 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Improving Diffusion Models for Time-Series Data Imputation: A Proximal Recursion Perspective
Feb 01, 2026Diffusion models (DMs) have shown promise for Time-Series Data Imputation (TSDI); however, their performance remains inconsistent in complex scenarios. We attribute this to two primary obstacles: (1) non-stationary temporal dynamics, which can bias the inference trajectory and lead to outlier-sensitive imputations; and (2) objective inconsistency, since imputation favors accurate pointwise recovery whereas DMs are inherently trained to generate diverse samples. To better understand these issues, we analyze DM-based TSDI process through a proximal-operator perspective and uncover that an implicit Wasserstein distance regularization inherent in the process hinders the model's ability to counteract non-stationarity and dissipative regularizer, thereby amplifying diversity at the expense of fidelity. Building on this insight, we propose a novel framework called SPIRIT (Semi-Proximal Transport Regularized time-series Imputation). Specifically, we introduce entropy-induced Bregman divergence to relax the mass preserving constraint in the Wasserstein distance, formulate the semi-proximal transport (SPT) discrepancy, and theoretically prove the robustness of SPT against non-stationarity. Subsequently, we remove the dissipative structure and derive the complete SPIRIT workflow, with SPT serving as the proximal operator. Extensive experiments demonstrate the effectiveness of the proposed SPIRIT approach.
Deep Time-series Forecasting Needs Kernelized Moment Balancing
Jan 31, 2026Deep time-series forecasting can be formulated as a distribution balancing problem aimed at aligning the distribution of the forecasts and ground truths. According to Imbens' criterion, true distribution balance requires matching the first moments with respect to any balancing function. We demonstrate that existing objectives fail to meet this criterion, as they enforce moment matching only for one or two predefined balancing functions, thus failing to achieve full distribution balance. To address this limitation, we propose direct forecasting with kernelized moment balancing (KMB-DF). Unlike existing objectives, KMB-DF adaptively selects the most informative balancing functions from a reproducing kernel hilbert space (RKHS) to enforce sufficient distribution balancing. We derive a tractable and differentiable objective that enables efficient estimation from empirical samples and seamless integration into gradient-based training pipelines. Extensive experiments across multiple models and datasets show that KMB-DF consistently improves forecasting accuracy and achieves state-of-the-art performance. Code is available at https://anonymous.4open.science/r/KMB-DF-403C.
A Causal Perspective for Enhancing Jailbreak Attack and Defense
Jan 31, 2026Uncovering the mechanisms behind "jailbreaks" in large language models (LLMs) is crucial for enhancing their safety and reliability, yet these mechanisms remain poorly understood. Existing studies predominantly analyze jailbreak prompts by probing latent representations, often overlooking the causal relationships between interpretable prompt features and jailbreak occurrences. In this work, we propose Causal Analyst, a framework that integrates LLMs into data-driven causal discovery to identify the direct causes of jailbreaks and leverage them for both attack and defense. We introduce a comprehensive dataset comprising 35k jailbreak attempts across seven LLMs, systematically constructed from 100 attack templates and 50 harmful queries, annotated with 37 meticulously designed human-readable prompt features. By jointly training LLM-based prompt encoding and GNN-based causal graph learning, we reconstruct causal pathways linking prompt features to jailbreak responses. Our analysis reveals that specific features, such as "Positive Character" and "Number of Task Steps", act as direct causal drivers of jailbreaks. We demonstrate the practical utility of these insights through two applications: (1) a Jailbreaking Enhancer that targets identified causal features to significantly boost attack success rates on public benchmarks, and (2) a Guardrail Advisor that utilizes the learned causal graph to extract true malicious intent from obfuscated queries. Extensive experiments, including baseline comparisons and causal structure validation, confirm the robustness of our causal analysis and its superiority over non-causal approaches. Our results suggest that analyzing jailbreak features from a causal perspective is an effective and interpretable approach for improving LLM reliability. Our code is available at https://github.com/Master-PLC/Causal-Analyst.
