 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgri-R1: Empowering Generalizable Agricultural Reasoning in Vision-Language Models with Reinforcement Learning
Jan 08, 2026Agricultural disease diagnosis challenges VLMs, as conventional fine-tuning requires extensive labels, lacks interpretability, and generalizes poorly. While reasoning improves model robustness, existing methods rely on costly expert annotations and rarely address the open-ended, diverse nature of agricultural queries. To address these limitations, we propose \textbf{Agri-R1}, a reasoning-enhanced large model for agriculture. Our framework automates high-quality reasoning data generation via vision-language synthesis and LLM-based filtering, using only 19\% of available samples. Training employs Group Relative Policy Optimization (GRPO) with a novel proposed reward function that integrates domain-specific lexicons and fuzzy matching to assess both correctness and linguistic flexibility in open-ended responses. Evaluated on CDDMBench, our resulting 3B-parameter model achieves performance competitive with 7B- to 13B-parameter baselines, showing a +23.2\% relative gain in disease recognition accuracy, +33.3\% in agricultural knowledge QA, and a +26.10-point improvement in cross-domain generalization over standard fine-tuning. Ablation studies confirm that the synergy between structured reasoning data and GRPO-driven exploration underpins these gains, with benefits scaling as question complexity increases.
CPJ: Explainable Agricultural Pest Diagnosis via Caption-Prompt-Judge with LLM-Judged Refinement
Dec 31, 2025Accurate and interpretable crop disease diagnosis is essential for agricultural decision-making, yet existing methods often rely on costly supervised fine-tuning and perform poorly under domain shifts. We propose Caption--Prompt--Judge (CPJ), a training-free few-shot framework that enhances Agri-Pest VQA through structured, interpretable image captions. CPJ employs large vision-language models to generate multi-angle captions, refined iteratively via an LLM-as-Judge module, which then inform a dual-answer VQA process for both recognition and management responses. Evaluated on CDDMBench, CPJ significantly improves performance: using GPT-5-mini captions, GPT-5-Nano achieves \textbf{+22.7} pp in disease classification and \textbf{+19.5} points in QA score over no-caption baselines. The framework provides transparent, evidence-based reasoning, advancing robust and explainable agricultural diagnosis without fine-tuning. Our code and data are publicly available at: https://github.com/CPJ-Agricultural/CPJ-Agricultural-Diagnosis.
Dream3DAvatar: Text-Controlled 3D Avatar Reconstruction from a Single Image
Sep 16, 2025
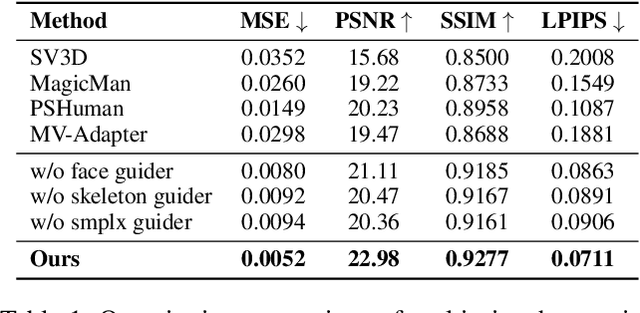
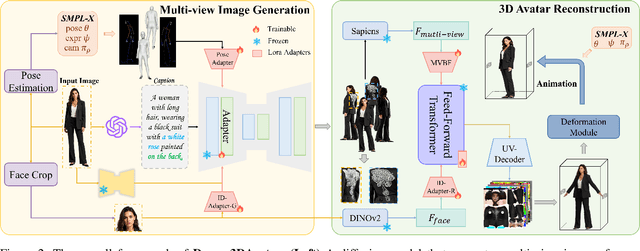
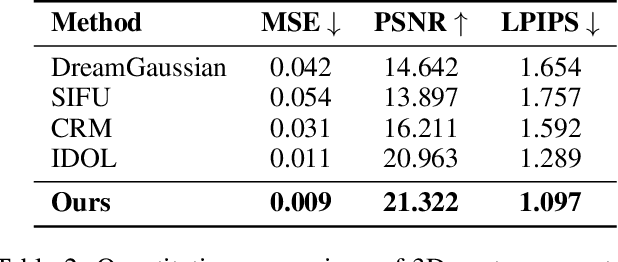
