 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext and Transcripts Improve Detection of Deepfake Audios of Public Figures
Jan 19, 2026Humans use context to assess the veracity of information. However, current audio deepfake detectors only analyze the audio file without considering either context or transcripts. We create and analyze a Journalist-provided Deepfake Dataset (JDD) of 255 public deepfakes which were primarily contributed by over 70 journalists since early 2024. We also generate a synthetic audio dataset (SYN) of dead public figures and propose a novel Context-based Audio Deepfake Detector (CADD) architecture. In addition, we evaluate performance on two large-scale datasets: ITW and P$^2$V. We show that sufficient context and/or the transcript can significantly improve the efficacy of audio deepfake detectors. Performance (measured via F1 score, AUC, and EER) of multiple baseline audio deepfake detectors and traditional classifiers can be improved by 5%-37.58% in F1-score, 3.77%-42.79% in AUC, and 6.17%-47.83% in EER. We additionally show that CADD, via its use of context and/or transcripts, is more robust to 5 adversarial evasion strategies, limiting performance degradation to an average of just -0.71% across all experiments. Code, models, and datasets are available at our project page: https://sites.northwestern.edu/nsail/cadd-context-based-audio-deepfake-detection (access restricted during review).
Mitigating Adversarial Gray-Box Attacks Against Phishing Detectors
Dec 11, 2022



Although machine learning based algorithms have been extensively used for detecting phishing websites, there has been relatively little work on how adversaries may attack such "phishing detectors" (PDs for short). In this paper, we propose a set of Gray-Box attacks on PDs that an adversary may use which vary depending on the knowledge that he has about the PD. We show that these attacks severely degrade the effectiveness of several existing PDs. We then propose the concept of operation chains that iteratively map an original set of features to a new set of features and develop the "Protective Operation Chain" (POC for short) algorithm. POC leverages the combination of random feature selection and feature mappings in order to increase the attacker's uncertainty about the target PD. Using 3 existing publicly available datasets plus a fourth that we have created and will release upon the publication of this paper, we show that POC is more robust to these attacks than past competing work, while preserving predictive performance when no adversarial attacks are present. Moreover, POC is robust to attacks on 13 different classifiers, not just one. These results are shown to be statistically significant at the p < 0.001 level.
M2P2: Multimodal Persuasion Prediction using Adaptive Fusion
Jun 03, 2020

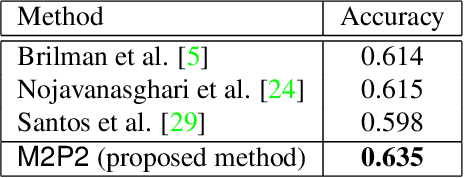

Identifying persuasive speakers in an adversarial environment is a critical task. In a national election, politicians would like to have persuasive speakers campaign on their behalf. When a company faces adverse publicity, they would like to engage persuasive advocates for their position in the presence of adversaries who are critical of them. Debates represent a common platform for these forms of adversarial persuasion. This paper solves two problems: the Debate Outcome Prediction (DOP) problem predicts who wins a debate while the Intensity of Persuasion Prediction (IPP) problem predicts the change in the number of votes before and after a speaker speaks. Though DOP has been previously studied, we are the first to study IPP. Past studies on DOP fail to leverage two important aspects of multimodal data: 1) multiple modalities are often semantically aligned, and 2) different modalities may provide diverse information for prediction. Our M2P2 (Multimodal Persuasion Prediction) framework is the first to use multimodal (acoustic, visual, language) data to solve the IPP problem. To leverage the alignment of different modalities while maintaining the diversity of the cues they provide, M2P2 devises a novel adaptive fusion learning framework which fuses embeddings obtained from two modules -- an alignment module that extracts shared information between modalities and a heterogeneity module that learns the weights of different modalities with guidance from three separately trained unimodal reference models. We test M2P2 on the popular IQ2US dataset designed for DOP. We also introduce a new dataset called QPS (from Qipashuo, a popular Chinese debate TV show ) for IPP. M2P2 significantly outperforms 3 recent baselines on both datasets. Our code and QPS dataset can be found at http://snap.stanford.edu/m2p2/.
