 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Inspired Multitask Learning for Video-Based Human Pose Estimation
Jan 24, 2025Video-based human pose estimation has long been a fundamental yet challenging problem in computer vision. Previous studies focus on spatio-temporal modeling through the enhancement of architecture design and optimization strategies. However, they overlook the causal relationships in the joints, leading to models that may be overly tailored and thus estimate poorly to challenging scenes. Therefore, adequate causal reasoning capability, coupled with good interpretability of model, are both indispensable and prerequisite for achieving reliable results. In this paper, we pioneer a causal perspective on pose estimation and introduce a causal-inspired multitask learning framework, consisting of two stages. \textit{In the first stage}, we try to endow the model with causal spatio-temporal modeling ability by introducing two self-supervision auxiliary tasks. Specifically, these auxiliary tasks enable the network to infer challenging keypoints based on observed keypoint information, thereby imbuing causal reasoning capabilities into the model and making it robust to challenging scenes. \textit{In the second stage}, we argue that not all feature tokens contribute equally to pose estimation. Prioritizing causal (keypoint-relevant) tokens is crucial to achieve reliable results, which could improve the interpretability of the model. To this end, we propose a Token Causal Importance Selection module to identify the causal tokens and non-causal tokens (\textit{e.g.}, background and objects). Additionally, non-causal tokens could provide potentially beneficial cues but may be redundant. We further introduce a non-causal tokens clustering module to merge the similar non-causal tokens. Extensive experiments show that our method outperforms state-of-the-art methods on three large-scale benchmark datasets.
Action Recognition with Multi-stream Motion Modeling and Mutual Information Maximization
Jun 13, 2023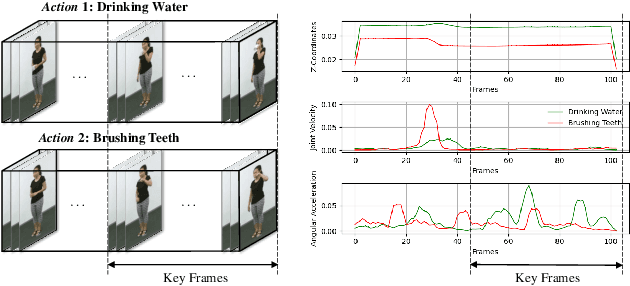
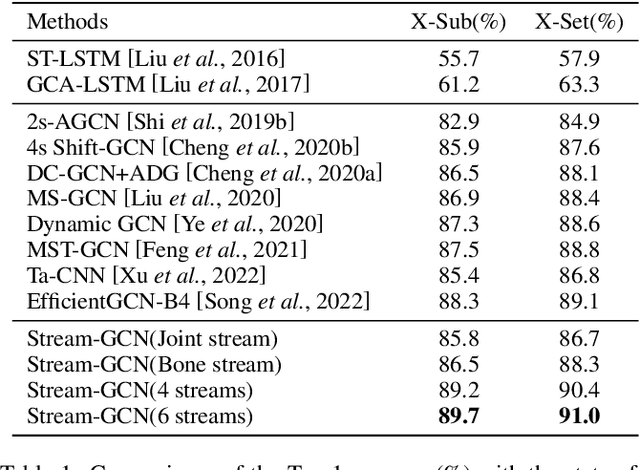
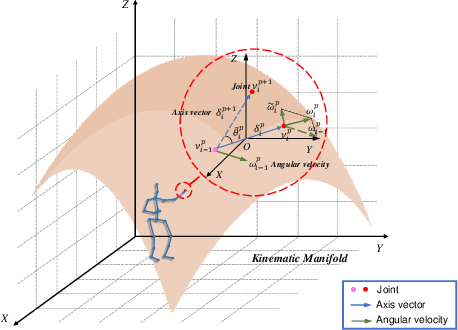
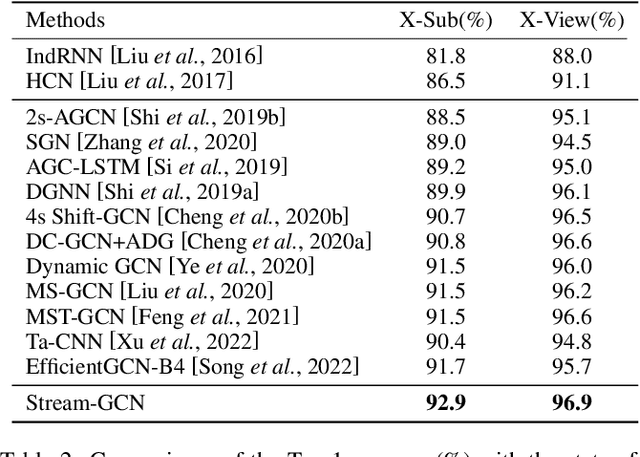
Action recognition has long been a fundamental and intriguing problem in artificial intelligence. The task is challenging due to the high dimensionality nature of an action, as well as the subtle motion details to be considered. Current state-of-the-art approaches typically learn from articulated motion sequences in the straightforward 3D Euclidean space. However, the vanilla Euclidean space is not efficient for modeling important motion characteristics such as the joint-wise angular acceleration, which reveals the driving force behind the motion. Moreover, current methods typically attend to each channel equally and lack theoretical constrains on extracting task-relevant features from the input. In this paper, we seek to tackle these challenges from three aspects: (1) We propose to incorporate an acceleration representation, explicitly modeling the higher-order variations in motion. (2) We introduce a novel Stream-GCN network equipped with multi-stream components and channel attention, where different representations (i.e., streams) supplement each other towards a more precise action recognition while attention capitalizes on those important channels. (3) We explore feature-level supervision for maximizing the extraction of task-relevant information and formulate this into a mutual information loss. Empirically, our approach sets the new state-of-the-art performance on three benchmark datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. Our code is anonymously released at https://github.com/ActionR-Group/Stream-GCN, hoping to inspire the community.