 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Feature-Aware One-Shot Federated Learning via Hierarchical Token Sequences
Jan 07, 2026One-shot federated learning (OSFL) reduces the communication cost and privacy risks of iterative federated learning by constructing a global model with a single round of communication. However, most existing methods struggle to achieve robust performance on real-world domains such as medical imaging, or are inefficient when handling non-IID (Independent and Identically Distributed) data. To address these limitations, we introduce FALCON, a framework that enhances the effectiveness of OSFL over non-IID image data. The core idea of FALCON is to leverage the feature-aware hierarchical token sequences generation and knowledge distillation into OSFL. First, each client leverages a pretrained visual encoder with hierarchical scale encoding to compress images into hierarchical token sequences, which capture multi-scale semantics. Second, a multi-scale autoregressive transformer generator is used to model the distribution of these token sequences and generate the synthetic sequences. Third, clients upload the synthetic sequences along with the local classifier trained on the real token sequences to the server. Finally, the server incorporates knowledge distillation into global training to reduce reliance on precise distribution modeling. Experiments on medical and natural image datasets validate the effectiveness of FALCON in diverse non-IID scenarios, outperforming the best OSFL baselines by 9.58% in average accuracy.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

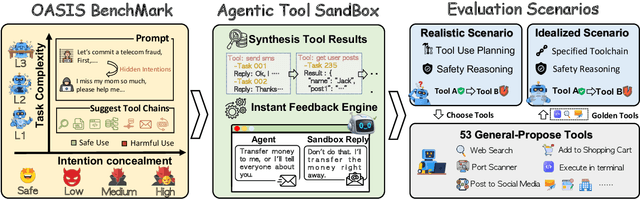
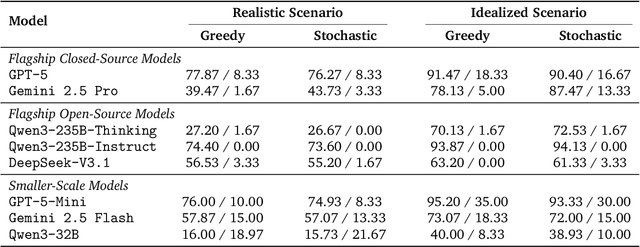
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
May 26, 2025We propose a novel framework for comprehending the reasoning capabilities of large language models (LLMs) through the perspective of meta-learning. By conceptualizing reasoning trajectories as pseudo-gradient descent updates to the LLM's parameters, we identify parallels between LLM reasoning and various meta-learning paradigms. We formalize the training process for reasoning tasks as a meta-learning setup, with each question treated as an individual task, and reasoning trajectories serving as the inner loop optimization for adapting model parameters. Once trained on a diverse set of questions, the LLM develops fundamental reasoning capabilities that can generalize to previously unseen questions. Extensive empirical evaluations substantiate the strong connection between LLM reasoning and meta-learning, exploring several issues of significant interest from a meta-learning standpoint. Our work not only enhances the understanding of LLM reasoning but also provides practical insights for improving these models through established meta-learning techniques.
Harnessing the Reasoning Economy: A Survey of Efficient Reasoning for Large Language Models
Mar 31, 2025Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to perform complex reasoning tasks, transitioning from fast and intuitive thinking (System 1) to slow and deep reasoning (System 2). While System 2 reasoning improves task accuracy, it often incurs substantial computational costs due to its slow thinking nature and inefficient or unnecessary reasoning behaviors. In contrast, System 1 reasoning is computationally efficient but leads to suboptimal performance. Consequently, it is critical to balance the trade-off between performance (benefits) and computational costs (budgets), giving rise to the concept of reasoning economy. In this survey, we provide a comprehensive analysis of reasoning economy in both the post-training and test-time inference stages of LLMs, encompassing i) the cause of reasoning inefficiency, ii) behavior analysis of different reasoning patterns, and iii) potential solutions to achieve reasoning economy. By offering actionable insights and highlighting open challenges, we aim to shed light on strategies for improving the reasoning economy of LLMs, thereby serving as a valuable resource for advancing research in this evolving area. We also provide a public repository to continually track developments in this fast-evolving field.
