 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWAP: Symmetric Equivariant World-Model for Agile Robot Parkour
Jun 18, 2026While latent world models enable the proactive predictions required for extreme parkour, their purely data-driven nature forces them to redundantly encode left-right symmetric interactions as independent patterns. This inflates the learning burden and hinders the capture of geometric regularities, restricting the latent space's efficiency for downstream policies. To address this, we propose SWAP, an end-to-end equivariant symmetric world model. This framework embeds symmetry directly into both the world model and the actor-critic networks. In real-world tests, the robot leaps across a 2.13 m gap and climbs a 1.63 m platform, breaking records for quadruped parkour. Furthermore, the framework exhibits robust geometric generalization to unseen mirrored terrains and exceptional zero-shot transferability across diverse outdoor environments. These results demonstrate that symmetry equivariance is an effective structural prior for pushing the physical boundaries of learned legged locomotion.
From Texts to Scores: Tracing the Emergence of Essay Quality Representations in Large Language Models
Jun 18, 2026Recent advances in Large Language Models (LLMs) have substantially transformed Automated Essay Scoring (AES), yet the internal mechanisms underlying LLM-based scoring remain poorly understood. In this work, we systematically analyze the hidden representations of eight LLMs across two English essay datasets (ASAP++, CSEE) and one Portuguese dataset (ENEM). Using linear probing, cross-prompt generalization, dimensionality reduction, and neuron-level analyses, we find consistent evidence that essay quality information is encoded in a linearly accessible form within LLM representations. These representations emerge progressively across layers, remain robust across prompting strategies, and partially transfer across essay prompts despite differences in scoring rubrics. In addition, nonlinear probes provide only marginal and inconsistent improvements over linear probes, suggesting that most essay quality information is already linearly decodable. We further identify individual ``essay scoring neurons'' whose activations strongly correlate with essay scores and whose behavior is sensitive to targeted intervention. Moreover, the layer-wise distribution of these neurons systematically shifts with essay length, with longer essays relying more heavily on deeper layers. Overall, our findings provide evidence that LLMs encode structured representations related to essay quality and offer new insights into the interpretability of LLM-based AES systems.
MC-PDD: Masked Corpus-Level Pretraining Data Detection for Black-Box Large Language Models
Jun 06, 2026Pretraining is fundamental to the development of Large Language Models (LLMs), yet the opacity of pretraining data complicates model analysis and raises ethical, legal, and fairness concerns. Detecting whether specific datasets were used during pretraining is, therefore, critical. Existing state-of-the-art methods typically rely on access to model probability distributions, making them unsuitable for closed-source LLMs that provide only input-output interfaces. To address this limitation, we introduce Masked Corpus-level Pretraining Data Detection (MC-PDD), a novel method inspired by the masked language modeling paradigm. MC-PDD masks highly specific tokens in each text and prompts the LLM to predict the missing content. It then assesses whether the difference in prediction hit rates between a candidate corpus and a reference non-member corpus is statistically significant. Based on this comparison, MC-PDD determines whether the candidate texts were likely included in the model's pretraining data. Experimental results demonstrate clear and consistent differences in prediction hit rates between pretrained and unseen data across three datasets, for both open-source and closed-source LLMs. Despite operating under a stricter black-box setting, MC-PDD achieves performance comparable to existing detection methods. Our approach enables practical applications such as model auditing and data copyright verification using only standard API access. Upon acceptance, we will publicly release the code and datasets.
Worlds Within Words: Translating Culture in Ancient Chinese Texts with Multi-Agent Coordination
May 31, 2026Large language model (LLM)-based machine translation has advanced cross-cultural communication, yet it still struggles with culture-loaded words (CLWs) in ancient Chinese texts. The challenge extends beyond lexical alignment to deciding when and how culture-dependent knowledge should be explicated for readers lacking relevant background. Literal translation often preserves surface forms while missing underlying concepts, whereas over-explicitation harms conciseness and readability. To address this problem, we formulate CLW translation as a selective explicitation task and propose \textbf{MACAT}, a \textbf{M}ulti-\textbf{A}gent \textbf{C}ulture-\textbf{A}ware \textbf{T}ranslation framework that dynamically identifies culturally salient phrases and injects concise explanatory knowledge when necessary. MACAT further incorporates a quality-aware reranking module for candidate selection and a multi-round evaluation agent that assesses translations across terminological precision, readability, fidelity, cultural preservation, and cultural explicitation. Experiments on traditional Chinese medicine (TCM) classics and the \textit{Analects} show that, under a unified GPT-5.4 evaluation setting, MACAT consistently outperforms both the backbone model and general-purpose MT baselines on 100 TCM documents and a 20-chapter subset of the \textit{Analects}.
