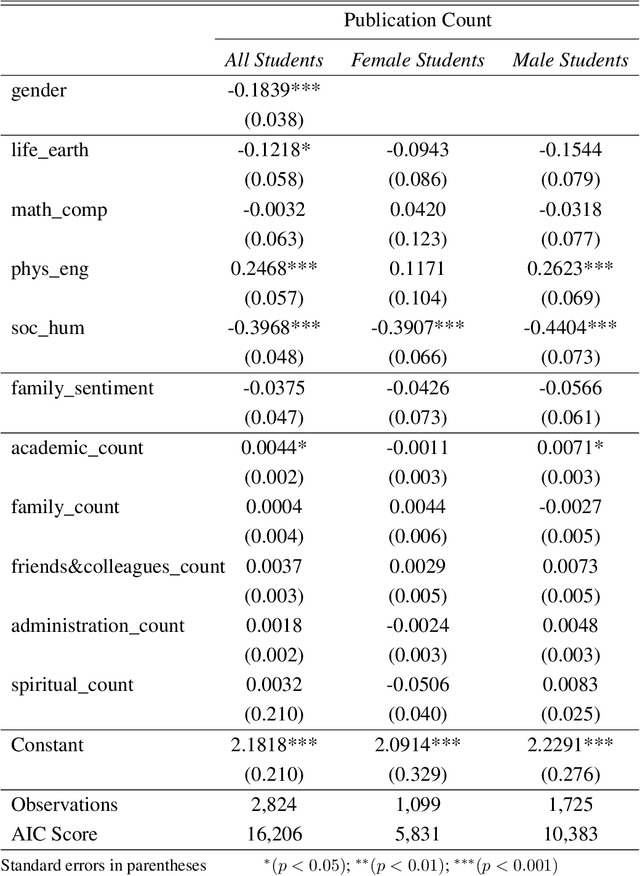
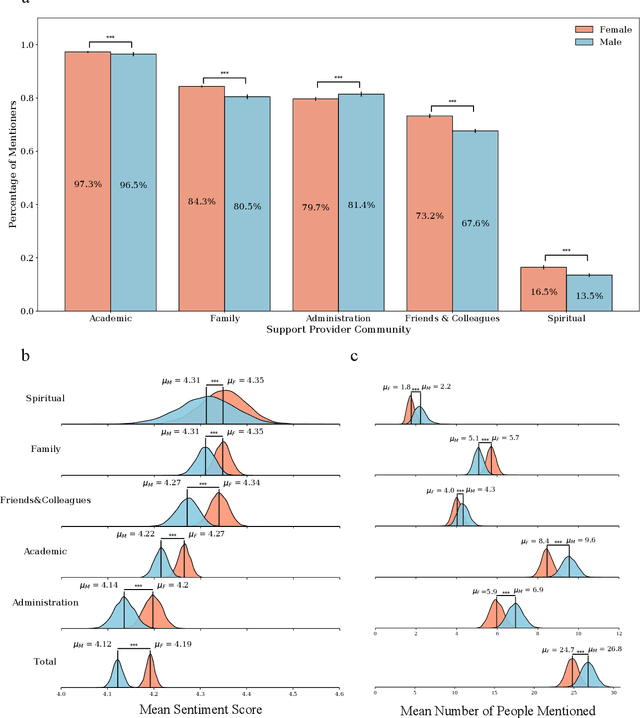
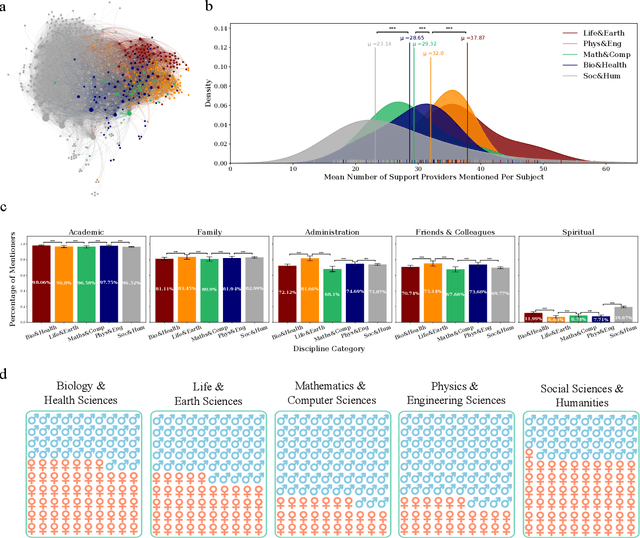
Current practices of quantifying performance by productivity leads serious concerns for psychological well-being of doctoral students and influence of research environment is often neglected in research evaluations. Acknowledgements in dissertations reflect the student experience and provide an opportunity to thank the people who support them. We conduct textual analysis of acknowledgments to build the "academic support network," uncovering five distinct communities: Academic, Administration, Family, Friends & Colleagues, and Spiritual; each of which is acknowledged differently by genders and disciplines. Female students mention fewer people from each community except for their families and total number of people mentioned in acknowledgements allows disciplines to be categorized as either individual science or team science. We also show that number of people mentioned from academic community is positively correlated with productivity and institutional rankings are found to be correlated with productivity and size of academic support networks but show no effect on students' sentiment on acknowledgements. Our results indicate the importance of academic support networks by explaining how they differ and how they influence productivity.