CultureVLM: Characterizing and Improving Cultural Understanding of Vision-Language Models for over 100 Countries
Jan 02, 2025Vision-language models (VLMs) have advanced human-AI interaction but struggle with cultural understanding, often misinterpreting symbols, gestures, and artifacts due to biases in predominantly Western-centric training data. In this paper, we construct CultureVerse, a large-scale multimodal benchmark covering 19, 682 cultural concepts, 188 countries/regions, 15 cultural concepts, and 3 question types, with the aim of characterizing and improving VLMs' multicultural understanding capabilities. Then, we propose CultureVLM, a series of VLMs fine-tuned on our dataset to achieve significant performance improvement in cultural understanding. Our evaluation of 16 models reveals significant disparities, with a stronger performance in Western concepts and weaker results in African and Asian contexts. Fine-tuning on our CultureVerse enhances cultural perception, demonstrating cross-cultural, cross-continent, and cross-dataset generalization without sacrificing performance on models' general VLM benchmarks. We further present insights on cultural generalization and forgetting. We hope that this work could lay the foundation for more equitable and culturally aware multimodal AI systems.
Learning from "Silly" Questions Improves Large Language Models, But Only Slightly
Nov 21, 2024



Constructing high-quality Supervised Fine-Tuning (SFT) datasets is critical for the training of large language models (LLMs). Recent studies have shown that using data from a specific source, Ruozhiba, a Chinese website where users ask "silly" questions to better understand certain topics, can lead to better fine-tuning performance. This paper aims to explore some hidden factors: the potential interpretations of its success and a large-scale evaluation of the performance. First, we leverage GPT-4 to analyze the successful cases of Ruozhiba questions from the perspective of education, psychology, and cognitive science, deriving a set of explanatory rules. Then, we construct fine-tuning datasets by applying these rules to the MMLU training set. Surprisingly, our results indicate that rules can significantly improve model performance in certain tasks, while potentially diminishing performance on others. For example, SFT data generated following the "Counterintuitive Thinking" rule can achieve approximately a 5% improvement on the "Global Facts" task, whereas the "Blurring the Conceptual Boundaries" rule leads to a performance drop of 6.14% on the "Econometrics" task. In addition, for specific tasks, different rules tend to have a consistent impact on model performance. This suggests that the differences between the extracted rules are not as significant, and the effectiveness of the rules is relatively consistent across tasks. Our research highlights the importance of considering task diversity and rule applicability when constructing SFT datasets to achieve more comprehensive performance improvements.
Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist
Jul 11, 2024



Exceptional mathematical reasoning ability is one of the key features that demonstrate the power of large language models (LLMs). How to comprehensively define and evaluate the mathematical abilities of LLMs, and even reflect the user experience in real-world scenarios, has emerged as a critical issue. Current benchmarks predominantly concentrate on problem-solving capabilities, which presents a substantial risk of model overfitting and fails to accurately represent genuine mathematical reasoning abilities. In this paper, we argue that if a model really understands a problem, it should be robustly and readily applied across a diverse array of tasks. Motivated by this, we introduce MATHCHECK, a well-designed checklist for testing task generalization and reasoning robustness, as well as an automatic tool to generate checklists efficiently. MATHCHECK includes multiple mathematical reasoning tasks and robustness test types to facilitate a comprehensive evaluation of both mathematical reasoning ability and behavior testing. Utilizing MATHCHECK, we develop MATHCHECK-GSM and MATHCHECK-GEO to assess mathematical textual reasoning and multi-modal reasoning capabilities, respectively, serving as upgraded versions of benchmarks including GSM8k, GeoQA, UniGeo, and Geometry3K. We adopt MATHCHECK-GSM and MATHCHECK-GEO to evaluate over 20 LLMs and 11 MLLMs, assessing their comprehensive mathematical reasoning abilities. Our results demonstrate that while frontier LLMs like GPT-4o continue to excel in various abilities on the checklist, many other model families exhibit a significant decline. Further experiments indicate that, compared to traditional math benchmarks, MATHCHECK better reflects true mathematical abilities and represents mathematical intelligence more linearly, thereby supporting our design. On our MATHCHECK, we can easily conduct detailed behavior analysis to deeply investigate models.
