 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Synthetic Data for Machine Learning-based Childhood Vaccination Prediction in Narok, Kenya
Apr 10, 2026Background: Limited data utilization in low-resource settings poses a barrier to the vaccine delivery ecosystem, undermining efforts to achieve equitable immunization coverage. In nomadic populations, individuals face an increased risk of missing crucial vaccination doses as children. One such population is the Maasai in Narok County, Kenya, where the absence of high-volume, quality data hampers accurate coverage estimates, impedes efficient resource allocation, and weakens the ability to deliver timely interventions. Additionally, data privacy concerns are heightened in groups with limited sensitive data. Objectives: First, we aim to identify children at risk of missing key vaccines across a large population to provide timely, evidence-based interventions that support increased vaccination coverage. Second, we aim to better protect the privacy of sensitive health data in a vulnerable population. Methods: We digitized 8 years of child vaccination records from the MOH 510 registry (n=6,913) and applied machine learning models (Logistic Regression and XGBoost) to identify children at risk. Additionally, we utilize a novel approach to tabular diffusion-based synthetic data generation (TabSyn) to protect patient privacy within the models. Results: Our findings show that classification techniques can reliably and successfully predict children at risk of missing a vaccine, with recall, precision, and F1-scores exceeding 90% for some vaccines modeled. Additionally, training these models with synthetic data rather than real data, thus preserving the privacy of individuals within the original dataset, does not lead to a loss in predictive performance. Conclusion: These results support the use of synthetic data implementation in health informatics strategies for clinics with limited digital infrastructure, enabling privacy-preserving, scalable forecasting for childhood immunization coverage.
Speculative Sampling with Reinforcement Learning
Jan 18, 2026Inference time latency has remained an open challenge for real world applications of large language models (LLMs). State-of-the-art (SOTA) speculative sampling (SpS) methods for LLMs, like EAGLE-3, use tree-based drafting to explore multiple candidate continuations in parallel. However, the hyperparameters controlling the tree structure are static, which limits flexibility and efficiency across diverse contexts and domains. We introduce Reinforcement learning for Speculative Sampling (Re-SpS), the first reinforcement learning (RL)-based framework for draft tree hyperparameter optimization. Re-SpS dynamically adjusts draft tree hyperparameters in real-time, learning context-aware policies that maximize generation speed by balancing speculative aggression with computational overhead. It leverages efficient state representations from target model hidden states and introduces multi-step action persistence for better context modeling. Evaluation results across five diverse benchmarks demonstrate consistent improvements over the SOTA method EAGLE-3, achieving up to 5.45$\times$ speedup over the backbone LLM and up to 1.12$\times$ speedup compared to EAGLE-3 across five diverse benchmarks, with no loss in output fidelity.
DIP: Dynamic In-Context Planner For Diffusion Language Models
Jan 06, 2026Diffusion language models (DLMs) have shown strong potential for general natural language tasks with in-context examples. However, due to the bidirectional attention mechanism, DLMs incur substantial computational cost as context length increases. This work addresses this issue with a key discovery: unlike the sequential generation in autoregressive language models (ARLMs), the diffusion generation paradigm in DLMs allows \textit{efficient dynamic adjustment of the context} during generation. Building on this insight, we propose \textbf{D}ynamic \textbf{I}n-Context \textbf{P}lanner (DIP), a context-optimization method that dynamically selects and inserts in-context examples during generation, rather than providing all examples in the prompt upfront. Results show DIP maintains generation quality while achieving up to 12.9$\times$ inference speedup over standard inference and 1.17$\times$ over KV cache-enhanced inference.