Detection of Novel Social Bots by Ensembles of Specialized Classifiers
Jun 11, 2020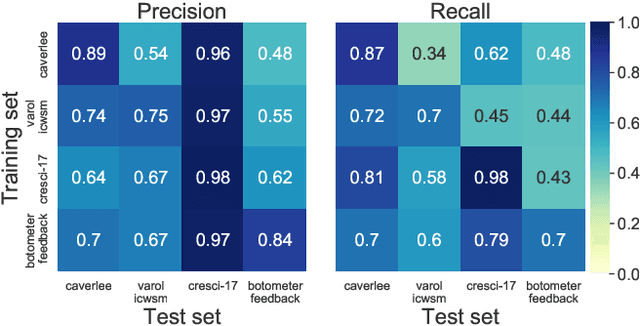
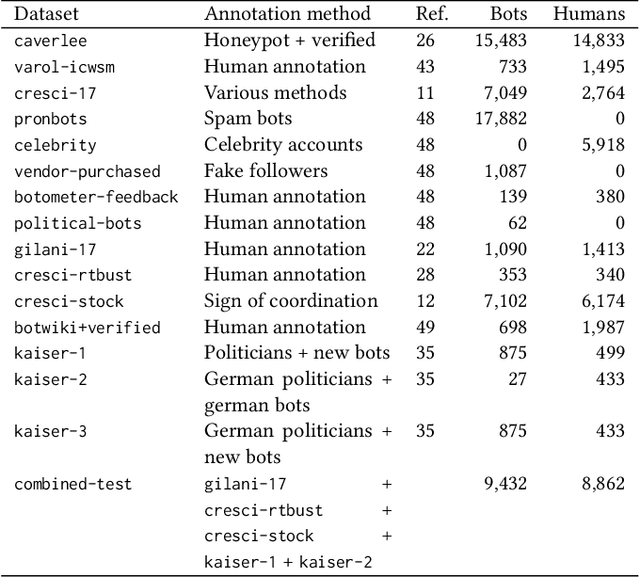

Malicious actors create inauthentic social media accounts controlled in part by algorithms, known as social bots, to disseminate misinformation and agitate online discussion. While researchers have developed sophisticated methods to detect abuse, novel bots with diverse behaviors evade detection. We show that different types of bots are characterized by different behavioral features. As a result, commonly used supervised learning techniques suffer severe performance deterioration when attempting to detect behaviors not observed in the training data. Moreover, tuning these models to recognize novel bots requires retraining with a significant amount of new annotations, which are expensive to obtain. To address these issues, we propose a new supervised learning method that trains classifiers specialized for each class of bots and combines their decisions through the maximum rule. The ensemble of specialized classifiers (ESC) can better generalize, leading to an average improvement of 56% in F1 score for unseen accounts across datasets. Furthermore, novel bot behaviors are learned with fewer labeled examples during retraining. We are deploying ESC in the newest version of Botometer, a popular tool to detect social bots in the wild.
