 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticality-Based Varying Step-Number Algorithm for Reinforcement Learning
Jan 13, 2022

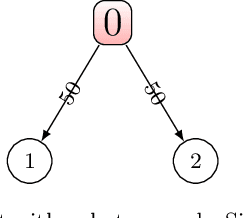
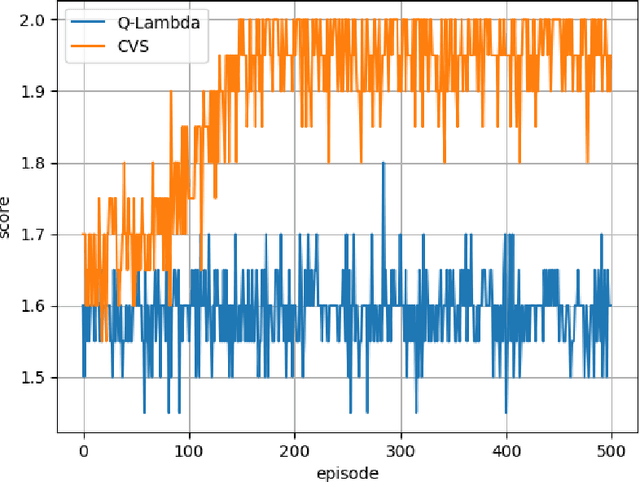
In the context of reinforcement learning we introduce the concept of criticality of a state, which indicates the extent to which the choice of action in that particular state influences the expected return. That is, a state in which the choice of action is more likely to influence the final outcome is considered as more critical than a state in which it is less likely to influence the final outcome. We formulate a criticality-based varying step number algorithm (CVS) - a flexible step number algorithm that utilizes the criticality function provided by a human, or learned directly from the environment. We test it in three different domains including the Atari Pong environment, Road-Tree environment, and Shooter environment. We demonstrate that CVS is able to outperform popular learning algorithms such as Deep Q-Learning and Monte Carlo.
* arXiv admin note: text overlap with arXiv:1810.07254
Revelation of Task Difficulty in AI-aided Education
Jan 12, 2022


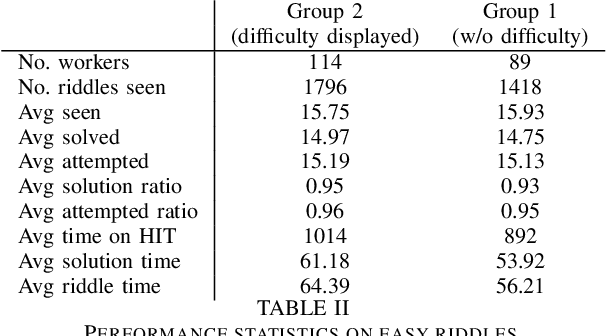
When a student is asked to perform a given task, her subjective estimate of the difficulty of that task has a strong influence on her performance. There exists a rich literature on the impact of perceived task difficulty on performance and motivation. Yet, there is another topic that is closely related to the subject of the influence of perceived task difficulty that did not receive any attention in previous research - the influence of revealing the true difficulty of a task to the student. This paper investigates the impact of revealing the task difficulty on the student's performance, motivation, self-efficacy and subjective task value via an experiment in which workers are asked to solve matchstick riddles. Furthermore, we discuss how the experiment results might be relevant for AI-aided education. Specifically, we elaborate on the question of how a student's learning experience might be improved by supporting her with two types of AI systems: an AI system that predicts task difficulty and an AI system that determines when task difficulty should be revealed and when not.
The Concept of Criticality in AI Safety
Jan 12, 2022When AI agents don't align their actions with human values they may cause serious harm. One way to solve the value alignment problem is by including a human operator who monitors all of the agent's actions. Despite the fact, that this solution guarantees maximal safety, it is very inefficient, since it requires the human operator to dedicate all of his attention to the agent. In this paper, we propose a much more efficient solution that allows an operator to be engaged in other activities without neglecting his monitoring task. In our approach the AI agent requests permission from the operator only for critical actions, that is, potentially harmful actions. We introduce the concept of critical actions with respect to AI safety and discuss how to build a model that measures action criticality. We also discuss how the operator's feedback could be used to make the agent smarter.
The Concept of Criticality in Reinforcement Learning
Oct 16, 2018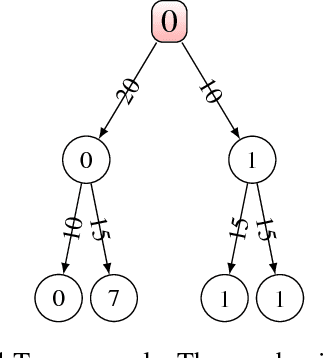
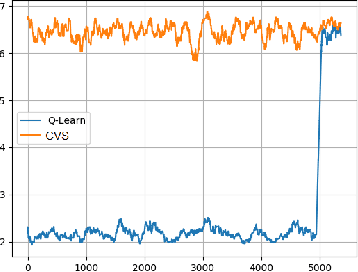


Reinforcement learning methods carry a well known bias-variance trade-off in n-step algorithms for optimal control. Unfortunately, this has rarely been addressed in current research. This trade-off principle holds independent of the choice of the algorithm, such as n-step SARSA, n-step Expected SARSA or n-step Tree backup. A small n results in a large bias, while a large n leads to large variance. The literature offers no straightforward recipe for the best choice of this value. While currently all n-step algorithms use a fixed value of n over the state space we extend the framework of n-step updates by allowing each state to have its specific n. We propose a solution to this problem within the context of human aided reinforcement learning. Our approach is based on the observation that a human can learn more efficiently if she receives input regarding the criticality of a given state and thus the amount of attention she needs to invest into the learning in that state. This observation is related to the idea that each state of the MDP has a certain measure of criticality which indicates how much the choice of the action in that state influences the return. In our algorithm the RL agent utilizes the criticality measure, a function provided by a human trainer, in order to locally choose the best stepnumber n for the update of the Q function.