 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Self-Execution Benchmark: Measuring LLMs' Attempts to Overcome Their Lack of Self-Execution
Aug 17, 2025Large language models (LLMs) are commonly evaluated on tasks that test their knowledge or reasoning abilities. In this paper, we explore a different type of evaluation: whether an LLM can predict aspects of its own responses. Since LLMs lack the ability to execute themselves, we introduce the Self-Execution Benchmark, which measures a model's ability to anticipate properties of its output, such as whether a question will be difficult for it, whether it will refuse to answer, or what kinds of associations it is likely to produce. Our experiments show that models generally perform poorly on this benchmark, and that increased model size or capability does not consistently lead to better performance. These results suggest a fundamental limitation in how LLMs represent and reason about their own behavior.
TALL -- A Trainable Architecture for Enhancing LLM Performance in Low-Resource Languages
Jun 05, 2025Large Language Models (LLMs) excel in high-resource languages but struggle with low-resource languages due to limited training data. This paper presents TALL (Trainable Architecture for Enhancing LLM Performance in Low-Resource Languages), which integrates an LLM with two bilingual translation models. TALL transforms low-resource inputs into high-resource representations, leveraging the LLM's capabilities while preserving linguistic features through dimension alignment layers and custom transformers. Our experiments on Hebrew demonstrate significant improvements over several baselines, including direct use, naive translation, and fine-tuning approaches. The architecture employs a parameter-efficient strategy, freezing pre-trained components while training only lightweight adapter modules, balancing computational efficiency with performance gains.
Fool Me, Fool Me: User Attitudes Toward LLM Falsehoods
Dec 16, 2024While Large Language Models (LLMs) have become central tools in various fields, they often provide inaccurate or false information. This study examines user preferences regarding falsehood responses from LLMs. Specifically, we evaluate preferences for LLM responses where false statements are explicitly marked versus unmarked responses and preferences for confident falsehoods compared to LLM disclaimers acknowledging a lack of knowledge. Additionally, we investigate how requiring users to assess the truthfulness of statements influences these preferences. Surprisingly, 61\% of users prefer unmarked falsehood responses over marked ones, and 69\% prefer confident falsehoods over LLMs admitting lack of knowledge. In all our experiments, a total of 300 users participated, contributing valuable data to our analysis and conclusions. When users are required to evaluate the truthfulness of statements, preferences for unmarked and falsehood responses decrease slightly but remain high. These findings suggest that user preferences, which influence LLM training via feedback mechanisms, may inadvertently encourage the generation of falsehoods. Future research should address the ethical and practical implications of aligning LLM behavior with such preferences.
Ruffle&Riley: Insights from Designing and Evaluating a Large Language Model-Based Conversational Tutoring System
Apr 26, 2024Conversational tutoring systems (CTSs) offer learning experiences through interactions based on natural language. They are recognized for promoting cognitive engagement and improving learning outcomes, especially in reasoning tasks. Nonetheless, the cost associated with authoring CTS content is a major obstacle to widespread adoption and to research on effective instructional design. In this paper, we discuss and evaluate a novel type of CTS that leverages recent advances in large language models (LLMs) in two ways: First, the system enables AI-assisted content authoring by inducing an easily editable tutoring script automatically from a lesson text. Second, the system automates the script orchestration in a learning-by-teaching format via two LLM-based agents (Ruffle&Riley) acting as a student and a professor. The system allows for free-form conversations that follow the ITS-typical inner and outer loop structure. We evaluate Ruffle&Riley's ability to support biology lessons in two between-subject online user studies (N = 200) comparing the system to simpler QA chatbots and reading activity. Analyzing system usage patterns, pre/post-test scores and user experience surveys, we find that Ruffle&Riley users report high levels of engagement, understanding and perceive the offered support as helpful. Even though Ruffle&Riley users require more time to complete the activity, we did not find significant differences in short-term learning gains over the reading activity. Our system architecture and user study provide various insights for designers of future CTSs. We further open-source our system to support ongoing research on effective instructional design of LLM-based learning technologies.