BB_Evac: Fast Location-Sensitive Behavior-Based Building Evacuation
Feb 19, 2020
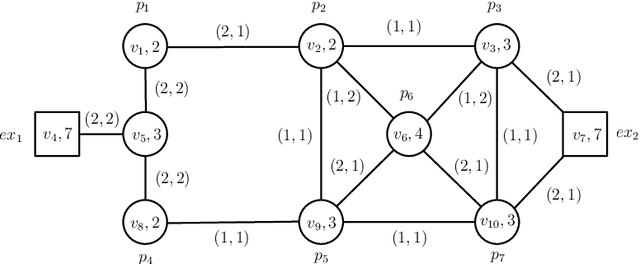
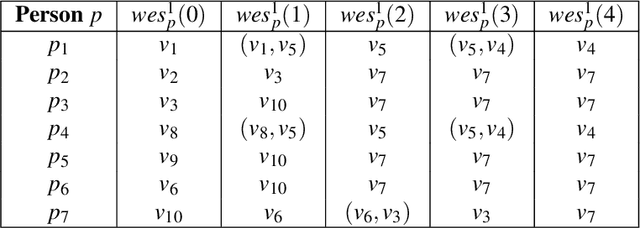
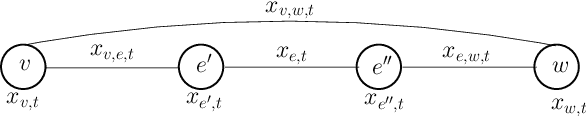
Past work on evacuation planning assumes that evacuees will follow instructions -- however, there is ample evidence that this is not the case. While some people will follow instructions, others will follow their own desires. In this paper, we present a formal definition of a behavior-based evacuation problem (BBEP) in which a human behavior model is taken into account when planning an evacuation. We show that a specific form of constraints can be used to express such behaviors. We show that BBEPs can be solved exactly via an integer program called BB_IP, and inexactly by a much faster algorithm that we call BB_Evac. We conducted a detailed experimental evaluation of both algorithms applied to buildings (though in principle the algorithms can be applied to any graphs) and show that the latter is an order of magnitude faster than BB_IP while producing results that are almost as good on one real-world building graph and as well as on several synthetically generated graphs.
C2P2: A Collective Cryptocurrency Up/Down Price Prediction Engine
Jun 03, 2019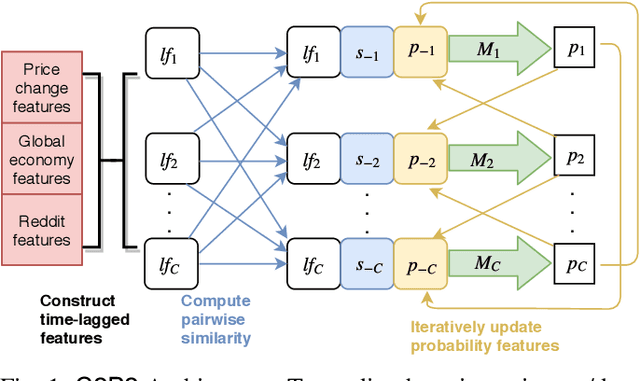
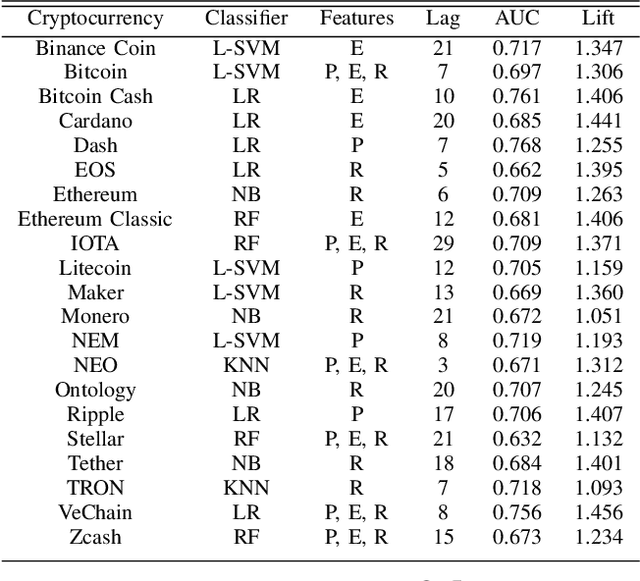
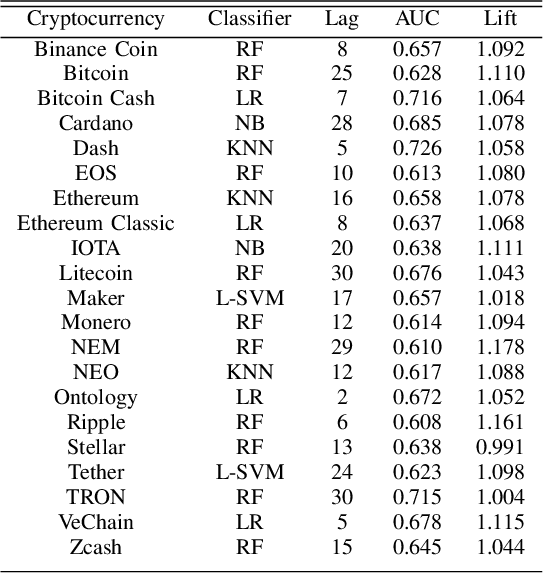
We study the problem of predicting whether the price of the 21 most popular cryptocurrencies (according to coinmarketcap.com) will go up or down on day d, using data up to day d-1. Our C2P2 algorithm is the first algorithm to consider the fact that the price of a cryptocurrency c might depend not only on historical prices, sentiments, global stock indices, but also on the prices and predicted prices of other cryptocurrencies. C2P2 therefore does not predict cryptocurrency prices one coin at a time --- rather it uses similarity metrics in conjunction with collective classification to compare multiple cryptocurrency features to jointly predict the cryptocurrency prices for all 21 coins considered. We show that our C2P2 algorithm beats out a recent competing 2017 paper by margins varying from 5.1-83% and another Bitcoin-specific prediction paper from 2018 by 16%. In both cases, C2P2 is the winner on all cryptocurrencies considered. Moreover, we experimentally show that the use of similarity metrics within