HVIS: A Human-like Vision and Inference System for Human Motion Prediction
Feb 24, 2025Grasping the intricacies of human motion, which involve perceiving spatio-temporal dependence and multi-scale effects, is essential for predicting human motion. While humans inherently possess the requisite skills to navigate this issue, it proves to be markedly more challenging for machines to emulate. To bridge the gap, we propose the Human-like Vision and Inference System (HVIS) for human motion prediction, which is designed to emulate human observation and forecast future movements. HVIS comprises two components: the human-like vision encode (HVE) module and the human-like motion inference (HMI) module. The HVE module mimics and refines the human visual process, incorporating a retina-analog component that captures spatiotemporal information separately to avoid unnecessary crosstalk. Additionally, a visual cortex-analogy component is designed to hierarchically extract and treat complex motion features, focusing on both global and local features of human poses. The HMI is employed to simulate the multi-stage learning model of the human brain. The spontaneous learning network simulates the neuronal fracture generation process for the adversarial generation of future motions. Subsequently, the deliberate learning network is optimized for hard-to-train joints to prevent misleading learning. Experimental results demonstrate that our method achieves new state-of-the-art performance, significantly outperforming existing methods by 19.8% on Human3.6M, 15.7% on CMU Mocap, and 11.1% on G3D.
Sequential Stochastic Combinatorial Optimization Using Hierarchal Reinforcement Learning
Feb 08, 2025Reinforcement learning (RL) has emerged as a promising tool for combinatorial optimization (CO) problems due to its ability to learn fast, effective, and generalizable solutions. Nonetheless, existing works mostly focus on one-shot deterministic CO, while sequential stochastic CO (SSCO) has rarely been studied despite its broad applications such as adaptive influence maximization (IM) and infectious disease intervention. In this paper, we study the SSCO problem where we first decide the budget (e.g., number of seed nodes in adaptive IM) allocation for all time steps, and then select a set of nodes for each time step. The few existing studies on SSCO simplify the problems by assuming a uniformly distributed budget allocation over the time horizon, yielding suboptimal solutions. We propose a generic hierarchical RL (HRL) framework called wake-sleep option (WS-option), a two-layer option-based framework that simultaneously decides adaptive budget allocation on the higher layer and node selection on the lower layer. WS-option starts with a coherent formulation of the two-layer Markov decision processes (MDPs), capturing the interdependencies between the two layers of decisions. Building on this, WS-option employs several innovative designs to balance the model's training stability and computational efficiency, preventing the vicious cyclic interference issue between the two layers. Empirical results show that WS-option exhibits significantly improved effectiveness and generalizability compared to traditional methods. Moreover, the learned model can be generalized to larger graphs, which significantly reduces the overhead of computational resources.
Causal-Inspired Multitask Learning for Video-Based Human Pose Estimation
Jan 24, 2025Video-based human pose estimation has long been a fundamental yet challenging problem in computer vision. Previous studies focus on spatio-temporal modeling through the enhancement of architecture design and optimization strategies. However, they overlook the causal relationships in the joints, leading to models that may be overly tailored and thus estimate poorly to challenging scenes. Therefore, adequate causal reasoning capability, coupled with good interpretability of model, are both indispensable and prerequisite for achieving reliable results. In this paper, we pioneer a causal perspective on pose estimation and introduce a causal-inspired multitask learning framework, consisting of two stages. \textit{In the first stage}, we try to endow the model with causal spatio-temporal modeling ability by introducing two self-supervision auxiliary tasks. Specifically, these auxiliary tasks enable the network to infer challenging keypoints based on observed keypoint information, thereby imbuing causal reasoning capabilities into the model and making it robust to challenging scenes. \textit{In the second stage}, we argue that not all feature tokens contribute equally to pose estimation. Prioritizing causal (keypoint-relevant) tokens is crucial to achieve reliable results, which could improve the interpretability of the model. To this end, we propose a Token Causal Importance Selection module to identify the causal tokens and non-causal tokens (\textit{e.g.}, background and objects). Additionally, non-causal tokens could provide potentially beneficial cues but may be redundant. We further introduce a non-causal tokens clustering module to merge the similar non-causal tokens. Extensive experiments show that our method outperforms state-of-the-art methods on three large-scale benchmark datasets.
CultureVLM: Characterizing and Improving Cultural Understanding of Vision-Language Models for over 100 Countries
Jan 02, 2025Vision-language models (VLMs) have advanced human-AI interaction but struggle with cultural understanding, often misinterpreting symbols, gestures, and artifacts due to biases in predominantly Western-centric training data. In this paper, we construct CultureVerse, a large-scale multimodal benchmark covering 19, 682 cultural concepts, 188 countries/regions, 15 cultural concepts, and 3 question types, with the aim of characterizing and improving VLMs' multicultural understanding capabilities. Then, we propose CultureVLM, a series of VLMs fine-tuned on our dataset to achieve significant performance improvement in cultural understanding. Our evaluation of 16 models reveals significant disparities, with a stronger performance in Western concepts and weaker results in African and Asian contexts. Fine-tuning on our CultureVerse enhances cultural perception, demonstrating cross-cultural, cross-continent, and cross-dataset generalization without sacrificing performance on models' general VLM benchmarks. We further present insights on cultural generalization and forgetting. We hope that this work could lay the foundation for more equitable and culturally aware multimodal AI systems.
