 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing the Cracks: Vulnerabilities of Retrieval-Augmented LLM-based Machine Translation
Oct 01, 2025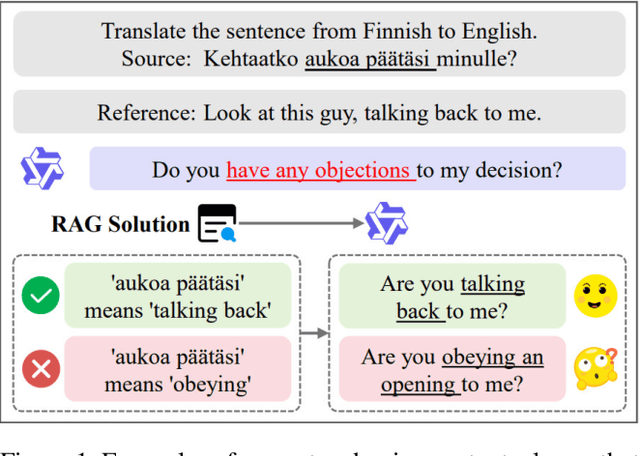

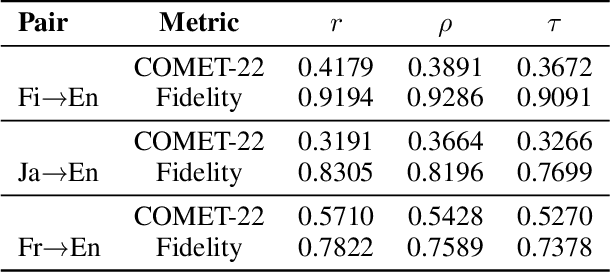
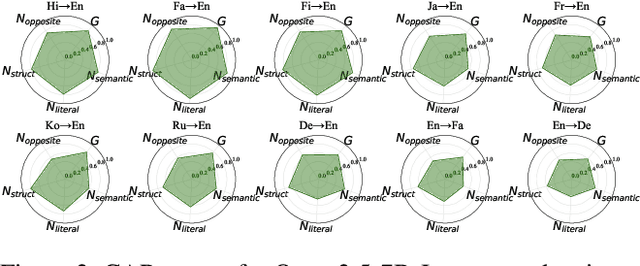
\textbf{RE}trieval-\textbf{A}ugmented \textbf{L}LM-based \textbf{M}achine \textbf{T}ranslation (REAL-MT) shows promise for knowledge-intensive tasks like idiomatic translation, but its reliability under noisy retrieval contexts remains poorly understood despite this being a common challenge in real-world deployment. To address this gap, we propose a noise synthesis framework and new metrics to evaluate the robustness of REAL-MT systematically. Using this framework, we instantiate REAL-MT with Qwen-series models, including standard LLMs and large reasoning models (LRMs) with enhanced reasoning, and evaluate their performance on idiomatic translation across high-, medium-, and low-resource language pairs under synthesized noise. Our results show that low-resource language pairs, which rely more heavily on retrieved context, degrade more severely under noise than high-resource ones and often produce nonsensical translations. Although LRMs possess enhanced reasoning capabilities, they show no improvement in error correction and are even more susceptible to noise, tending to rationalize incorrect contexts. We find that this stems from an attention shift away from the source idiom to noisy content, while confidence increases despite declining accuracy, indicating poor calibration. To mitigate these issues, we investigate training-free and fine-tuning strategies, which improve robustness at the cost of performance in clean contexts, revealing a fundamental trade-off. Our findings highlight the limitations of current approaches, underscoring the need for self-verifying integration mechanisms.
