 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Symbolic Superoptimization of Tensor Programs
Apr 16, 2026This paper presents Prism, the first symbolic superoptimizer for tensor programs. The key idea is sGraph, a symbolic, hierarchical representation that compactly encodes large classes of tensor programs by symbolically representing some execution parameters. Prism organizes optimization as a two-level search: it constructs symbolic graphs that represent families of programs, and then instantiates them into concrete implementations. This formulation enables structured pruning of provably suboptimal regions of the search space using symbolic reasoning over operator semantics, algebraic identities, and hardware constraints. We develop techniques for efficient symbolic graph generation, equivalence verification via e-graph rewriting, and parameter instantiation through auto-tuning. Together, these components allow Prism to bridge the rigor of exhaustive search with the scalability required for modern ML workloads. Evaluation on five commonly used LLM workloads shows that Prism achieves up to $2.2\times$ speedup over best superoptimizers and $4.9\times$ over best compiler-based approaches, while reducing end-to-end optimization time by up to $3.4\times$.
Slack More, Predict Better: Proximal Relaxation for Probabilistic Latent Variable Model-based Soft Sensors
Mar 12, 2026Nonlinear Probabilistic Latent Variable Models (NPLVMs) are a cornerstone of soft sensor modeling due to their capacity for uncertainty delineation. However, conventional NPLVMs are trained using amortized variational inference, where neural networks parameterize the variational posterior. While facilitating model implementation, this parameterization converts the distributional optimization problem within an infinite-dimensional function space to parameter optimization within a finite-dimensional parameter space, which introduces an approximation error gap, thereby degrading soft sensor modeling accuracy. To alleviate this issue, we introduce KProxNPLVM, a novel NPLVM that pivots to relaxing the objective itself and improving the NPLVM's performance. Specifically, we first prove the approximation error induced by the conventional approach. Based on this, we design the Wasserstein distance as the proximal operator to relax the learning objective, yielding a new variational inference strategy derived from solving this relaxed optimization problem. Based on this foundation, we provide a rigorous derivation of KProxNPLVM's optimization implementation, prove the convergence of our algorithm can finally sidestep the approximation error, and propose the KProxNPLVM by summarizing the abovementioned content. Finally, extensive experiments on synthetic and real-world industrial datasets are conducted to demonstrate the efficacy of the proposed KProxNPLVM.
Neighbour-Driven Gaussian Process Variational Autoencoders for Scalable Structured Latent Modelling
May 22, 2025Gaussian Process (GP) Variational Autoencoders (VAEs) extend standard VAEs by replacing the fully factorised Gaussian prior with a GP prior, thereby capturing richer correlations among latent variables. However, performing exact GP inference in large-scale GPVAEs is computationally prohibitive, often forcing existing approaches to rely on restrictive kernel assumptions or large sets of inducing points. In this work, we propose a neighbour-driven approximation strategy that exploits local adjacencies in the latent space to achieve scalable GPVAE inference. By confining computations to the nearest neighbours of each data point, our method preserves essential latent dependencies, allowing more flexible kernel choices and mitigating the need for numerous inducing points. Through extensive experiments on tasks including representation learning, data imputation, and conditional generation, we demonstrate that our approach outperforms other GPVAE variants in both predictive performance and computational efficiency.
A Real-time and Hardware Efficient Artfecat-free Spike Sorting Using Deep Spike Detection
Apr 19, 2025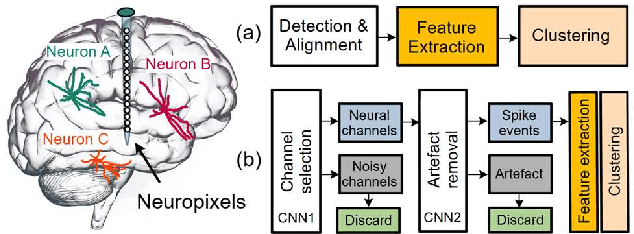
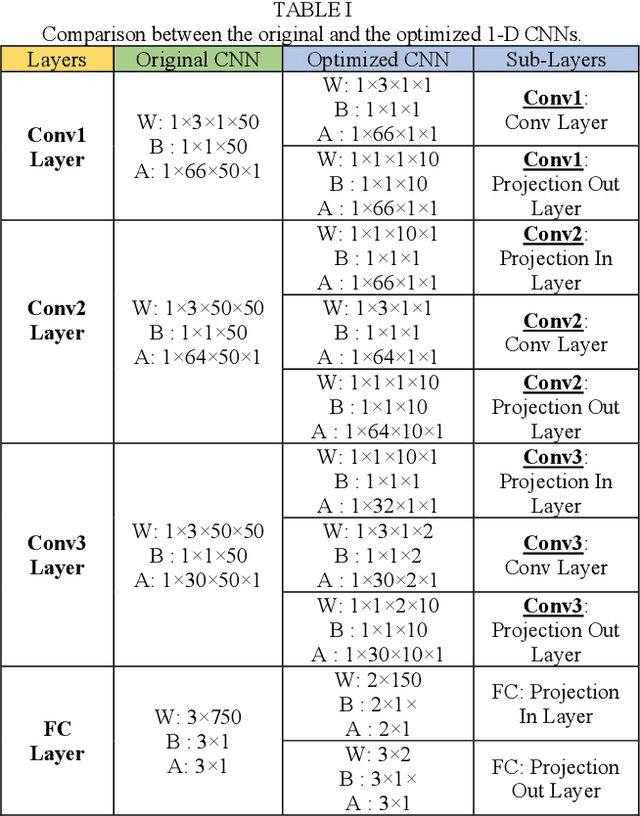