Network Medicine Framework for Identifying Drug Repurposing Opportunities for COVID-19
Apr 15, 2020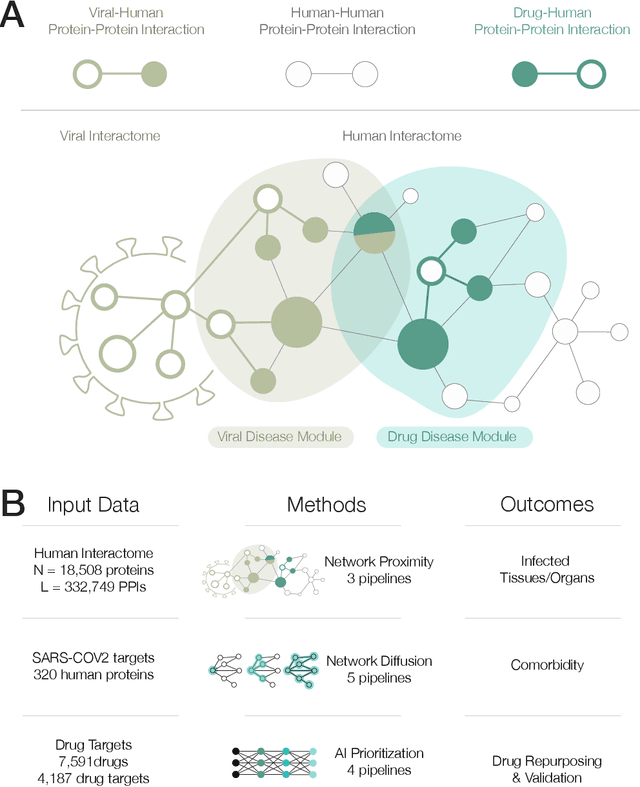
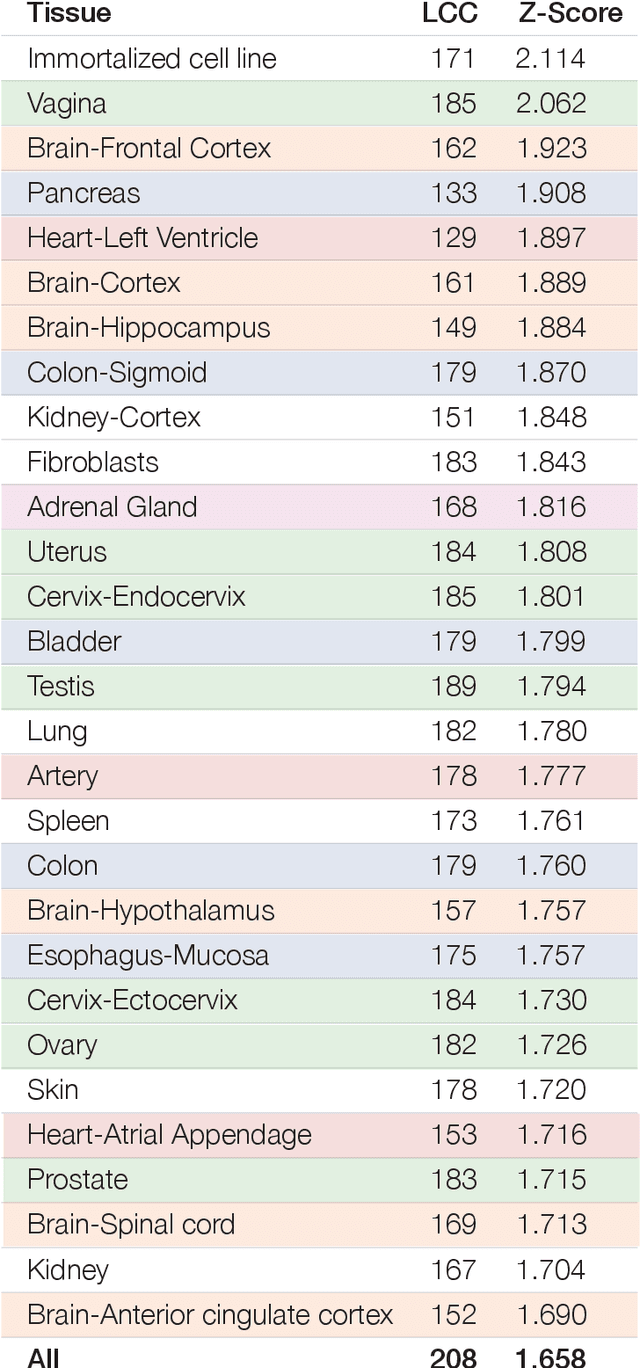
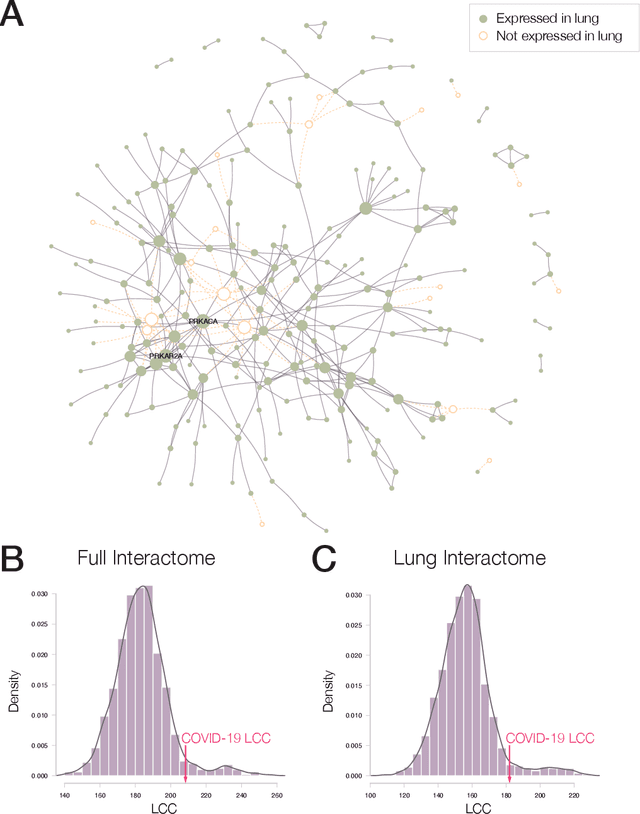
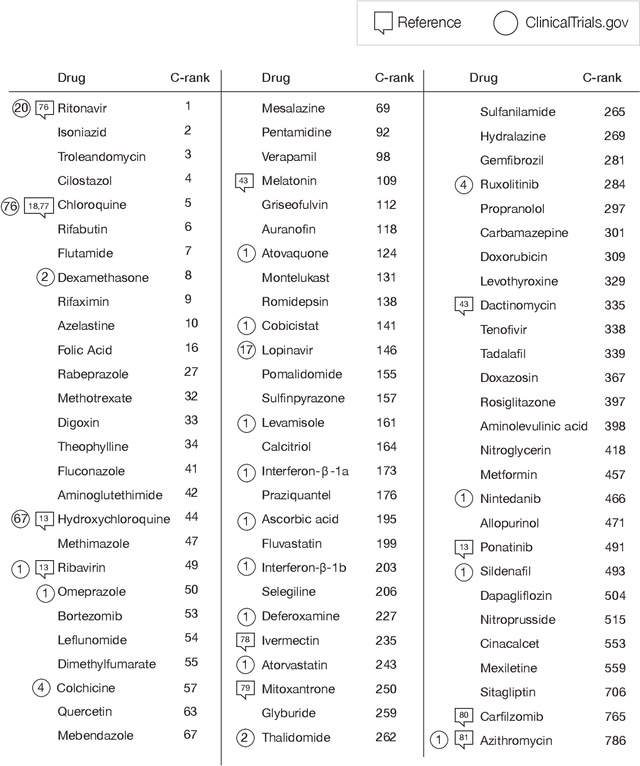
The COVID-19 pandemic demands the rapid identification of drug-repurpusing candidates. In the past decade, network medicine had developed a framework consisting of a series of quantitative approaches and predictive tools to study host-pathogen interactions, unveil the molecular mechanisms of the infection, identify comorbidities as well as rapidly detect drug repurpusing candidates. Here, we adapt the network-based toolset to COVID-19, recovering the primary pulmonary manifestations of the virus in the lung as well as observed comorbidities associated with cardiovascular diseases. We predict that the virus can manifest itself in other tissues, such