 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Data-Centric to Sample-Centric: Enhancing LLM Reasoning via Progressive Optimization
Jul 09, 2025



Reinforcement learning with verifiable rewards (RLVR) has recently advanced the reasoning capabilities of large language models (LLMs). While prior work has emphasized algorithmic design, data curation, and reward shaping, we investigate RLVR from a sample-centric perspective and introduce LPPO (Learning-Progress and Prefix-guided Optimization), a framework of progressive optimization techniques. Our work addresses a critical question: how to best leverage a small set of trusted, high-quality demonstrations, rather than simply scaling up data volume. First, motivated by how hints aid human problem-solving, we propose prefix-guided sampling, an online data augmentation method that incorporates partial solution prefixes from expert demonstrations to guide the policy, particularly for challenging instances. Second, inspired by how humans focus on important questions aligned with their current capabilities, we introduce learning-progress weighting, a dynamic strategy that adjusts each training sample's influence based on model progression. We estimate sample-level learning progress via an exponential moving average of per-sample pass rates, promoting samples that foster learning and de-emphasizing stagnant ones. Experiments on mathematical-reasoning benchmarks demonstrate that our methods outperform strong baselines, yielding faster convergence and a higher performance ceiling.
DeepFilter: An Instrumental Baseline for Accurate and Efficient Process Monitoring
Jan 02, 2025



Effective process monitoring is increasingly vital in industrial automation for ensuring operational safety, necessitating both high accuracy and efficiency. Although Transformers have demonstrated success in various fields, their canonical form based on the self-attention mechanism is inadequate for process monitoring due to two primary limitations: (1) the step-wise correlations captured by self-attention mechanism are difficult to capture discriminative patterns in monitoring logs due to the lacking semantics of each step, thus compromising accuracy; (2) the quadratic computational complexity of self-attention hampers efficiency. To address these issues, we propose DeepFilter, a Transformer-style framework for process monitoring. The core innovation is an efficient filtering layer that excel capturing long-term and periodic patterns with reduced complexity. Equipping with the global filtering layer, DeepFilter enhances both accuracy and efficiency, meeting the stringent demands of process monitoring. Experimental results on real-world process monitoring datasets validate DeepFilter's superiority in terms of accuracy and efficiency compared to existing state-of-the-art models.
Proximity Matters: Local Proximity Preserved Balancing for Treatment Effect Estimation
Jul 01, 2024



Heterogeneous treatment effect (HTE) estimation from observational data poses significant challenges due to treatment selection bias. Existing methods address this bias by minimizing distribution discrepancies between treatment groups in latent space, focusing on global alignment. However, the fruitful aspect of local proximity, where similar units exhibit similar outcomes, is often overlooked. In this study, we propose Proximity-aware Counterfactual Regression (PCR) to exploit proximity for representation balancing within the HTE estimation context. Specifically, we introduce a local proximity preservation regularizer based on optimal transport to depict the local proximity in discrepancy calculation. Furthermore, to overcome the curse of dimensionality that renders the estimation of discrepancy ineffective, exacerbated by limited data availability for HTE estimation, we develop an informative subspace projector, which trades off minimal distance precision for improved sample complexity. Extensive experiments demonstrate that PCR accurately matches units across different treatment groups, effectively mitigates treatment selection bias, and significantly outperforms competitors. Code is available at https://anonymous.4open.science/status/ncr-B697.
FreDF: Learning to Forecast in Frequency Domain
Feb 04, 2024Time series modeling is uniquely challenged by the presence of autocorrelation in both historical and label sequences. Current research predominantly focuses on handling autocorrelation within the historical sequence but often neglects its presence in the label sequence. Specifically, emerging forecast models mainly conform to the direct forecast (DF) paradigm, generating multi-step forecasts under the assumption of conditional independence within the label sequence. This assumption disregards the inherent autocorrelation in the label sequence, thereby limiting the performance of DF-based models. In response to this gap, we introduce the Frequency-enhanced Direct Forecast (FreDF), which bypasses the complexity of label autocorrelation by learning to forecast in the frequency domain. Our experiments demonstrate that FreDF substantially outperforms existing state-of-the-art methods including iTransformer and is compatible with a variety of forecast models.
Modeling Task Relationships in Multi-variate Soft Sensor with Balanced Mixture-of-Experts
May 25, 2023