TransDF: Time-Series Forecasting Needs Transformed Label Alignment
May 23, 2025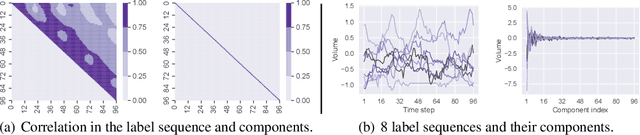
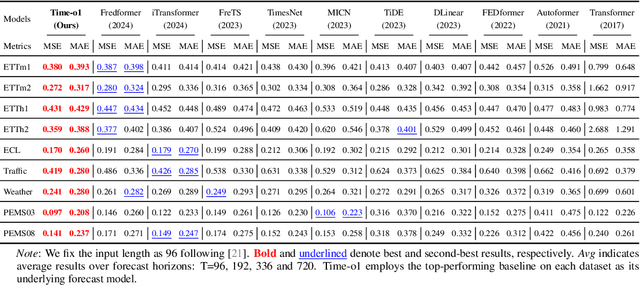
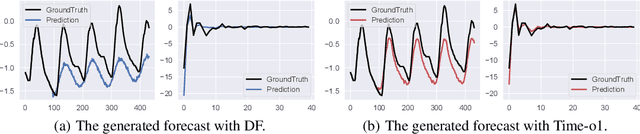
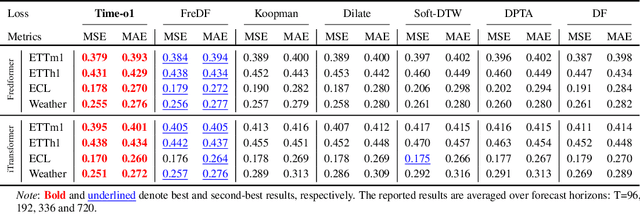
Training time-series forecasting models presents unique challenges in designing effective learning objectives. Existing methods predominantly utilize the temporal mean squared error, which faces two critical challenges: (1) label autocorrelation, which leads to bias from the label sequence likelihood; (2) excessive amount of tasks, which increases with the forecast horizon and complicates optimization. To address these challenges, we propose Transform-enhanced Direct Forecast (TransDF), which transforms the label sequence into decorrelated components with discriminated significance. Models are trained to align the most significant components, thereby effectively mitigating label autocorrelation and reducing task amount. Extensive experiments demonstrate that TransDF achieves state-of-the-art performance and is compatible with various forecasting models. Code is available at https://anonymous.4open.science/r/TransDF-88CF.
Understanding and Mitigating Overrefusal in LLMs from an Unveiling Perspective of Safety Decision Boundary
May 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet they often refuse to answer legitimate queries-a phenomenon known as overrefusal. Overrefusal typically stems from over-conservative safety alignment, causing models to treat many reasonable prompts as potentially risky. To systematically understand this issue, we probe and leverage the models'safety decision boundaries to analyze and mitigate overrefusal. Our findings reveal that overrefusal is closely tied to misalignment at these boundary regions, where models struggle to distinguish subtle differences between benign and harmful content. Building on these insights, we present RASS, an automated framework for prompt generation and selection that strategically targets overrefusal prompts near the safety boundary. By harnessing steering vectors in the representation space, RASS efficiently identifies and curates boundary-aligned prompts, enabling more effective and targeted mitigation of overrefusal. This approach not only provides a more precise and interpretable view of model safety decisions but also seamlessly extends to multilingual scenarios.We have explored the safety decision boundaries of various LLMs and construct the MORBench evaluation set to facilitate robust assessment of model safety and helpfulness across multiple languages. Code and datasets will be released at https://anonymous.4open.science/r/RASS-80D3.
Mixture of Low Rank Adaptation with Partial Parameter Sharing for Time Series Forecasting
May 23, 2025Multi-task forecasting has become the standard approach for time-series forecasting (TSF). However, we show that it suffers from an Expressiveness Bottleneck, where predictions at different time steps share the same representation, leading to unavoidable errors even with optimal representations. To address this issue, we propose a two-stage framework: first, pre-train a foundation model for one-step-ahead prediction; then, adapt it using step-specific LoRA modules.This design enables the foundation model to handle any number of forecast steps while avoiding the expressiveness bottleneck. We further introduce the Mixture-of-LoRA (MoLA) model, which employs adaptively weighted LoRA experts to achieve partial parameter sharing across steps. This approach enhances both efficiency and forecasting performance by exploiting interdependencies between forecast steps. Experiments show that MoLA significantly improves model expressiveness and outperforms state-of-the-art time-series forecasting methods. Code is available at https://anonymous.4open.science/r/MoLA-BC92.