our C2P2 algorithm leads to a direct improvement for 20 out of 21 cryptocurrencies ranging from 0.4% to 17.8%. Without the similarity component, C2P2 still beats competitors on 20 out of 21 cryptocurrencies considered. We show that all these results are statistically significant via a Student's t-test with p<1e-5. Check our demo at https://www.cs.dartmouth.edu/dsail/demos/c2p2
Automatic Long-Term Deception Detection in Group Interaction Videos
May 15, 2019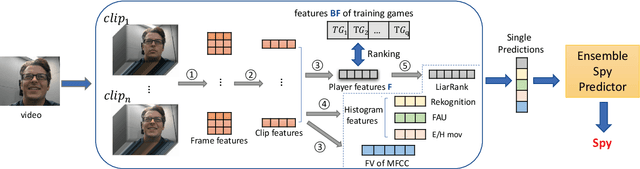
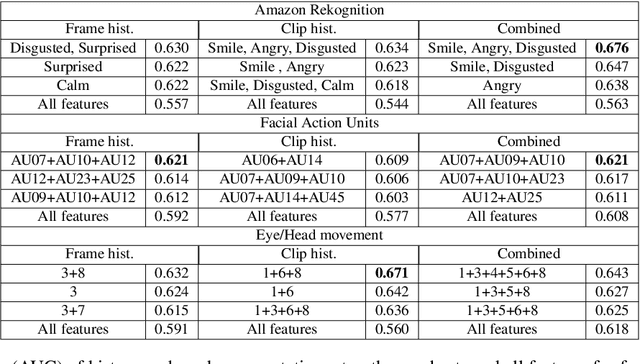
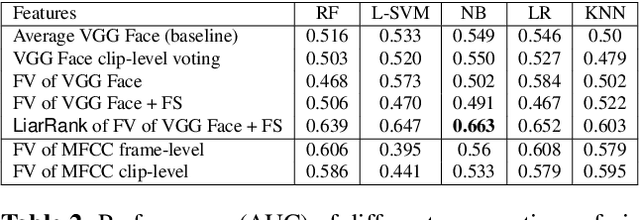
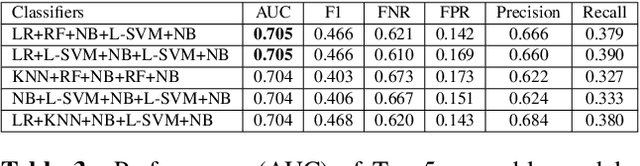
Most work on automated deception detection (ADD) in video has two restrictions: (i) it focuses on a video of one person, and (ii) it focuses on a single act of deception in a one or two minute video. In this paper, we propose a new ADD framework which captures long term deception in a group setting. We study deception in the well-known Resistance game (like Mafia and Werewolf) which consists of 5-8 players of whom 2-3 are spies. Spies are deceptive throughout the game (typically 30-65 minutes) to keep their identity hidden. We develop an ensemble predictive model to identify spies in Resistance videos. We show that features from low-level and high-level video analysis are insufficient, but when combined with a new class of features that we call LiarRank, produce the best results. We achieve AUCs of over 0.70 in a fully automated setting. Our demo can be found at http://home.cs.dartmouth.edu/~mbolonkin/scan/demo/
Deception Detection in Videos
Dec 12, 2017


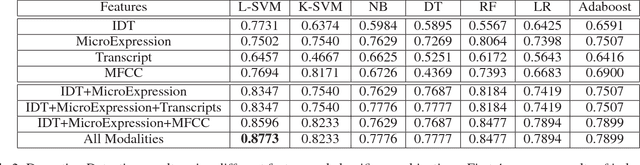
We present a system for covert automated deception detection in real-life courtroom trial videos. We study the importance of different modalities like vision, audio and text for this task. On the vision side, our system uses classifiers trained on low level video features which predict human micro-expressions. We show that predictions of high-level micro-expressions can be used as features for deception prediction. Surprisingly, IDT (Improved Dense Trajectory) features which have been widely used for action recognition, are also very good at predicting deception in videos. We fuse the score of classifiers trained on IDT features and high-level micro-expressions to improve performance. MFCC (Mel-frequency Cepstral Coefficients) features from the audio domain