Accurate estimation of multiple quality variables is critical for building industrial soft sensor models, which have long been confronted with data efficiency and negative transfer issues. Methods sharing backbone parameters among tasks address the data efficiency issue; however, they still fail to mitigate the negative transfer problem. To address this issue, a balanced Mixture-of-Experts (BMoE) is proposed in this work, which consists of a multi-gate mixture of experts (MMoE) module and a task gradient balancing (TGB) module. The MoE module aims to portray task relationships, while the TGB module balances the gradients among tasks dynamically. Both of them cooperate to mitigate the negative transfer problem. Experiments on the typical sulfur recovery unit demonstrate that BMoE models task relationship and balances the training process effectively, and achieves better performance than baseline models significantly.
TMoE-P: Towards the Pareto Optimum for Multivariate Soft Sensors
Feb 21, 2023



Multi-variate soft sensor seeks accurate estimation of multiple quality variables using measurable process variables, which have emerged as a key factor in improving the quality of industrial manufacturing. The current progress stays in some direct applications of multitask network architectures; however, there are two fundamental issues remain yet to be investigated with these approaches: (1) negative transfer, where sharing representations despite the difference of discriminate representations for different objectives degrades performance; (2) seesaw phenomenon, where the optimizer focuses on one dominant yet simple objective at the expense of others. In this study, we reformulate the multi-variate soft sensor to a multi-objective problem, to address both issues and advance state-of-the-art performance. To handle the negative transfer issue, we first propose an Objective-aware Mixture-of-Experts (OMoE) module, utilizing objective-specific and objective-shared experts for parameter sharing while maintaining the distinction between objectives. To address the seesaw phenomenon, we then propose a Pareto Objective Routing (POR) module, adjusting the weights of learning objectives dynamically to achieve the Pareto optimum, with solid theoretical supports. We further present a Task-aware Mixture-of-Experts framework for achieving the Pareto optimum (TMoE-P) in multi-variate soft sensor, which consists of a stacked OMoE module and a POR module. We illustrate the efficacy of TMoE-P with an open soft sensor benchmark, where TMoE-P effectively alleviates the negative transfer and seesaw issues and outperforms the baseline models.
AttentionMixer: An Accurate and Interpretable Framework for Process Monitoring
Feb 21, 2023



An accurate and explainable automatic monitoring system is critical for the safety of high efficiency energy conversion plants that operate under extreme working condition. Nonetheless, currently available data-driven monitoring systems often fall short in meeting the requirements for either high-accuracy or interpretability, which hinders their application in practice. To overcome this limitation, a data-driven approach, AttentionMixer, is proposed under a generalized message passing framework, with the goal of establishing an accurate and interpretable radiation monitoring framework for energy conversion plants. To improve the model accuracy, the first technical contribution involves the development of spatial and temporal adaptive message passing blocks, which enable the capture of spatial and temporal correlations, respectively; the two blocks are cascaded through a mixing operator. To enhance the model interpretability, the second technical contribution involves the implementation of a sparse message passing regularizer, which eliminates spurious and noisy message passing routes. The effectiveness of the AttentionMixer approach is validated through extensive evaluations on a monitoring benchmark collected from the national radiation monitoring network for nuclear power plants, resulting in enhanced monitoring accuracy and interpretability in practice.
An empirical evaluation of attention-based multi-head models for improved turbofan engine remaining useful life prediction
Sep 17, 2021
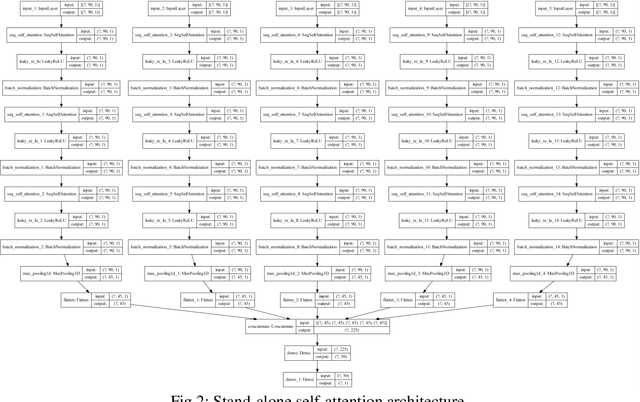