With the rapid advancement of 3D representation techniques and generative models, substantial progress has been made in reconstructing full-body 3D avatars from a single image. However, this task remains fundamentally ill-posedness due to the limited information available from monocular input, making it difficult to control the geometry and texture of occluded regions during generation. To address these challenges, we redesign the reconstruction pipeline and propose Dream3DAvatar, an efficient and text-controllable two-stage framework for 3D avatar generation. In the first stage, we develop a lightweight, adapter-enhanced multi-view generation model. Specifically, we introduce the Pose-Adapter to inject SMPL-X renderings and skeletal information into SDXL, enforcing geometric and pose consistency across views. To preserve facial identity, we incorporate ID-Adapter-G, which injects high-resolution facial features into the generation process. Additionally, we leverage BLIP2 to generate high-quality textual descriptions of the multi-view images, enhancing text-driven controllability in occluded regions. In the second stage, we design a feedforward Transformer model equipped with a multi-view feature fusion module to reconstruct high-fidelity 3D Gaussian Splat representations (3DGS) from the generated images. Furthermore, we introduce ID-Adapter-R, which utilizes a gating mechanism to effectively fuse facial features into the reconstruction process, improving high-frequency detail recovery. Extensive experiments demonstrate that our method can generate realistic, animation-ready 3D avatars without any post-processing and consistently outperforms existing baselines across multiple evaluation metrics.
Reasoning or Not? A Comprehensive Evaluation of Reasoning LLMs for Dialogue Summarization
Jul 02, 2025



Dialogue summarization is a challenging task with significant practical value in customer service, meeting analysis, and conversational AI. Although large language models (LLMs) have achieved substantial progress in summarization tasks, the performance of step-by-step reasoning architectures-specifically Long Chain-of-Thought (CoT) implementations such as OpenAI-o1 and DeepSeek-R1-remains unexplored for dialogue scenarios requiring concurrent abstraction and conciseness. In this work, we present the first comprehensive and systematic evaluation of state-of-the-art reasoning LLMs and non-reasoning LLMs across three major paradigms-generic, role-oriented, and query-oriented dialogue summarization. Our study spans diverse languages, domains, and summary lengths, leveraging strong benchmarks (SAMSum, DialogSum, CSDS, and QMSum) and advanced evaluation protocols that include both LLM-based automatic metrics and human-inspired criteria. Contrary to trends in other reasoning-intensive tasks, our findings show that explicit stepwise reasoning does not consistently improve dialogue summarization quality. Instead, reasoning LLMs are often prone to verbosity, factual inconsistencies, and less concise summaries compared to their non-reasoning counterparts. Through scenario-specific analyses and detailed case studies, we further identify when and why explicit reasoning may fail to benefit-or even hinder-summarization in complex dialogue contexts. Our work provides new insights into the limitations of current reasoning LLMs and highlights the need for targeted modeling and evaluation strategies for real-world dialogue summarization.
