 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2P2: Multimodal Persuasion Prediction using Adaptive Fusion
Paper and Code


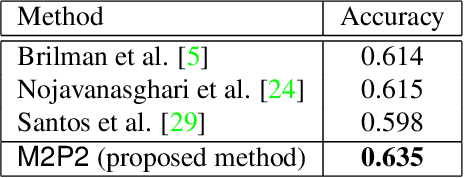

Identifying persuasive speakers in an adversarial environment is a critical task. In a national election, politicians would like to have persuasive speakers campaign on their behalf. When a company faces adverse publicity, they would like to engage persuasive advocates for their position in the presence of adversaries who are critical of them. Debates represent a common platform for these forms of adversarial persuasion. This paper solves two problems: the Debate Outcome Prediction (DOP) problem predicts who wins a debate while the Intensity of Persuasion Prediction (IPP) problem predicts the change in the number of votes before and after a speaker speaks. Though DOP has been previously studied, we are the first to study IPP. Past studies on DOP fail to leverage two important aspects of multimodal data: 1) multiple modalities are often semantically aligned, and 2) different modalities may provide diverse information for prediction. Our M2P2 (Multimodal Persuasion Prediction) framework is the first to use multimodal (acoustic, visual, language) data to solve the IPP problem. To leverage the alignment of different modalities while maintaining the diversity of the cues they provide, M2P2 devises a novel adaptive fusion learning framework which fuses embeddings obtained from two modules -- an alignment module that extracts shared information between modalities and a heterogeneity module that learns the weights of different modalities with guidance from three separately trained unimodal reference models. We test M2P2 on the popular IQ2US dataset designed for DOP. We also introduce a new dataset called QPS (from Qipashuo, a popular Chinese debate TV show ) for IPP. M2P2 significantly outperforms 3 recent baselines on both datasets. Our code and QPS dataset can be found at http://snap.stanford.edu/m2p2/.