Spike sorting is a valuable tool in understanding brain regions. It assigns detected spike waveforms to their origins, helping to research the mechanism of the human brain and the development of implantable brain-machine interfaces (iBMIs). The presence of noise and artefacts will adversely affect the efficacy of spike sorting. This paper proposes a framework for low-cost and real-time implementation of deep spike detection, which consists of two one-dimensional (1-D) convolutional neural network (CNN) model for channel selection and artefact removal. The framework utilizes simulation and hardware layers, and it applies several low-power techniques to optimise the implementation cost of a 1-D CNN model. A compact CNN model with 210 bytes memory size is achieved using structured pruning, network projection and quantization in the simulation layer. The hardware layer also accommodates various techniques including a customized multiply-accumulate (MAC) engine, novel fused layers in the convolution pipeline and proposing flexible resource allocation for a power-efficient and low-delay design. The optimized 1-D CNN significantly decreases both computational complexity and model size, with only a minimal reduction in accuracy. Classification of 1-D CNN on the Cyclone V 5CSEMA5F31C6 FPGA evaluation platform is accomplished in just 16.8 microseconds at a frequency of 2.5 MHz. The FPGA prototype achieves an accuracy rate of 97.14% on a standard dataset and operates with a power consumption of 2.67mW from a supply voltage of 1.1 volts. An accuracy of 95.05% is achieved with a power of 5.6mW when deep spike detection is implemented using two optimized 1-D CNNs on an FPGA board.
"I know myself better, but not really greatly": Using LLMs to Detect and Explain LLM-Generated Texts
Feb 18, 2025Large language models (LLMs) have demonstrated impressive capabilities in generating human-like texts, but the potential misuse of such LLM-generated texts raises the need to distinguish between human-generated and LLM-generated content. This paper explores the detection and explanation capabilities of LLM-based detectors of LLM-generated texts, in the context of a binary classification task (human-generated texts vs LLM-generated texts) and a ternary classification task (human-generated texts, LLM-generated texts, and undecided). By evaluating on six close/open-source LLMs with different sizes, our findings reveal that while self-detection consistently outperforms cross-detection, i.e., LLMs can detect texts generated by themselves more accurately than those generated by other LLMs, the performance of self-detection is still far from ideal, indicating that further improvements are needed. We also show that extending the binary to the ternary classification task with a new class "Undecided" can enhance both detection accuracy and explanation quality, with improvements being statistically significant and consistent across all LLMs. We finally conducted comprehensive qualitative and quantitative analyses on the explanation errors, which are categorized into three types: reliance on inaccurate features (the most frequent error), hallucinations, and incorrect reasoning. These findings with our human-annotated dataset emphasize the need for further research into improving both self-detection and self-explanation, particularly to address overfitting issues that may hinder generalization.
DeepFilter: An Instrumental Baseline for Accurate and Efficient Process Monitoring
Jan 02, 2025