A Real-time and Hardware Efficient Artfecat-free Spike Sorting Using Deep Spike Detection
Apr 19, 2025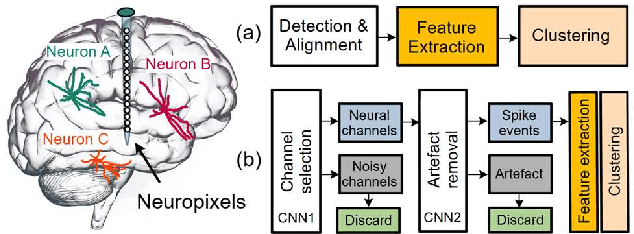
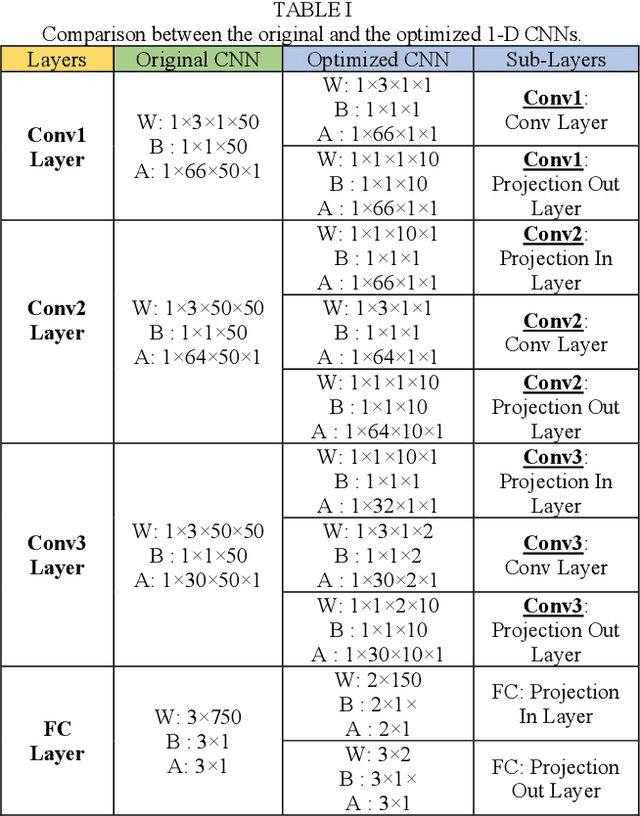


Spike sorting is a valuable tool in understanding brain regions. It assigns detected spike waveforms to their origins, helping to research the mechanism of the human brain and the development of implantable brain-machine interfaces (iBMIs). The presence of noise and artefacts will adversely affect the efficacy of spike sorting. This paper proposes a framework for low-cost and real-time implementation of deep spike detection, which consists of two one-dimensional (1-D) convolutional neural network (CNN) model for channel selection and artefact removal. The framework utilizes simulation and hardware layers, and it applies several low-power techniques to optimise the implementation cost of a 1-D CNN model. A compact CNN model with 210 bytes memory size is achieved using structured pruning, network projection and quantization in the simulation layer. The hardware layer also accommodates various techniques including a customized multiply-accumulate (MAC) engine, novel fused layers in the convolution pipeline and proposing flexible resource allocation for a power-efficient and low-delay design. The optimized 1-D CNN significantly decreases both computational complexity and model size, with only a minimal reduction in accuracy. Classification of 1-D CNN on the Cyclone V 5CSEMA5F31C6 FPGA evaluation platform is accomplished in just 16.8 microseconds at a frequency of 2.5 MHz. The FPGA prototype achieves an accuracy rate of 97.14% on a standard dataset and operates with a power consumption of 2.67mW from a supply voltage of 1.1 volts. An accuracy of 95.05% is achieved with a power of 5.6mW when deep spike detection is implemented using two optimized 1-D CNNs on an FPGA board.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
LLMCL-GEC: Advancing Grammatical Error Correction with LLM-Driven Curriculum Learning
Dec 17, 2024While large-scale language models (LLMs) have demonstrated remarkable capabilities in specific natural language processing (NLP) tasks, they may still lack proficiency compared to specialized models in certain domains, such as grammatical error correction (GEC). Drawing inspiration from the concept of curriculum learning, we have delved into refining LLMs into proficient GEC experts by devising effective curriculum learning (CL) strategies. In this paper, we introduce a novel approach, termed LLM-based curriculum learning, which capitalizes on the robust semantic comprehension and discriminative prowess inherent in LLMs to gauge the complexity of GEC training data. Unlike traditional curriculum learning techniques, our method closely mirrors human expert-designed curriculums. Leveraging the proposed LLM-based CL method, we sequentially select varying levels of curriculums ranging from easy to hard, and iteratively train and refine using the pretrianed T5 and LLaMA series models. Through rigorous testing and analysis across diverse benchmark assessments in English GEC, including the CoNLL14 test, BEA19 test, and BEA19 development sets, our approach showcases a significant performance boost over baseline models and conventional curriculum learning methodologies.