A single unit (head) is the conventional input feature extractor in deep learning architectures trained on multivariate time series signals. The importance of the fixed-dimensional vector representation generated by the single-head network has been demonstrated for industrial machinery condition monitoring and predictive maintenance. However, processing heterogeneous sensor signals with a single-head may result in a model that cannot explicitly account for the diversity in time-varying multivariate inputs. This work extends the conventional single-head deep learning models to a more robust form by developing context-specific heads to independently capture the inherent pattern in each sensor reading. Using the turbofan aircraft engine benchmark dataset (CMAPSS), an extensive experiment is performed to verify the effectiveness and benefits of multi-head multilayer perceptron, recurrent networks, convolution network, the transformer-style stand-alone attention network, and their variants for remaining useful life estimation. Moreover, the effect of different attention mechanisms on the multi-head models is also evaluated. In addition, each architecture's relative advantage and computational overhead are analyzed. Results show that utilizing the attention layer is task-sensitive and model dependent, as it does not provide consistent improvement across the models investigated. The best model is further compared with five state-of-the-art models, and the comparison shows that a relatively simple multi-head architecture performs better than the state-of-the-art models. The results presented in this study demonstrate the importance of multi-head models and attention mechanisms to an improved understanding of the remaining useful life of industrial assets.
Analyze and Design Network Architectures by Recursion Formulas
Aug 18, 2021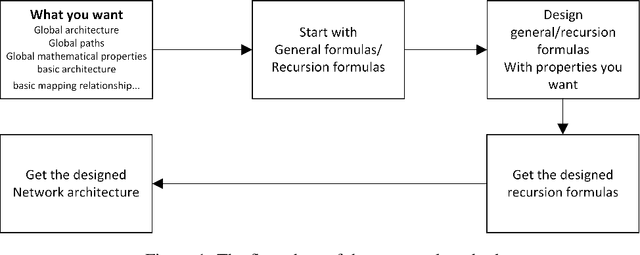
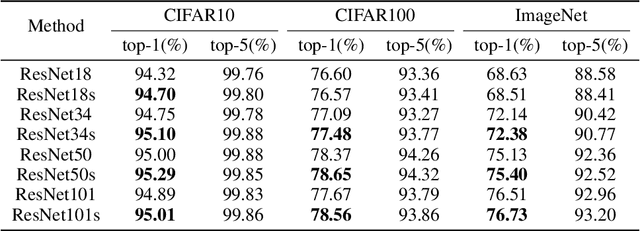
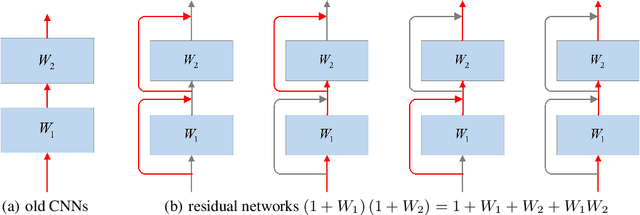
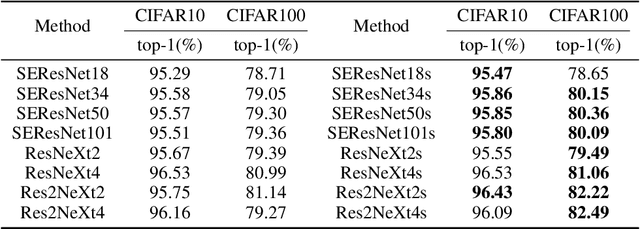
The effectiveness of shortcut/skip-connection has been widely verified, which inspires massive explorations on neural architecture design. This work attempts to find an effective way to design new network architectures. It is discovered that the main difference between network architectures can be reflected in their recursion formulas. Based on this, a methodology is proposed to design novel network architectures from the perspective of mathematical formulas. Afterwards, a case study is provided to generate an improved architecture based on ResNet. Furthermore, the new architecture is compared with ResNet and then tested on ResNet-based networks. Massive experiments are conducted on CIFAR and ImageNet, which witnesses the significant performance improvements provided by the architecture.