 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2P: An Algorithm for Estimating Heavy-tailed Outcomes
Paper and Code
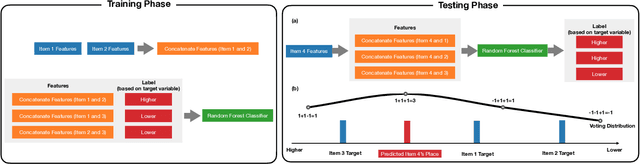
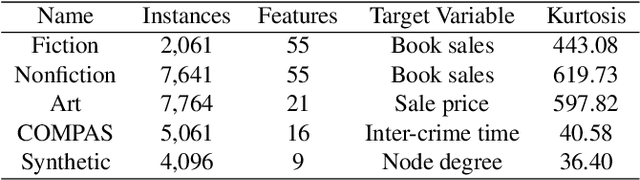
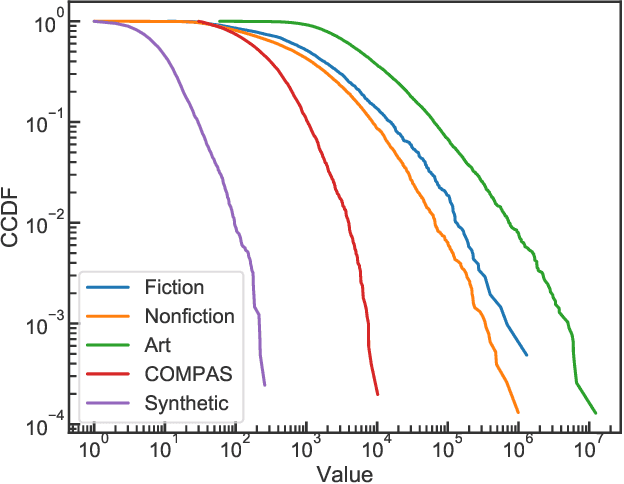
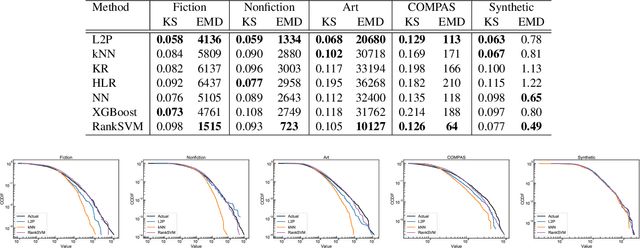
Many real-world prediction tasks have outcome (a.k.a.~target or response) variables that have characteristic heavy-tail distributions. Examples include copies of books sold, auction prices of art pieces, etc. By learning heavy-tailed distributions, ``big and rare'' instances (e.g., the best-sellers) will have accurate predictions. Most existing approaches are not dedicated to learning heavy-tailed distribution; thus, they heavily under-predict such instances. To tackle this problem, we introduce \emph{Learning to Place} (\texttt{L2P}), which exploits the pairwise relationships between instances to learn from a proportionally higher number of rare instances. \texttt{L2P} consists of two stages. In Stage 1, \texttt{L2P} learns a pairwise preference classifier: \textit{is instance A $>$ instance B?}. In Stage 2, \texttt{L2P} learns to place a new instance into an ordinal ranking of known instances. Based on its placement, the new instance is then assigned a value for its outcome variable. Experiments on real data show that \texttt{L2P} outperforms competing approaches in terms of accuracy and capability to reproduce heavy-tailed outcome distribution. In addition, \texttt{L2P} can provide an interpretable model with explainable outcomes by placing each predicted instance in context with its comparable neighbors.