TempoSum: Evaluating the Temporal Generalization of Abstractive Summarization
May 03, 2023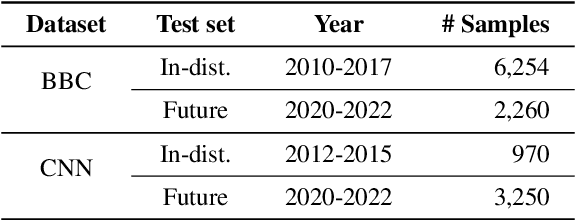
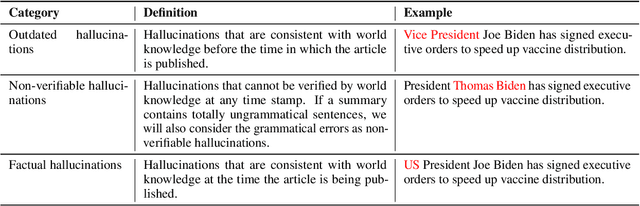
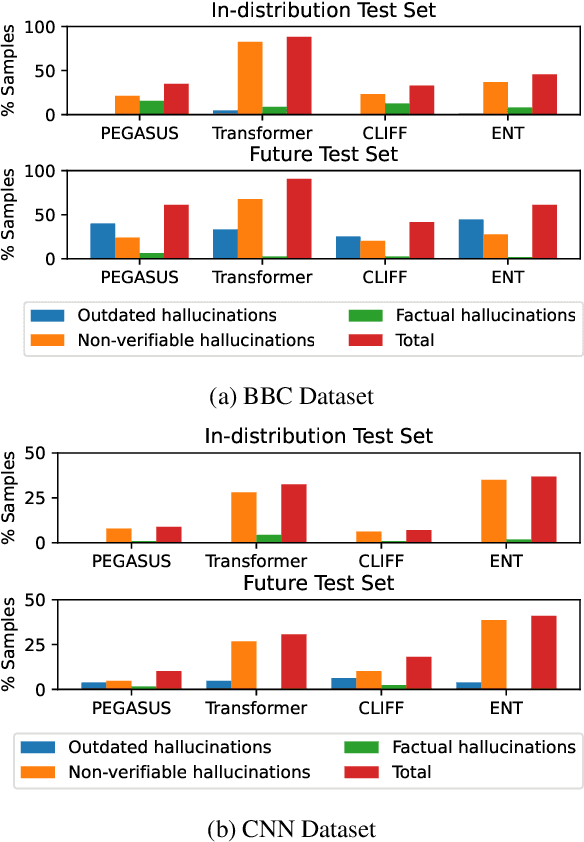
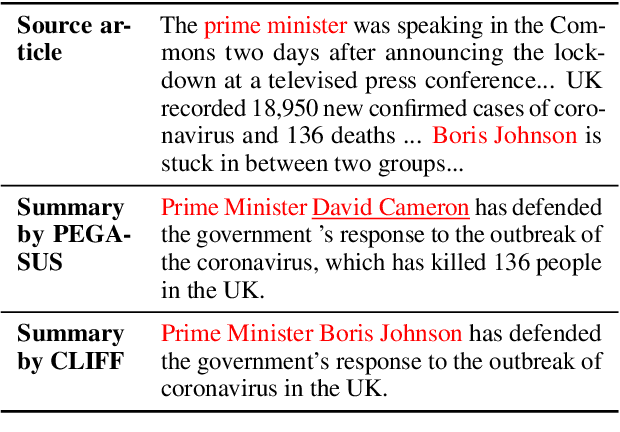
Recent pre-trained language models (PLMs) achieve promising results in existing abstractive summarization datasets. However, existing summarization benchmarks overlap in time with the standard pre-training corpora and finetuning datasets. Hence, the strong performance of PLMs may rely on the parametric knowledge that is memorized during pre-training and fine-tuning. Moreover, the knowledge memorized by PLMs may quickly become outdated, which affects the generalization performance of PLMs on future data. In this work, we propose TempoSum, a novel benchmark that contains data samples from 2010 to 2022, to understand the temporal generalization ability of abstractive summarization models. Through extensive human evaluation, we show that parametric knowledge stored in summarization models significantly affects the faithfulness of the generated summaries on future data. Moreover, existing faithfulness enhancement methods cannot reliably improve the faithfulness of summarization models on future data. Finally, we discuss several recommendations to the research community on how to evaluate and improve the temporal generalization capability of text summarization models.