 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Knowledge Boundary: An Interactive Agentic Framework for Deep Knowledge Extraction
Feb 01, 2026Large Language Models (LLMs) can be seen as compressed knowledge bases, but it remains unclear what knowledge they truly contain and how far their knowledge boundaries extend. Existing benchmarks are mostly static and provide limited support for systematic knowledge probing. In this paper, we propose an interactive agentic framework to systematically extract and quantify the knowledge of LLMs. Our method includes four adaptive exploration policies to probe knowledge at different granularities. To ensure the quality of extracted knowledge, we introduce a three-stage knowledge processing pipeline that combines vector-based filtering to remove exact duplicates, LLM-based adjudication to resolve ambiguous semantic overlaps, and domain-relevance auditing to retain valid knowledge units. Through extensive experiments, we find that recursive taxonomy is the most effective exploration strategy. We also observe a clear knowledge scaling law, where larger models consistently extract more knowledge. In addition, we identify a Pass@1-versus-Pass@k trade-off: domain-specialized models achieve higher initial accuracy but degrade rapidly, while general-purpose models maintain stable performance during extended extraction. Finally, our results show that differences in training data composition lead to distinct and measurable knowledge profiles across model families.
Hierarchical Orthogonal Residual Spread for Precise Massive Editing in Large Language Models
Jan 16, 2026Large language models (LLMs) exhibit exceptional performance across various domains, yet they face critical safety concerns. Model editing has emerged as an effective approach to mitigate these issues. Existing model editing methods often focus on optimizing an information matrix that blends new and old knowledge. While effective, these approaches can be computationally expensive and may cause conflicts. In contrast, we shift our attention to Hierarchical Orthogonal Residual SprEad of the information matrix, which reduces noisy gradients and enables more stable edits from a different perspective. We demonstrate the effectiveness of our method HORSE through a clear theoretical comparison with several popular methods and extensive experiments conducted on two datasets across multiple LLMs. The results show that HORSE maintains precise massive editing across diverse scenarios. The code is available at https://github.com/XiaojieGu/HORSE
Skeleton-based Action Recognition with Non-linear Dependency Modeling and Hilbert-Schmidt Independence Criterion
Dec 25, 2024



Human skeleton-based action recognition has long been an indispensable aspect of artificial intelligence. Current state-of-the-art methods tend to consider only the dependencies between connected skeletal joints, limiting their ability to capture non-linear dependencies between physically distant joints. Moreover, most existing approaches distinguish action classes by estimating the probability density of motion representations, yet the high-dimensional nature of human motions invokes inherent difficulties in accomplishing such measurements. In this paper, we seek to tackle these challenges from two directions: (1) We propose a novel dependency refinement approach that explicitly models dependencies between any pair of joints, effectively transcending the limitations imposed by joint distance. (2) We further propose a framework that utilizes the Hilbert-Schmidt Independence Criterion to differentiate action classes without being affected by data dimensionality, and mathematically derive learning objectives guaranteeing precise recognition. Empirically, our approach sets the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120, and Northwestern-UCLA datasets.
Action Recognition with Multi-stream Motion Modeling and Mutual Information Maximization
Jun 13, 2023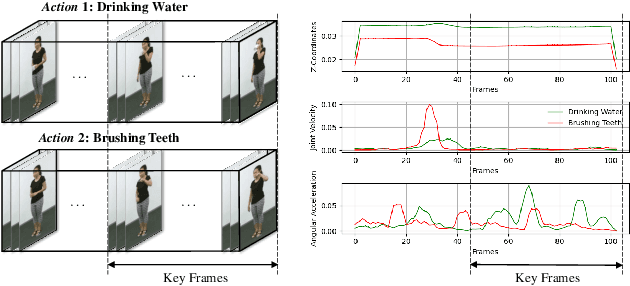
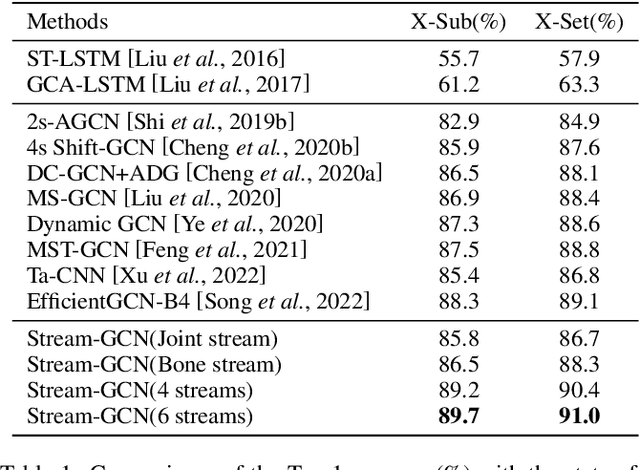
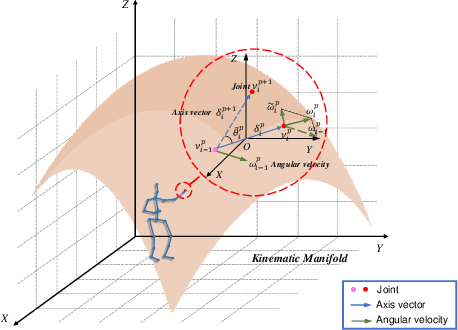
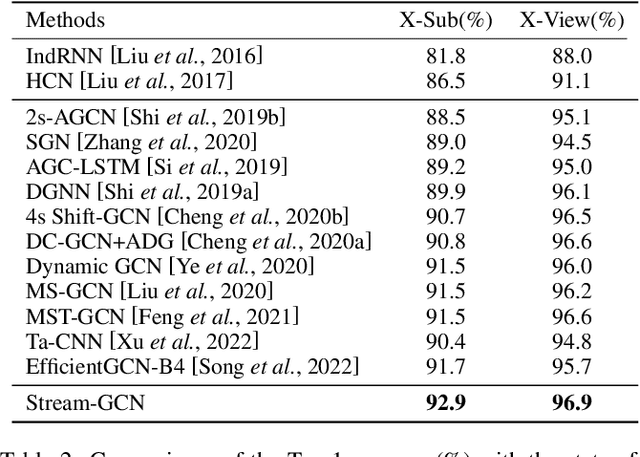
Action recognition has long been a fundamental and intriguing problem in artificial intelligence. The task is challenging due to the high dimensionality nature of an action, as well as the subtle motion details to be considered. Current state-of-the-art approaches typically learn from articulated motion sequences in the straightforward 3D Euclidean space. However, the vanilla Euclidean space is not efficient for modeling important motion characteristics such as the joint-wise angular acceleration, which reveals the driving force behind the motion. Moreover, current methods typically attend to each channel equally and lack theoretical constrains on extracting task-relevant features from the input. In this paper, we seek to tackle these challenges from three aspects: (1) We propose to incorporate an acceleration representation, explicitly modeling the higher-order variations in motion. (2) We introduce a novel Stream-GCN network equipped with multi-stream components and channel attention, where different representations (i.e., streams) supplement each other towards a more precise action recognition while attention capitalizes on those important channels. (3) We explore feature-level supervision for maximizing the extraction of task-relevant information and formulate this into a mutual information loss. Empirically, our approach sets the new state-of-the-art performance on three benchmark datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. Our code is anonymously released at https://github.com/ActionR-Group/Stream-GCN, hoping to inspire the community.