Performance of ChatGPT-3.5 and GPT-4 on the United States Medical Licensing Examination With and Without Distractions
Sep 12, 2023
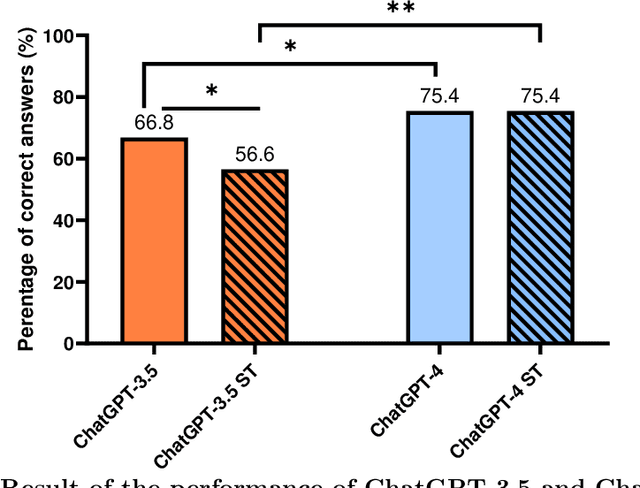


As Large Language Models (LLMs) are predictive models building their response based on the words in the prompts, there is a risk that small talk and irrelevant information may alter the response and the suggestion given. Therefore, this study aims to investigate the impact of medical data mixed with small talk on the accuracy of medical advice provided by ChatGPT. USMLE step 3 questions were used as a model for relevant medical data. We use both multiple choice and open ended questions. We gathered small talk sentences from human participants using the Mechanical Turk platform. Both sets of USLME questions were arranged in a pattern where each sentence from the original questions was followed by a small talk sentence. ChatGPT 3.5 and 4 were asked to answer both sets of questions with and without the small talk sentences. A board-certified physician analyzed the answers by ChatGPT and compared them to the formal correct answer. The analysis results demonstrate that the ability of ChatGPT-3.5 to answer correctly was impaired when small talk was added to medical data for multiple-choice questions (72.1\% vs. 68.9\%) and open questions (61.5\% vs. 44.3\%; p=0.01), respectively. In contrast, small talk phrases did not impair ChatGPT-4 ability in both types of questions (83.6\% and 66.2\%, respectively). According to these results, ChatGPT-4 seems more accurate than the earlier 3.5 version, and it appears that small talk does not impair its capability to provide medical recommendations. Our results are an important first step in understanding the potential and limitations of utilizing ChatGPT and other LLMs for physician-patient interactions, which include casual conversations.
ChatGPT is a Remarkable Tool -- For Experts
Jun 02, 2023This paper investigates the capabilities of ChatGPT as an automated assistant in diverse domains, including scientific writing, mathematics, education, programming, and healthcare. We explore the potential of ChatGPT to enhance productivity, streamline problem-solving processes, and improve writing style. Furthermore, we highlight the potential risks associated with excessive reliance on ChatGPT in these fields. These limitations encompass factors like incorrect and fictitious responses, inaccuracies in code, limited logical reasoning abilities, overconfidence, and critical ethical concerns of copyrights and privacy violation. We outline areas and objectives where ChatGPT proves beneficial, applications where it should be used judiciously, and scenarios where its reliability may be limited. In light of observed limitations, and given that the tool's fundamental errors may pose a special challenge for non-experts, ChatGPT should be used with a strategic methodology. By drawing from comprehensive experimental studies, we offer methods and flow charts for effectively using ChatGPT. Our recommendations emphasize iterative interaction with ChatGPT and independent verification of its outputs. Considering the importance of utilizing ChatGPT judiciously and with expertise, we recommend its usage for experts who are well-versed in the respective domains.