also provide a significant boost in performance, while information from transcripts is not very beneficial for our system. Using various classifiers, our automated system obtains an AUC of 0.877 (10-fold cross-validation) when evaluated on subjects which were not part of the training set. Even though state-of-the-art methods use human annotations of micro-expressions for deception detection, our fully automated approach outperforms them by 5%. When combined with human annotations of micro-expressions, our AUC improves to 0.922. We also present results of a user-study to analyze how well do average humans perform on this task, what modalities they use for deception detection and how they perform if only one modality is accessible. Our project page can be found at \url{https://doubaibai.github.io/DARE/}.
An Army of Me: Sockpuppets in Online Discussion Communities
Mar 21, 2017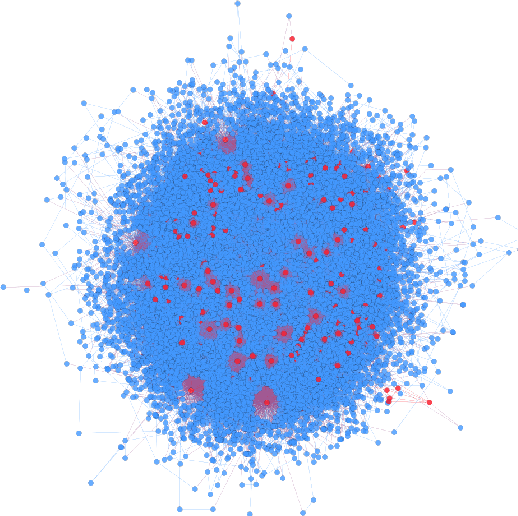
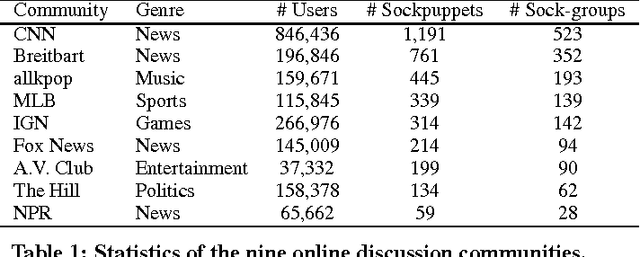
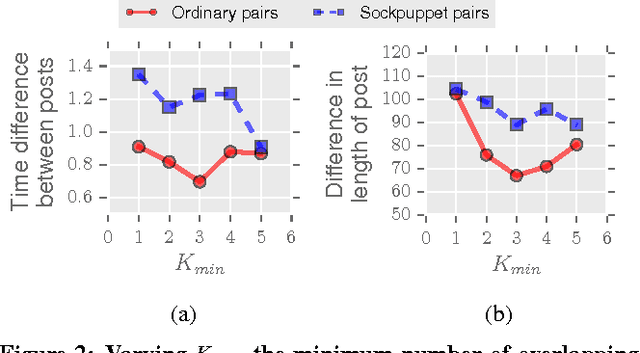

In online discussion communities, users can interact and share information and opinions on a wide variety of topics. However, some users may create multiple identities, or sockpuppets, and engage in undesired behavior by deceiving others or manipulating discussions. In this work, we study sockpuppetry across nine discussion communities, and show that sockpuppets differ from ordinary users in terms of their posting behavior, linguistic traits, as well as social network structure. Sockpuppets tend to start fewer discussions, write shorter posts, use more personal pronouns such as "I", and have more clustered ego-networks. Further, pairs of sockpuppets controlled by the same individual are more likely to interact on the same discussion at the same time than pairs of ordinary users. Our analysis suggests a taxonomy of deceptive behavior in discussion communities. Pairs of sockpuppets can vary in their deceptiveness, i.e., whether they pretend to be different users, or their supportiveness, i.e., if they support arguments of other sockpuppets controlled by the same user. We apply these findings to a series of prediction tasks, notably, to identify whether a pair of accounts belongs to the same underlying user or not. Altogether, this work presents a data-driven view of deception in online discussion communities and paves the way towards the automatic detection of sockpuppets.