DeepFilter: An Instrumental Baseline for Accurate and Efficient Process Monitoring
Jan 02, 2025



Effective process monitoring is increasingly vital in industrial automation for ensuring operational safety, necessitating both high accuracy and efficiency. Although Transformers have demonstrated success in various fields, their canonical form based on the self-attention mechanism is inadequate for process monitoring due to two primary limitations: (1) the step-wise correlations captured by self-attention mechanism are difficult to capture discriminative patterns in monitoring logs due to the lacking semantics of each step, thus compromising accuracy; (2) the quadratic computational complexity of self-attention hampers efficiency. To address these issues, we propose DeepFilter, a Transformer-style framework for process monitoring. The core innovation is an efficient filtering layer that excel capturing long-term and periodic patterns with reduced complexity. Equipping with the global filtering layer, DeepFilter enhances both accuracy and efficiency, meeting the stringent demands of process monitoring. Experimental results on real-world process monitoring datasets validate DeepFilter's superiority in terms of accuracy and efficiency compared to existing state-of-the-art models.
FreDF: Learning to Forecast in Frequency Domain
Feb 04, 2024Time series modeling is uniquely challenged by the presence of autocorrelation in both historical and label sequences. Current research predominantly focuses on handling autocorrelation within the historical sequence but often neglects its presence in the label sequence. Specifically, emerging forecast models mainly conform to the direct forecast (DF) paradigm, generating multi-step forecasts under the assumption of conditional independence within the label sequence. This assumption disregards the inherent autocorrelation in the label sequence, thereby limiting the performance of DF-based models. In response to this gap, we introduce the Frequency-enhanced Direct Forecast (FreDF), which bypasses the complexity of label autocorrelation by learning to forecast in the frequency domain. Our experiments demonstrate that FreDF substantially outperforms existing state-of-the-art methods including iTransformer and is compatible with a variety of forecast models.
Modeling Task Relationships in Multi-variate Soft Sensor with Balanced Mixture-of-Experts
May 25, 2023



Accurate estimation of multiple quality variables is critical for building industrial soft sensor models, which have long been confronted with data efficiency and negative transfer issues. Methods sharing backbone parameters among tasks address the data efficiency issue; however, they still fail to mitigate the negative transfer problem. To address this issue, a balanced Mixture-of-Experts (BMoE) is proposed in this work, which consists of a multi-gate mixture of experts (MMoE) module and a task gradient balancing (TGB) module. The MoE module aims to portray task relationships, while the TGB module balances the gradients among tasks dynamically. Both of them cooperate to mitigate the negative transfer problem. Experiments on the typical sulfur recovery unit demonstrate that BMoE models task relationship and balances the training process effectively, and achieves better performance than baseline models significantly.
TMoE-P: Towards the Pareto Optimum for Multivariate Soft Sensors
Feb 21, 2023



Multi-variate soft sensor seeks accurate estimation of multiple quality variables using measurable process variables, which have emerged as a key factor in improving the quality of industrial manufacturing. The current progress stays in some direct applications of multitask network architectures; however, there are two fundamental issues remain yet to be investigated with these approaches: (1) negative transfer, where sharing representations despite the difference of discriminate representations for different objectives degrades performance; (2) seesaw phenomenon, where the optimizer focuses on one dominant yet simple objective at the expense of others. In this study, we reformulate the multi-variate soft sensor to a multi-objective problem, to address both issues and advance state-of-the-art performance. To handle the negative transfer issue, we first propose an Objective-aware Mixture-of-Experts (OMoE) module, utilizing objective-specific and objective-shared experts for parameter sharing while maintaining the distinction between objectives. To address the seesaw phenomenon, we then propose a Pareto Objective Routing (POR) module, adjusting the weights of learning objectives dynamically to achieve the Pareto optimum, with solid theoretical supports. We further present a Task-aware Mixture-of-Experts framework for achieving the Pareto optimum (TMoE-P) in multi-variate soft sensor, which consists of a stacked OMoE module and a POR module. We illustrate the efficacy of TMoE-P with an open soft sensor benchmark, where TMoE-P effectively alleviates the negative transfer and seesaw issues and outperforms the baseline models.