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning
May 24, 2023Open-world survival games pose significant challenges for AI algorithms due to their multi-tasking, deep exploration, and goal prioritization requirements. Despite reinforcement learning (RL) being popular for solving games, its high sample complexity limits its effectiveness in complex open-world games like Crafter or Minecraft. We propose a novel approach, SPRING, to read the game's original academic paper and use the knowledge learned to reason and play the game through a large language model (LLM). Prompted with the LaTeX source as game context and a description of the agent's current observation, our SPRING framework employs a directed acyclic graph (DAG) with game-related questions as nodes and dependencies as edges. We identify the optimal action to take in the environment by traversing the DAG and calculating LLM responses for each node in topological order, with the LLM's answer to final node directly translating to environment actions. In our experiments, we study the quality of in-context "reasoning" induced by different forms of prompts under the setting of the Crafter open-world environment. Our experiments suggest that LLMs, when prompted with consistent chain-of-thought, have great potential in completing sophisticated high-level trajectories. Quantitatively, SPRING with GPT-4 outperforms all state-of-the-art RL baselines, trained for 1M steps, without any training. Finally, we show the potential of games as a test bed for LLMs.
Plan, Eliminate, and Track -- Language Models are Good Teachers for Embodied Agents
May 07, 2023Pre-trained large language models (LLMs) capture procedural knowledge about the world. Recent work has leveraged LLM's ability to generate abstract plans to simplify challenging control tasks, either by action scoring, or action modeling (fine-tuning). However, the transformer architecture inherits several constraints that make it difficult for the LLM to directly serve as the agent: e.g. limited input lengths, fine-tuning inefficiency, bias from pre-training, and incompatibility with non-text environments. To maintain compatibility with a low-level trainable actor, we propose to instead use the knowledge in LLMs to simplify the control problem, rather than solving it. We propose the Plan, Eliminate, and Track (PET) framework. The Plan module translates a task description into a list of high-level sub-tasks. The Eliminate module masks out irrelevant objects and receptacles from the observation for the current sub-task. Finally, the Track module determines whether the agent has accomplished each sub-task. On the AlfWorld instruction following benchmark, the PET framework leads to a significant 15% improvement over SOTA for generalization to human goal specifications.
The Internal State of an LLM Knows When its Lying
Apr 26, 2023While Large Language Models (LLMs) have shown exceptional performance in various tasks, their (arguably) most prominent drawback is generating inaccurate or false information with a confident tone. In this paper, we hypothesize that the LLM's internal state can be used to reveal the truthfulness of a statement. Therefore, we introduce a simple yet effective method to detect the truthfulness of LLM-generated statements, which utilizes the LLM's hidden layer activations to determine the veracity of statements. To train and evaluate our method, we compose a dataset of true and false statements in six different topics. A classifier is trained to detect which statement is true or false based on an LLM's activation values. Specifically, the classifier receives as input the activation values from the LLM for each of the statements in the dataset. Our experiments demonstrate that our method for detecting statement veracity significantly outperforms even few-shot prompting methods, highlighting its potential to enhance the reliability of LLM-generated content and its practical applicability in real-world scenarios.
Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals
Feb 12, 2023High sample complexity has long been a challenge for RL. On the other hand, humans learn to perform tasks not only from interaction or demonstrations, but also by reading unstructured text documents, e.g., instruction manuals. Instruction manuals and wiki pages are among the most abundant data that could inform agents of valuable features and policies or task-specific environmental dynamics and reward structures. Therefore, we hypothesize that the ability to utilize human-written instruction manuals to assist learning policies for specific tasks should lead to a more efficient and better-performing agent. We propose the Read and Reward framework. Read and Reward speeds up RL algorithms on Atari games by reading manuals released by the Atari game developers. Our framework consists of a QA Extraction module that extracts and summarizes relevant information from the manual and a Reasoning module that evaluates object-agent interactions based on information from the manual. Auxiliary reward is then provided to a standard A2C RL agent, when interaction is detected. When assisted by our design, A2C improves on 4 games in the Atari environment with sparse rewards, and requires 1000x less training frames compared to the previous SOTA Agent 57 on Skiing, the hardest game in Atari.