FOCUS: Forging Originality through Contrastive Use in Self-Plagiarism for Language Models
Jun 02, 2024Pre-trained Language Models (PLMs) have shown impressive results in various Natural Language Generation (NLG) tasks, such as powering chatbots and generating stories. However, an ethical concern arises due to their potential to produce verbatim copies of paragraphs from their training data. This is problematic as PLMs are trained on corpora constructed by human authors. As such, there is a pressing need for research to promote the generation of original content by these models. In this study, we introduce a unique "self-plagiarism" contrastive decoding strategy, aimed at boosting the originality of text produced by PLMs. Our method entails modifying prompts in LLMs to develop an amateur model and a professional model. Specifically, the amateur model is urged to plagiarize using three plagiarism templates we have designed, while the professional model maintains its standard language model status. This strategy employs prompts to stimulate the model's capacity to identify non-original candidate token combinations and subsequently impose penalties. The application of this strategy is integrated prior to the model's final layer, ensuring smooth integration with most existing PLMs (T5, GPT, LLaMA) without necessitating further adjustments. Implementing our strategy, we observe a significant decline in non-original sequences comprised of more than three words in the academic AASC dataset and the story-based ROCStories dataset.
Multi-Task Instruction Tuning of LLaMa for Specific Scenarios: A Preliminary Study on Writing Assistance
May 22, 2023ChatGPT and GPT-4 have attracted substantial interest from both academic and industrial circles, owing to their remarkable few-shot (or even zero-shot) ability to handle various tasks. Recent work shows that, after being fine-tuned with a few sets of instruction-driven data, the recently proposed LLM, LLaMa, exhibits an impressive capability to address a broad range of tasks. However, the zero-shot performance of LLMs does not consistently outperform that of models fined-tuned for specific scenarios. To explore whether the capabilities of LLMs can be further enhanced for specific scenarios, we choose the writing-assistance scenario as the testbed, including seven writing tasks. We collect training data for these tasks, reframe them in an instruction-following format, and subsequently refine LLaMa via instruction tuning. Experimental results show that continually fine-tuning LLaMa on writing instruction data significantly improves its ability on writing tasks. We also conduct more experiments and analyses to offer insights for future work on effectively fine-tuning LLaMa for specific scenarios.
Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation
Apr 04, 2023ChatGPT, a large-scale language model based on the advanced GPT-3.5 architecture, has shown remarkable potential in various Natural Language Processing (NLP) tasks. However, there is currently a dearth of comprehensive study exploring its potential in the area of Grammatical Error Correction (GEC). To showcase its capabilities in GEC, we design zero-shot chain-of-thought (CoT) and few-shot CoT settings using in-context learning for ChatGPT. Our evaluation involves assessing ChatGPT's performance on five official test sets in three different languages, along with three document-level GEC test sets in English. Our experimental results and human evaluations demonstrate that ChatGPT has excellent error detection capabilities and can freely correct errors to make the corrected sentences very fluent, possibly due to its over-correction tendencies and not adhering to the principle of minimal edits. Additionally, its performance in non-English and low-resource settings highlights its potential in multilingual GEC tasks. However, further analysis of various types of errors at the document-level has shown that ChatGPT cannot effectively correct agreement, coreference, tense errors across sentences, and cross-sentence boundary errors.