as the reproductive system, and brain regions, moreover we predict neurological comorbidities. We build on these findings to deploy three network-based drug repurposing strategies, relying on network proximity, diffusion, and AI-based metrics, allowing to rank all approved drugs based on their likely efficacy for COVID-19 patients, aggregate all predictions, and, thereby to arrive at 81 promising repurposing candidates. We validate the accuracy of our predictions using drugs currently in clinical trials, and an expression-based validation of selected candidates suggests that these drugs, with known toxicities and side effects, could be moved to clinical trials rapidly.
Scalable and Generalizable Social Bot Detection through Data Selection
Nov 20, 2019
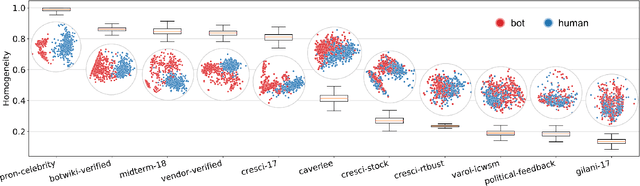
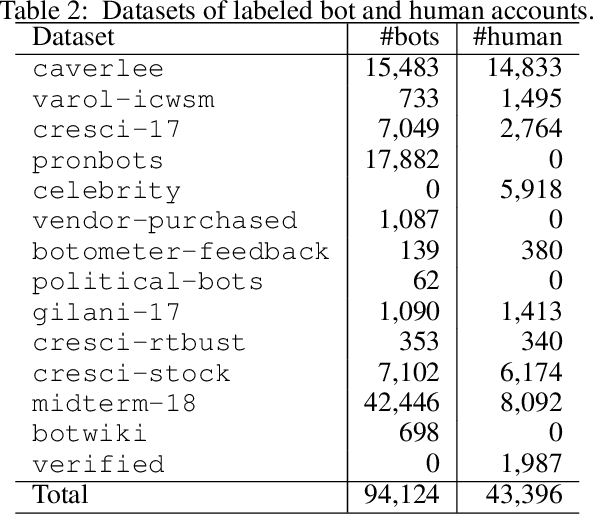
Efficient and reliable social bot classification is crucial for detecting information manipulation on social media. Despite rapid development, state-of-the-art bot detection models still face generalization and scalability challenges, which greatly limit their applications. In this paper we propose a framework that uses minimal account metadata, enabling efficient analysis that scales up to handle the full stream of public tweets of Twitter in real time. To ensure model accuracy, we build a rich collection of labeled datasets for training and validation. We deploy a strict validation system so that model performance on unseen datasets is also optimized, in addition to traditional cross-validation. We find that strategically selecting a subset of training data yields better model accuracy and generalization than exhaustively training on all available data. Thanks to the simplicity of the proposed model, its logic can be interpreted to provide insights into social bot characteristics.