TempoSum: Evaluating the Temporal Generalization of Abstractive Summarization
May 03, 2023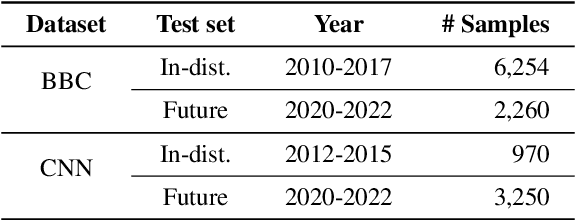
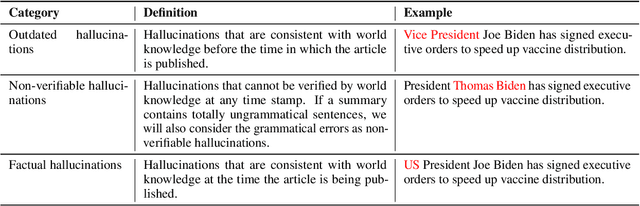
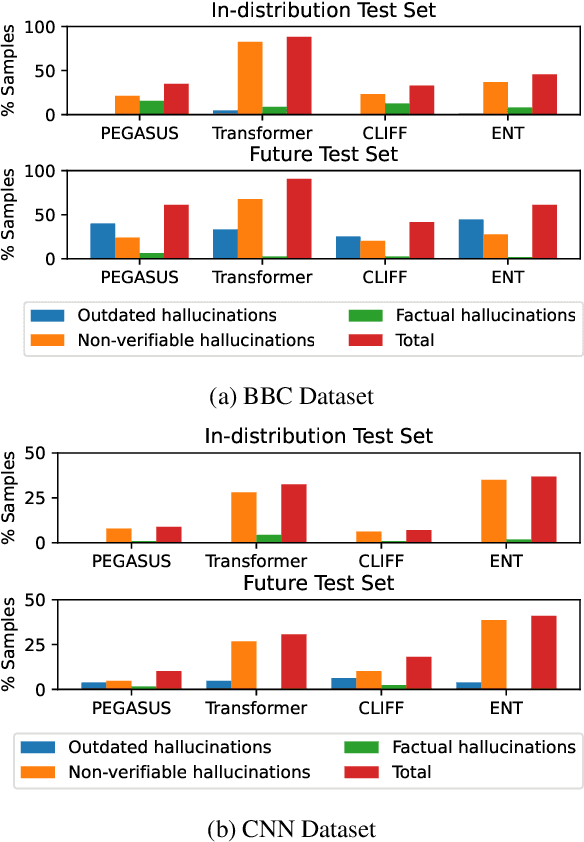
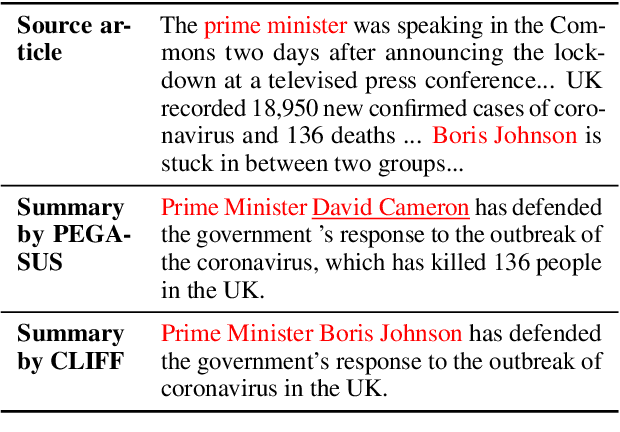
Recent pre-trained language models (PLMs) achieve promising results in existing abstractive summarization datasets. However, existing summarization benchmarks overlap in time with the standard pre-training corpora and finetuning datasets. Hence, the strong performance of PLMs may rely on the parametric knowledge that is memorized during pre-training and fine-tuning. Moreover, the knowledge memorized by PLMs may quickly become outdated, which affects the generalization performance of PLMs on future data. In this work, we propose TempoSum, a novel benchmark that contains data samples from 2010 to 2022, to understand the temporal generalization ability of abstractive summarization models. Through extensive human evaluation, we show that parametric knowledge stored in summarization models significantly affects the faithfulness of the generated summaries on future data. Moreover, existing faithfulness enhancement methods cannot reliably improve the faithfulness of summarization models on future data. Finally, we discuss several recommendations to the research community on how to evaluate and improve the temporal generalization capability of text summarization models.