Population Aware Diffusion for Time Series Generation
Jan 01, 2025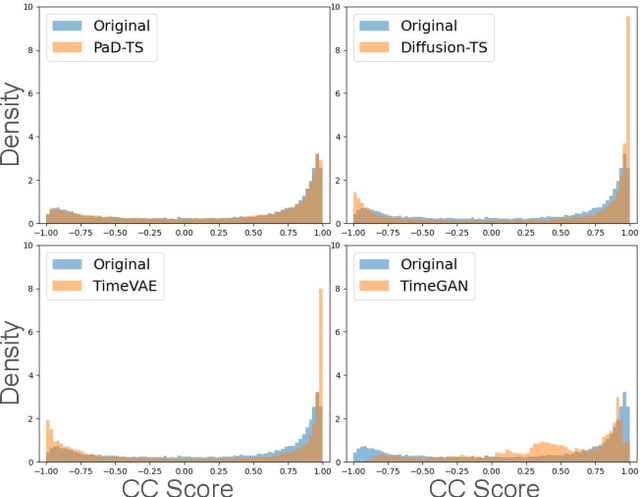



Diffusion models have shown promising ability in generating high-quality time series (TS) data. Despite the initial success, existing works mostly focus on the authenticity of data at the individual level, but pay less attention to preserving the population-level properties on the entire dataset. Such population-level properties include value distributions for each dimension and distributions of certain functional dependencies (e.g., cross-correlation, CC) between different dimensions. For instance, when generating house energy consumption TS data, the value distributions of the outside temperature and the kitchen temperature should be preserved, as well as the distribution of CC between them. Preserving such TS population-level properties is critical in maintaining the statistical insights of the datasets, mitigating model bias, and augmenting downstream tasks like TS prediction. Yet, it is often overlooked by existing models. Hence, data generated by existing models often bear distribution shifts from the original data. We propose Population-aware Diffusion for Time Series (PaD-TS), a new TS generation model that better preserves the population-level properties. The key novelties of PaD-TS include 1) a new training method explicitly incorporating TS population-level property preservation, and 2) a new dual-channel encoder model architecture that better captures the TS data structure. Empirical results in major benchmark datasets show that PaD-TS can improve the average CC distribution shift score between real and synthetic data by 5.9x while maintaining a performance comparable to state-of-the-art models on individual-level authenticity.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Focused ReAct: Improving ReAct through Reiterate and Early Stop
Oct 14, 2024
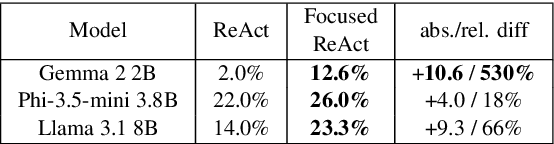

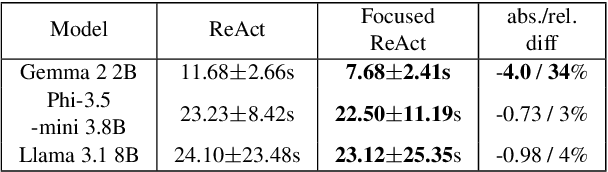
Large language models (LLMs) have significantly improved their reasoning and decision-making capabilities, as seen in methods like ReAct. However, despite its effectiveness in tackling complex tasks, ReAct faces two main challenges: losing focus on the original question and becoming stuck in action loops. To address these issues, we introduce Focused ReAct, an enhanced version of the ReAct paradigm that incorporates reiteration and early stop mechanisms. These improvements help the model stay focused on the original query and avoid repetitive behaviors. Experimental results show accuracy gains of 18% to 530% and a runtime reduction of up to 34% compared to the original ReAct method.