Exposing the Cracks: Vulnerabilities of Retrieval-Augmented LLM-based Machine Translation
Oct 01, 2025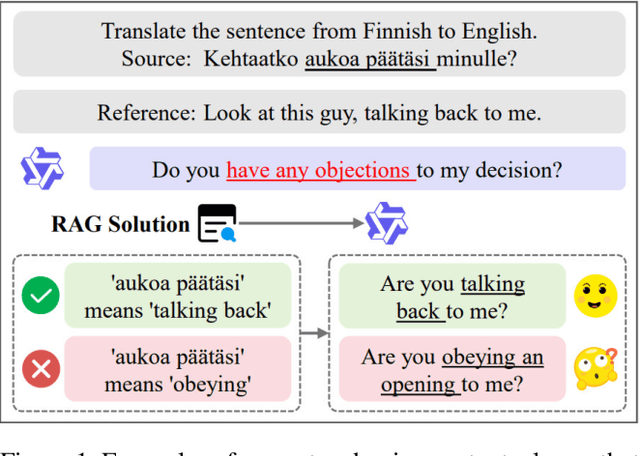

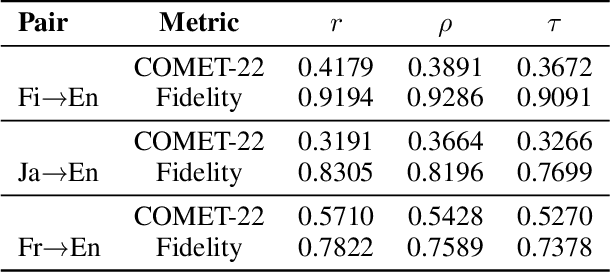
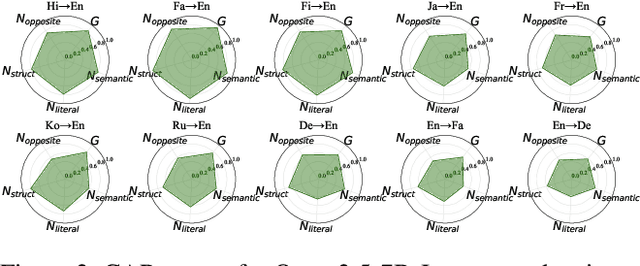
\textbf{RE}trieval-\textbf{A}ugmented \textbf{L}LM-based \textbf{M}achine \textbf{T}ranslation (REAL-MT) shows promise for knowledge-intensive tasks like idiomatic translation, but its reliability under noisy retrieval contexts remains poorly understood despite this being a common challenge in real-world deployment. To address this gap, we propose a noise synthesis framework and new metrics to evaluate the robustness of REAL-MT systematically. Using this framework, we instantiate REAL-MT with Qwen-series models, including standard LLMs and large reasoning models (LRMs) with enhanced reasoning, and evaluate their performance on idiomatic translation across high-, medium-, and low-resource language pairs under synthesized noise. Our results show that low-resource language pairs, which rely more heavily on retrieved context, degrade more severely under noise than high-resource ones and often produce nonsensical translations. Although LRMs possess enhanced reasoning capabilities, they show no improvement in error correction and are even more susceptible to noise, tending to rationalize incorrect contexts. We find that this stems from an attention shift away from the source idiom to noisy content, while confidence increases despite declining accuracy, indicating poor calibration. To mitigate these issues, we investigate training-free and fine-tuning strategies, which improve robustness at the cost of performance in clean contexts, revealing a fundamental trade-off. Our findings highlight the limitations of current approaches, underscoring the need for self-verifying integration mechanisms.
FOCUS: Forging Originality through Contrastive Use in Self-Plagiarism for Language Models
Jun 02, 2024Pre-trained Language Models (PLMs) have shown impressive results in various Natural Language Generation (NLG) tasks, such as powering chatbots and generating stories. However, an ethical concern arises due to their potential to produce verbatim copies of paragraphs from their training data. This is problematic as PLMs are trained on corpora constructed by human authors. As such, there is a pressing need for research to promote the generation of original content by these models. In this study, we introduce a unique "self-plagiarism" contrastive decoding strategy, aimed at boosting the originality of text produced by PLMs. Our method entails modifying prompts in LLMs to develop an amateur model and a professional model. Specifically, the amateur model is urged to plagiarize using three plagiarism templates we have designed, while the professional model maintains its standard language model status. This strategy employs prompts to stimulate the model's capacity to identify non-original candidate token combinations and subsequently impose penalties. The application of this strategy is integrated prior to the model's final layer, ensuring smooth integration with most existing PLMs (T5, GPT, LLaMA) without necessitating further adjustments. Implementing our strategy, we observe a significant decline in non-original sequences comprised of more than three words in the academic AASC dataset and the story-based ROCStories dataset.
Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation
Apr 04, 2023ChatGPT, a large-scale language model based on the advanced GPT-3.5 architecture, has shown remarkable potential in various Natural Language Processing (NLP) tasks. However, there is currently a dearth of comprehensive study exploring its potential in the area of Grammatical Error Correction (GEC). To showcase its capabilities in GEC, we design zero-shot chain-of-thought (CoT) and few-shot CoT settings using in-context learning for ChatGPT. Our evaluation involves assessing ChatGPT's performance on five official test sets in three different languages, along with three document-level GEC test sets in English. Our experimental results and human evaluations demonstrate that ChatGPT has excellent error detection capabilities and can freely correct errors to make the corrected sentences very fluent, possibly due to its over-correction tendencies and not adhering to the principle of minimal edits. Additionally, its performance in non-English and low-resource settings highlights its potential in multilingual GEC tasks. However, further analysis of various types of errors at the document-level has shown that ChatGPT cannot effectively correct agreement, coreference, tense errors across sentences, and cross-sentence boundary errors.