L2P: An Algorithm for Estimating Heavy-tailed Outcomes
Aug 13, 2019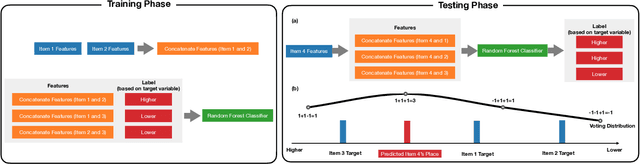
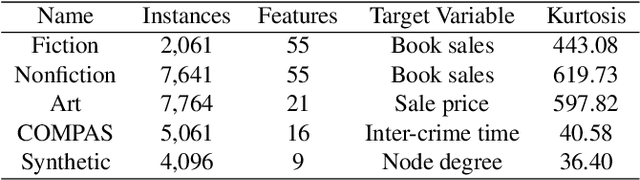
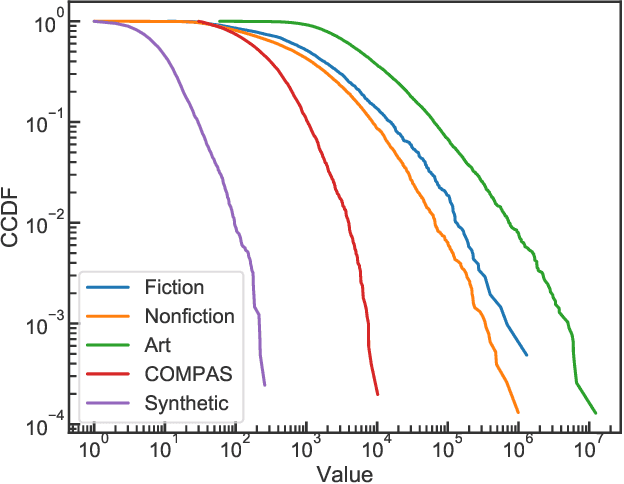
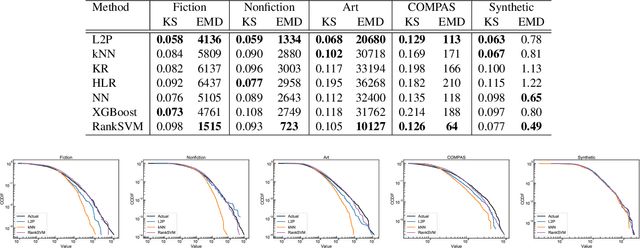
Many real-world prediction tasks have outcome (a.k.a.~target or response) variables that have characteristic heavy-tail distributions. Examples include copies of books sold, auction prices of art pieces, etc. By learning heavy-tailed distributions, ``big and rare'' instances (e.g., the best-sellers) will have accurate predictions. Most existing approaches are not dedicated to learning heavy-tailed distribution; thus, they heavily under-predict such instances. To tackle this problem, we introduce \emph{Learning to Place} (\texttt{L2P}), which exploits the pairwise relationships between instances to learn from a proportionally higher number of rare instances. \texttt{L2P} consists of two stages. In Stage 1, \texttt{L2P} learns a pairwise preference classifier: \textit{is instance A $>$ instance B?}. In Stage 2, \texttt{L2P} learns to place a new instance into an ordinal ranking of known instances. Based on its placement, the new instance is then assigned a value for its outcome variable. Experiments on real data show that \texttt{L2P} outperforms competing approaches in terms of accuracy and capability to reproduce heavy-tailed outcome distribution. In addition, \texttt{L2P} can provide an interpretable model with explainable outcomes by placing each predicted instance in context with its comparable neighbors.
