Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused ReAct: Improving ReAct through Reiterate and Early Stop
Paper and Code

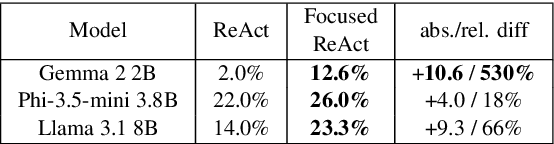

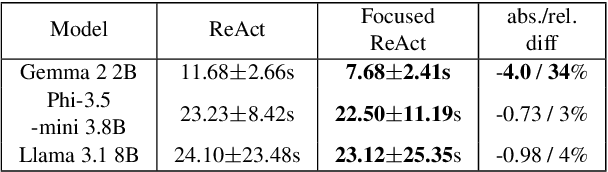
Large language models (LLMs) have significantly improved their reasoning and decision-making capabilities, as seen in methods like ReAct. However, despite its effectiveness in tackling complex tasks, ReAct faces two main challenges: losing focus on the original question and becoming stuck in action loops. To address these issues, we introduce Focused ReAct, an enhanced version of the ReAct paradigm that incorporates reiteration and early stop mechanisms. These improvements help the model stay focused on the original query and avoid repetitive behaviors. Experimental results show accuracy gains of 18% to 530% and a runtime reduction of up to 34% compared to the original ReAct method.
* The Eighth Widening NLP Workshop (WiNLP 2024)
View paper on