 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical evaluation of attention-based multi-head models for improved turbofan engine remaining useful life prediction
Sep 17, 2021
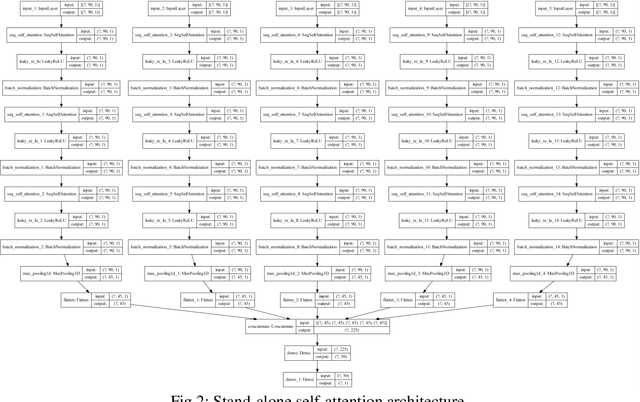


A single unit (head) is the conventional input feature extractor in deep learning architectures trained on multivariate time series signals. The importance of the fixed-dimensional vector representation generated by the single-head network has been demonstrated for industrial machinery condition monitoring and predictive maintenance. However, processing heterogeneous sensor signals with a single-head may result in a model that cannot explicitly account for the diversity in time-varying multivariate inputs. This work extends the conventional single-head deep learning models to a more robust form by developing context-specific heads to independently capture the inherent pattern in each sensor reading. Using the turbofan aircraft engine benchmark dataset (CMAPSS), an extensive experiment is performed to verify the effectiveness and benefits of multi-head multilayer perceptron, recurrent networks, convolution network, the transformer-style stand-alone attention network, and their variants for remaining useful life estimation. Moreover, the effect of different attention mechanisms on the multi-head models is also evaluated. In addition, each architecture's relative advantage and computational overhead are analyzed. Results show that utilizing the attention layer is task-sensitive and model dependent, as it does not provide consistent improvement across the models investigated. The best model is further compared with five state-of-the-art models, and the comparison shows that a relatively simple multi-head architecture performs better than the state-of-the-art models. The results presented in this study demonstrate the importance of multi-head models and attention mechanisms to an improved understanding of the remaining useful life of industrial assets.