The DARPA Twitter Bot Challenge
Apr 21, 2016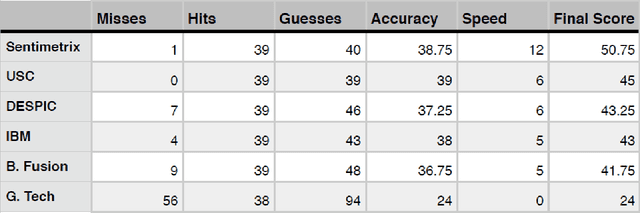
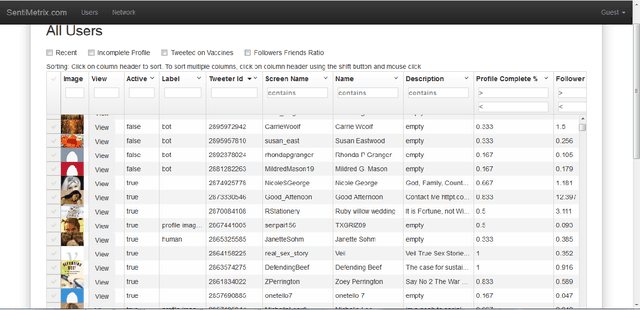
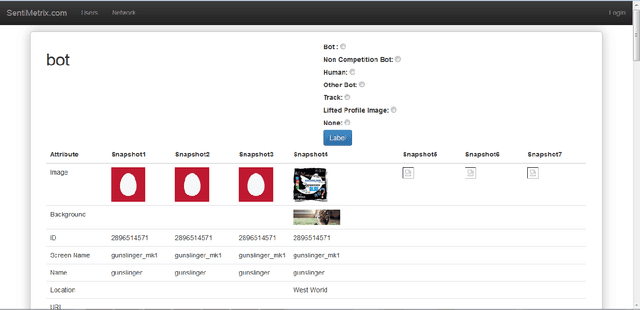
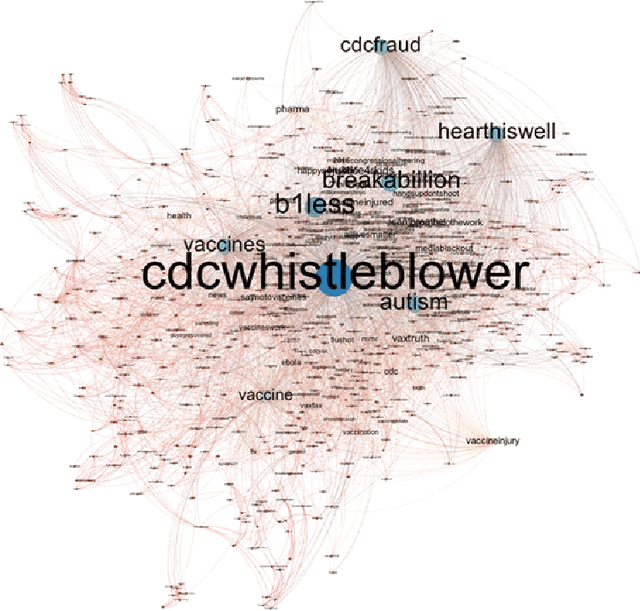
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press
Non-monotonic Negation in Probabilistic Deductive Databases
Mar 20, 2013In this paper we study the uses and the semantics of non-monotonic negation in probabilistic deductive data bases. Based on the stable semantics for classical logic programming, we introduce the notion of stable formula, functions. We show that stable formula, functions are minimal fixpoints of operators associated with probabilistic deductive databases with negation. Furthermore, since a. probabilistic deductive database may not necessarily have a stable formula function, we provide a stable class semantics for such databases. Finally, we demonstrate that the proposed semantics can handle default reasoning naturally in the context of probabilistic deduction.