Effective process monitoring is increasingly vital in industrial automation for ensuring operational safety, necessitating both high accuracy and efficiency. Although Transformers have demonstrated success in various fields, their canonical form based on the self-attention mechanism is inadequate for process monitoring due to two primary limitations: (1) the step-wise correlations captured by self-attention mechanism are difficult to capture discriminative patterns in monitoring logs due to the lacking semantics of each step, thus compromising accuracy; (2) the quadratic computational complexity of self-attention hampers efficiency. To address these issues, we propose DeepFilter, a Transformer-style framework for process monitoring. The core innovation is an efficient filtering layer that excel capturing long-term and periodic patterns with reduced complexity. Equipping with the global filtering layer, DeepFilter enhances both accuracy and efficiency, meeting the stringent demands of process monitoring. Experimental results on real-world process monitoring datasets validate DeepFilter's superiority in terms of accuracy and efficiency compared to existing state-of-the-art models.
Scalable Multi-Output Gaussian Processes with Stochastic Variational Inference
Jul 02, 2024The Multi-Output Gaussian Process is is a popular tool for modelling data from multiple sources. A typical choice to build a covariance function for a MOGP is the Linear Model of Coregionalization (LMC) which parametrically models the covariance between outputs. The Latent Variable MOGP (LV-MOGP) generalises this idea by modelling the covariance between outputs using a kernel applied to latent variables, one per output, leading to a flexible MOGP model that allows efficient generalization to new outputs with few data points. Computational complexity in LV-MOGP grows linearly with the number of outputs, which makes it unsuitable for problems with a large number of outputs. In this paper, we propose a stochastic variational inference approach for the LV-MOGP that allows mini-batches for both inputs and outputs, making computational complexity per training iteration independent of the number of outputs.
Detecting Machine-Generated Texts: Not Just "AI vs Humans" and Explainability is Complicated
Jun 26, 2024



As LLMs rapidly advance, increasing concerns arise regarding risks about actual authorship of texts we see online and in real world. The task of distinguishing LLM-authored texts is complicated by the nuanced and overlapping behaviors of both machines and humans. In this paper, we challenge the current practice of considering LLM-generated text detection a binary classification task of differentiating human from AI. Instead, we introduce a novel ternary text classification scheme, adding an "undecided" category for texts that could be attributed to either source, and we show that this new category is crucial to understand how to make the detection result more explainable to lay users. This research shifts the paradigm from merely classifying to explaining machine-generated texts, emphasizing need for detectors to provide clear and understandable explanations to users. Our study involves creating four new datasets comprised of texts from various LLMs and human authors. Based on new datasets, we performed binary classification tests to ascertain the most effective SOTA detection methods and identified SOTA LLMs capable of producing harder-to-detect texts. We constructed a new dataset of texts generated by two top-performing LLMs and human authors, and asked three human annotators to produce ternary labels with explanation notes. This dataset was used to investigate how three top-performing SOTA detectors behave in new ternary classification context. Our results highlight why "undecided" category is much needed from the viewpoint of explainability. Additionally, we conducted an analysis of explainability of the three best-performing detectors and the explanation notes of the human annotators, revealing insights about the complexity of explainable detection of machine-generated texts. Finally, we propose guidelines for developing future detection systems with improved explanatory power.
Rethinking the Diffusion Models for Numerical Tabular Data Imputation from the Perspective of Wasserstein Gradient Flow
Jun 22, 2024



Diffusion models (DMs) have gained attention in Missing Data Imputation (MDI), but there remain two long-neglected issues to be addressed: (1). Inaccurate Imputation, which arises from inherently sample-diversification-pursuing generative process of DMs. (2). Difficult Training, which stems from intricate design required for the mask matrix in model training stage. To address these concerns within the realm of numerical tabular datasets, we introduce a novel principled approach termed Kernelized Negative Entropy-regularized Wasserstein gradient flow Imputation (KnewImp). Specifically, based on Wasserstein gradient flow (WGF) framework, we first prove that issue (1) stems from the cost functionals implicitly maximized in DM-based MDI are equivalent to the MDI's objective plus diversification-promoting non-negative terms. Based on this, we then design a novel cost functional with diversification-discouraging negative entropy and derive our KnewImp approach within WGF framework and reproducing kernel Hilbert space. After that, we prove that the imputation procedure of KnewImp can be derived from another cost functional related to the joint distribution, eliminating the need for the mask matrix and hence naturally addressing issue (2). Extensive experiments demonstrate that our proposed KnewImp approach significantly outperforms existing state-of-the-art methods.
Transcending Adversarial Perturbations: Manifold-Aided Adversarial Examples with Legitimate Semantics
Feb 05, 2024



Deep neural networks were significantly vulnerable to adversarial examples manipulated by malicious tiny perturbations. Although most conventional adversarial attacks ensured the visual imperceptibility between adversarial examples and corresponding raw images by minimizing their geometric distance, these constraints on geometric distance led to limited attack transferability, inferior visual quality, and human-imperceptible interpretability. In this paper, we proposed a supervised semantic-transformation generative model to generate adversarial examples with real and legitimate semantics, wherein an unrestricted adversarial manifold containing continuous semantic variations was constructed for the first time to realize a legitimate transition from non-adversarial examples to adversarial ones. Comprehensive experiments on MNIST and industrial defect datasets showed that our adversarial examples not only exhibited better visual quality but also achieved superior attack transferability and more effective explanations for model vulnerabilities, indicating their great potential as generic adversarial examples. The code and pre-trained models were available at https://github.com/shuaili1027/MAELS.git.