 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoMotionGPT: Geometry-Aligned Motion Understanding with Large Language Models
Jan 12, 2026Discrete motion tokenization has recently enabled Large Language Models (LLMs) to serve as versatile backbones for motion understanding and motion-language reasoning. However, existing pipelines typically decouple motion quantization from semantic embedding learning, linking them solely via token IDs. This approach fails to effectively align the intrinsic geometry of the motion space with the embedding space, thereby hindering the LLM's capacity for nuanced motion reasoning. We argue that alignment is most effective when both modalities share a unified geometric basis. Therefore, instead of forcing the LLM to reconstruct the complex geometry among motion tokens from scratch, we present a novel framework that explicitly enforces orthogonality on both the motion codebook and the LLM embedding space, ensuring that their relational structures naturally mirror each other. Specifically, we employ a decoder-only quantizer with Gumbel-Softmax for differentiable training and balanced codebook usage. To bridge the modalities, we use a sparse projection that maps motion codes into the LLM embedding space while preserving orthogonality. Finally, a two-stage orthonormal regularization schedule enforces soft constraints during tokenizer training and LLM fine-tuning to maintain geometric alignment without hindering semantic adaptation. Extensive experiments on HumanML3D demonstrate that our framework achieves a 20% performance improvement over current state-of-the-art methods, validating that a unified geometric basis effectively empowers the LLM for nuanced motion reasoning.
Focused ReAct: Improving ReAct through Reiterate and Early Stop
Oct 14, 2024
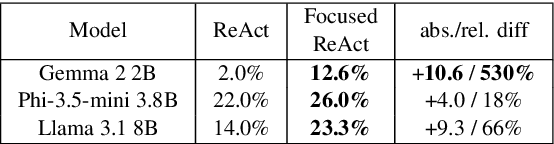

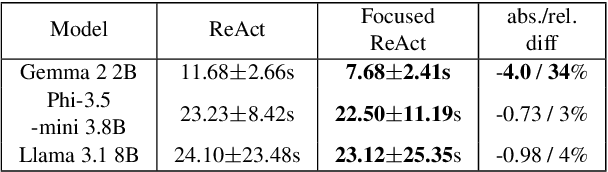
Large language models (LLMs) have significantly improved their reasoning and decision-making capabilities, as seen in methods like ReAct. However, despite its effectiveness in tackling complex tasks, ReAct faces two main challenges: losing focus on the original question and becoming stuck in action loops. To address these issues, we introduce Focused ReAct, an enhanced version of the ReAct paradigm that incorporates reiteration and early stop mechanisms. These improvements help the model stay focused on the original query and avoid repetitive behaviors. Experimental results show accuracy gains of 18% to 530% and a runtime reduction of up to 34% compared to the original ReAct method.