Predicting online extremism, content adopters, and interaction reciprocity
May 02, 2016
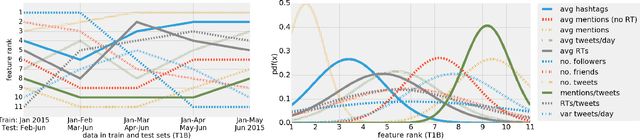
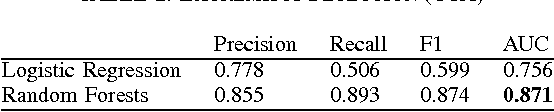
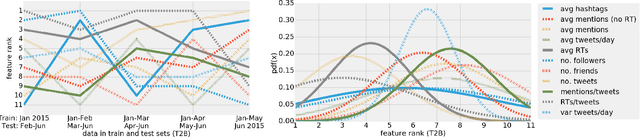
We present a machine learning framework that leverages a mixture of metadata, network, and temporal features to detect extremist users, and predict content adopters and interaction reciprocity in social media. We exploit a unique dataset containing millions of tweets generated by more than 25 thousand users who have been manually identified, reported, and suspended by Twitter due to their involvement with extremist campaigns. We also leverage millions of tweets generated by a random sample of 25 thousand regular users who were exposed to, or consumed, extremist content. We carry out three forecasting tasks, (i) to detect extremist users, (ii) to estimate whether regular users will adopt extremist content, and finally (iii) to predict whether users will reciprocate contacts initiated by extremists. All forecasting tasks are set up in two scenarios: a post hoc (time independent) prediction task on aggregated data, and a simulated real-time prediction task. The performance of our framework is extremely promising, yielding in the different forecasting scenarios up to 93% AUC for extremist user detection, up to 80% AUC for content adoption prediction, and finally up to 72% AUC for interaction reciprocity forecasting. We conclude by providing a thorough feature analysis that helps determine which are the emerging signals that provide predictive power in different scenarios.
* 9 pages, 3 figures, 8 tables
The DARPA Twitter Bot Challenge
Apr 21, 2016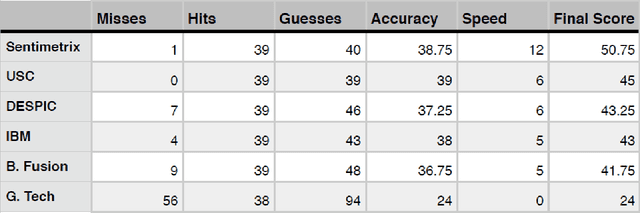
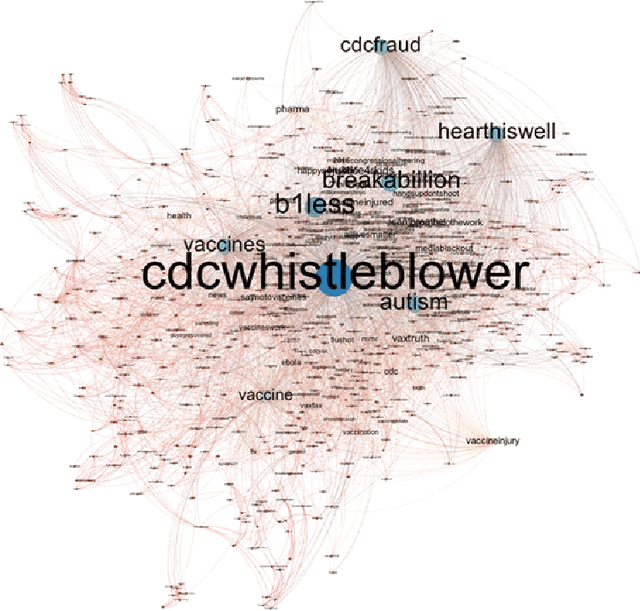
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press