 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOMURA: Taming the Sand-Glass for Time-Constrained LLM Translation via Reinforcement Learning
Jan 15, 2026Large Language Models (LLMs) have achieved remarkable strides in multilingual translation but are hindered by a systemic cross-lingual verbosity bias, rendering them unsuitable for strict time-constrained tasks like subtitling and dubbing. Current prompt-engineering approaches struggle to resolve this conflict between semantic fidelity and rigid temporal feasibility. To bridge this gap, we first introduce Sand-Glass, a benchmark specifically designed to evaluate translation under syllable-level duration constraints. Furthermore, we propose HOMURA, a reinforcement learning framework that explicitly optimizes the trade-off between semantic preservation and temporal compliance. By employing a KL-regularized objective with a novel dynamic syllable-ratio reward, HOMURA effectively "tames" the output length. Experimental results demonstrate that our method significantly outperforms strong LLM baselines, achieving precise length control that respects linguistic density hierarchies without compromising semantic adequacy.
LLMCL-GEC: Advancing Grammatical Error Correction with LLM-Driven Curriculum Learning
Dec 17, 2024While large-scale language models (LLMs) have demonstrated remarkable capabilities in specific natural language processing (NLP) tasks, they may still lack proficiency compared to specialized models in certain domains, such as grammatical error correction (GEC). Drawing inspiration from the concept of curriculum learning, we have delved into refining LLMs into proficient GEC experts by devising effective curriculum learning (CL) strategies. In this paper, we introduce a novel approach, termed LLM-based curriculum learning, which capitalizes on the robust semantic comprehension and discriminative prowess inherent in LLMs to gauge the complexity of GEC training data. Unlike traditional curriculum learning techniques, our method closely mirrors human expert-designed curriculums. Leveraging the proposed LLM-based CL method, we sequentially select varying levels of curriculums ranging from easy to hard, and iteratively train and refine using the pretrianed T5 and LLaMA series models. Through rigorous testing and analysis across diverse benchmark assessments in English GEC, including the CoNLL14 test, BEA19 test, and BEA19 development sets, our approach showcases a significant performance boost over baseline models and conventional curriculum learning methodologies.
LICHEE: Improving Language Model Pre-training with Multi-grained Tokenization
Aug 03, 2021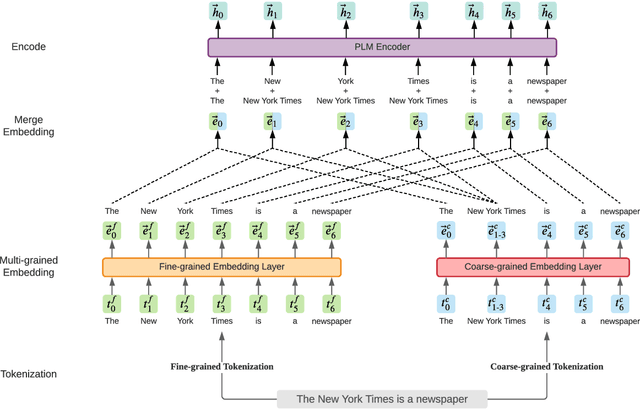
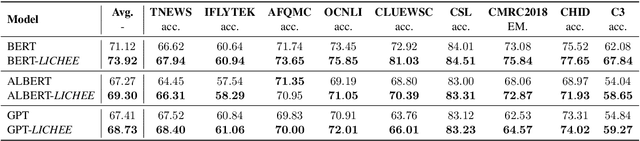
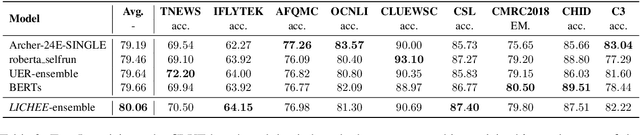
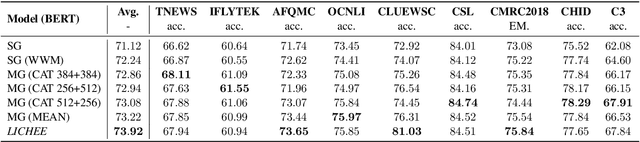
Language model pre-training based on large corpora has achieved tremendous success in terms of constructing enriched contextual representations and has led to significant performance gains on a diverse range of Natural Language Understanding (NLU) tasks. Despite the success, most current pre-trained language models, such as BERT, are trained based on single-grained tokenization, usually with fine-grained characters or sub-words, making it hard for them to learn the precise meaning of coarse-grained words and phrases. In this paper, we propose a simple yet effective pre-training method named LICHEE to efficiently incorporate multi-grained information of input text. Our method can be applied to various pre-trained language models and improve their representation capability. Extensive experiments conducted on CLUE and SuperGLUE demonstrate that our method achieves comprehensive improvements on a wide variety of NLU tasks in both Chinese and English with little extra inference cost incurred, and that our best ensemble model achieves the state-of-the-art performance on CLUE benchmark competition.